简介:
- 机器学习专门研究计算机怎样模拟或实现人类的学习行为,使之不断改善自身性能。是一门能够发掘数据价值的算法和应用,它是计算机科学中最激动人心的领域。
- 机器学习目的: 通过自学习算法从数据中获取知识,进而对未来进行预测。
- 机器学习应用: 语音识别 无人驾驶 垃圾邮件过滤
1. 基于规则学习和基于模型的学习
-
基于规则的学习
没有机器学习之前 垃圾邮箱的过滤

但是基于规则的学习有一定的缺点:- 规则是可以改变的
- 无法避免人为因素带来对结果的影响
-
基于模型的学习


- 机器学习学习什么? 机器学习是基于模型的学习,通过模型中的参数(y=kx + b为例),确定了k和b就知道了结果.
机器学习模型=数据 + 机器学习算法
- 对于不是机器学习问题:
- 1-确定的问题
- 2-统计的问题
- 对于机器学习来讲,通过历史数据结合算法,给出预测模型或规律进行预测分析
- 1-推荐场景
- 2-Facebook人物标记
- 3-预测场景
2. 机器学习数据集的基本概念:

- 鸢尾花Iris Dataset数据集是机器学习领域经典数据集

在鸢尾花中花数据集中,包含150个样本和4个特征,因此将其记作150x4维的矩阵.
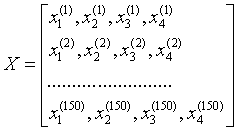
一般小写字母代表向量,大写字母代表矩阵。
3.机器学习的分类
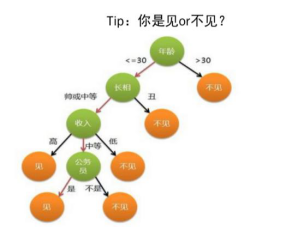
- 有监督学习: 带有标签列的学习, 给机器一大堆标记好的数据,让机器自己学习归纳.
- 分类问题对离散值进行预测

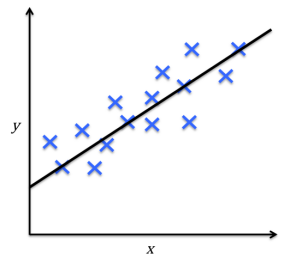
2)回归问题对连续值进行预测
- 无监督学习:
聚类是一种探索性数据分析技术,在没有任何相关先验信息的情况下(相当于不清楚数据的信息),它可以帮助我们将数据划分为有意义的小的组别(也叫簇cluster)。其中每个簇内部成员之间有一定的相似度,簇之间有较大的不同。这也正是聚类作为无监督学习的原因。
- 聚类: 物以类聚, 降相似度高的 或者 相同的聚在一起

- 数据压缩中的降维
面对的数据都是高维的,这就对有限的数据存储空间以及机器学习算法性能提出了挑战.

-
半监督学习: 一部分数据有标签,一部分数据没有标签

-
缺点:引入了专家知识,需要规避因为专家带来的影响
-
基于聚类的假设:
- 首先数据集是一部分有标签一部分是没有标签,通过将有标签的数据结合没有标签的数据进行聚类。将相似度高的样本聚集在同一个组中,相异性较高的样本分在不同的组里面
- 对于聚类之后的结果,在同一个组里面既有没有标记的样本也有具有标记的样本,就可以获取已经有标记的样本数据,通过样本的类别值少数服从多数的原则进行选举,将选举的类别值给没有标记的样本加上样本的标记,通过该方法就可以让没有标记的样本全部加上标记,从而实现转化为监督学习。
-
强化学习: 强化学习(Reinforcement Learning)是机器学习的一个重要分支,主要用来解决连续决策的问题
- 无人驾驶
2)alphaGo下棋
拓展:
除了上述学习方式,还有深度学习、迁移学习等学习方式,一般深度学习提取特征、强化学习解决连续决策,迁移学习解决模型适应性问题。
机器学习分类总结:
