如果觉得文章写得好,想要博客文章中的数据,请关注公众号:【Z先生点记】,已经为你准备了 50本+ Python 电子书籍 与 200G + 优质视频资料,后台回复关键字:1024 即可获取;添加作者【个人微信】,可与作者直接进行交流,
文字 OCR 识别技术现在已经相当成熟了,无论 其 准确度还是识别速度 都能够满足我们的日常需要;今天给大家介绍一个 Python 包,该包的主要功能就是用于 OCR 识别的,包的名字叫 Pyteeseract,借助这个包几行代码就能快速识别一张文本图片

Pytesseract 包是由 开源工具 Tesseract 得到的,由 Hewlett Packard 实验室开发,在 2005 年实行开源;自2006 年之后由谷歌和一些优秀的开源贡献者共同开发维护
Tesseract 在 3.x 版本之后逐渐成熟,支持多种图片格式并且逐步加入多语言文本识别;但 Tesseract 3.x 版本依旧 基于传统计算机视觉算法,在过去的几年得益于 Deep Learning 的快速迭代,无论是准确率与速度方面都要优于传统算法;在 4.0 版本之后 Tesseract 加入了 Deep Learning 模块, 是基于 Recognition 的 LSTM,而 LSTM 就是可归类为 RNN(循环卷积神经网络);
本篇文章的实验是基于 Tesseract3.05 版本实现的,最后在中文语言识别方面准确率稍次,可能是因为没有使用4.0+的原因在,后来才了解已经有 4.0+ 版本甚至 5.0+ (但不太稳定)且都是基于 Deep Learning 模块的,但因为太懒就不想改了,,,
先交代一下实验环境:
-
os: Win10;
-
Python 3.8;
-
pyteeseract 0.3.8;
-
Tesseract 3.05;
pyteeseract 安装
1,安装 tesseract 工具
相对其它程序包,pyteeseract 的安装步骤会相对繁琐一点,因为 pyteeseract 识别功能是基于 tesseract 开源工具完成的,所以第一步 安装 tesseract ,安装包下载链接:
https://digi.bib.uni-mannheim.de/tesseract/
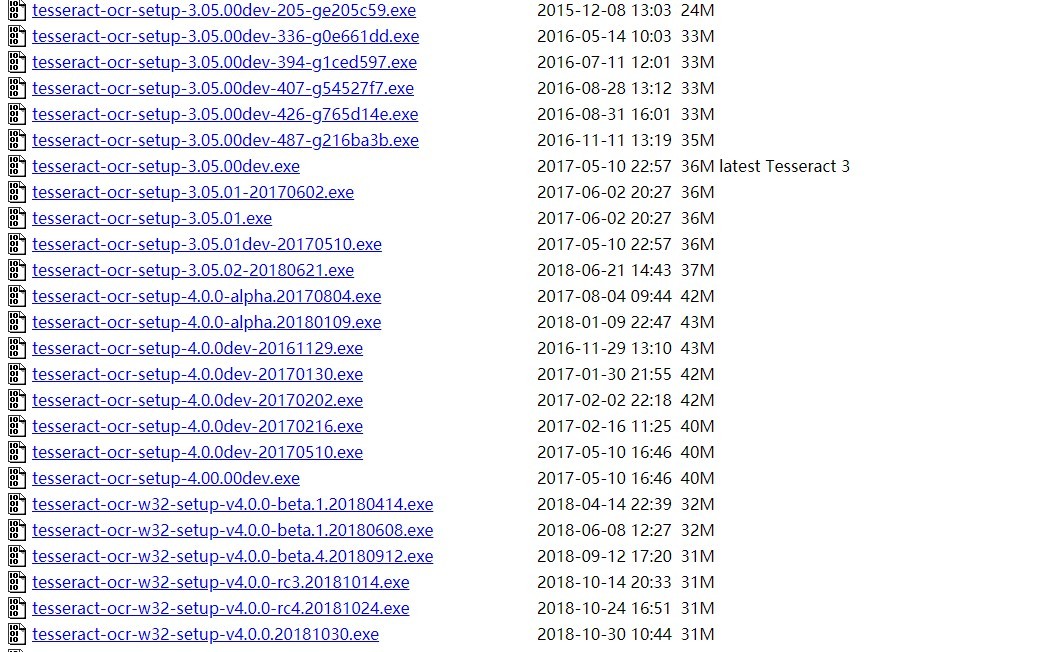
提供有 3.0+,4.0+及5.0+版本使用,下载完之后安装(安装方式就是傻瓜式安装)
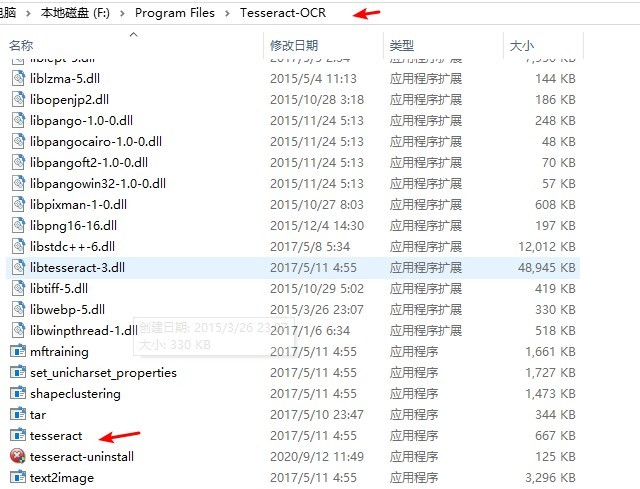
tesseract 安装成功之后,需把存放 tesseract.exe 的文件路径加入到环境变量中,如下图我的 tesseract.exe 存放的文件夹就是 F:/Program Files/Tesseract-OCR 加入环境变量即可;
2,pip install pytesseract
在命令行中,用 pip 工具下载 pytesseract 包
pip install pyteeseract
3,修改pytesseract.py 脚本
在 步骤 2 的基础之上,找到 pytesseract 的安装路径,如果 Python 是通过 Anaconda 安装的话的话,安装路径一般都在 Anaconda/Lib/site-packages 文件夹下;找到之后找 pytesseract 文件夹下的 pytesseract.py 脚本文件,
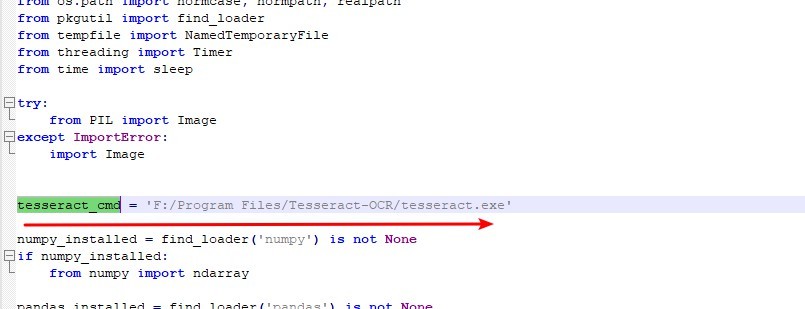
找到之后,用记事本打开 pyresseract.py,通过 ctrl +f 快速搜索功能定位 tesseract_cmd ,修改后面的文件路径信息(用上面提到的 tesseract.exe 安装路径进行替换即可);
2, pytesseract 使用
程序包的用法也相对比较简单,几行代码就能搞定,下面代码就是把一张图片中的文字识别,并转化为 字符串打印出来,选择识别语言 英语( 更改 lang = ‘eng’ 参数即可)
import pytesseract
import cv2
img_path = "G:/Coding/One_hundred_days/Data/orc_image2.jpg"
# 下面一行代码很重要
tessdata_dir_config = '--tessdata-dir "F://Program Files//Tesseract-OCR//tessdata"'
im = cv2.imread(img_path)
img = cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(img,lang= 'eng',config= tessdata_dir_config,)
print(text)
效果预览,识别前

识别后
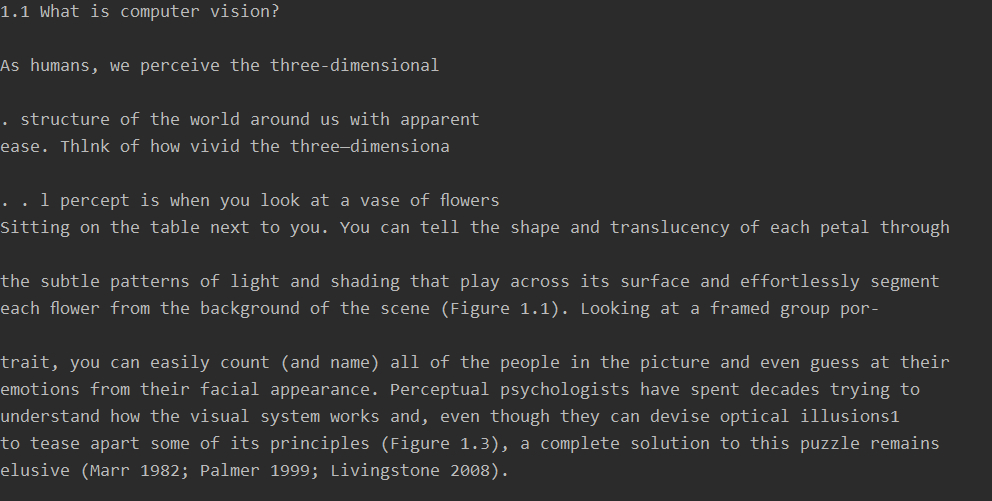
pytesseract 支持将 OpenCV 和 PIL 读取后的图像作为输入,但图像格式需为 RGB 模式,因此 OpenCV 读取之后还要加入一行代码把图像的 BGR 模式转化为 RGB
另外需要注意一点 ,上面实例中下面这一行代码不能去掉(用于后面 image_to_string() 函数中的 config 参数的设置)
tessdata_dir_config = '--tessdata-dir "F://Program Files//Tesseract-OCR//tessdata"'
否则会报下面的错误,tessdata 文件路径定位失败 ,
Failed loading language ‘eng’ Tesseract couldn’t load any languages! Could not initialize tesseract.’)
tessdata 文件路径存放的是语言包文件,是用于 识别图像中不同语言,通过修改 lang 参数来进行设定;但需要知道的是,tesseract 工具起初默认语言为 eng(英文),若需要借助 tesseract 识别不同语种需要下载对应的 语言包文件,安装到 tessdata 文件夹下即可
例如上面案例中我用的是 英语,这里我想识别图片中的中文字符,就需要把中文语言包下载 到 testdata 中,各语言包的下载地址,https://github.com/tesseract-ocr/tessdata
再把代码中 image_to_string() 中 lang 参数设为 chi_sim 即可
效果预览,识别前

识别后,对于中文来说识别效果并不是太好,猜测可是是版本的原因:

pyteeseract 其他用法
1,除了上面可以直接把图像中内容识别转化为字符串之外,还可直接转化 pdf 文件形式导出
# Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f:
f.write(pdf) # pdf type is bytes by default
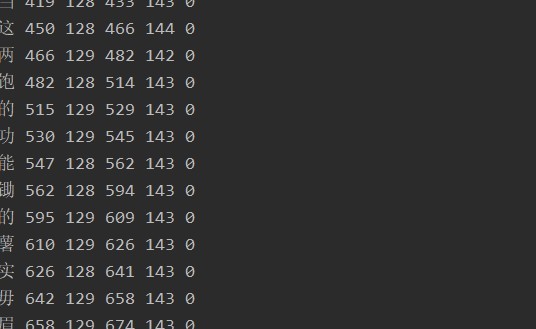
2,估计识别出来每个字符的边框信息,图片中的位置分辨率范围:
print(pytesseract.image_to_boxes(img_path,lang = 'chi_sim',config= tessdata_dir_config))
3,关于 pyteeseract 还有很多用法还未介绍,有兴趣的小伙伴可去官网介绍进行了解,链接如下:
https://pypi.org/project/pytesseract/