1. 理解机器学习的3大要素
- 机器学习=模型+策略(检查模型的好坏)+算法
模型:规律y=ax+b
策略:什么样的模型是好的模型?损失函数
算法:如何高效找到最优参数,模型中的参数a和b
1.1 模型
-
机器学习中,首先要考虑学习什么样的模型,在监督学习中,如模型y=kx+b就是所要学习的内容。
-
模型分类
- 决策函数: 仅仅给出属于一个类别的值----决策树
- 条件概率分布函数: 不仅仅给出类别的值,还需要给出概率—LR算法

1.2 策略
评价模型的好坏,使用损失函数进行度量,模型给出的值与实际真实值存在的差别。
损失函数度量模型一次预测的好坏,常用的损失函数有:
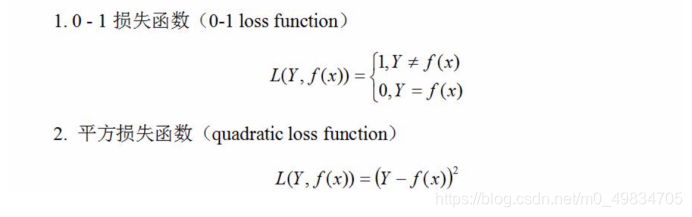

损失函数的值越小,模型就越好.
1.3 算法
机器学习的算法就是求解最优化问题的算法
2. 如何构建机器学习系统
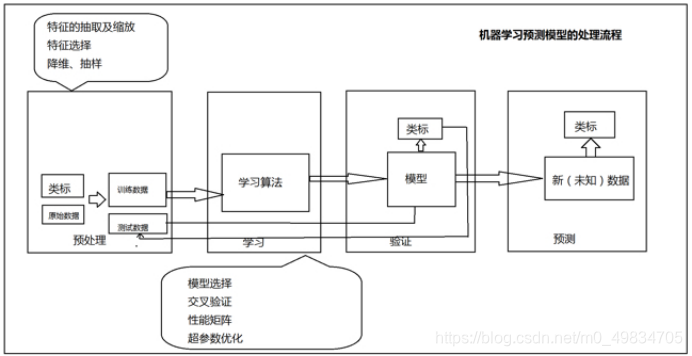
- 1-准备数据
- 2-特征工程
- 1-对数据进行处理
- 样本数据抽样—row
- 2-对特征进行处理
- 特征选择
- 特征降维
- 特征抽样
- 1-对数据进行处理
- 3-训练模型
- 数据+机器学习算法
- 参数:机器学习学习的就是模型,实质上学习的是模型中对应的参数
- 超参数:在机器学习模型训练之前事先指定的参数,称之为超参数,如迭代次数alpha
- y=kx+b 指定迭代次数alpha=20 k=5,b=3 y=5x+3 y=4x+6
- 4-选择最佳模型
- 模型不仅对于训练集效果好,对于测试效果很好==>模型泛化性能好
- 5-对新数据进行预测
- 模型已经训练好了,能够达到要求
3. 模型选择
- 基础概念
1) 泛化: 模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效果很好,对于新数据的适应能力也有很好的效果。
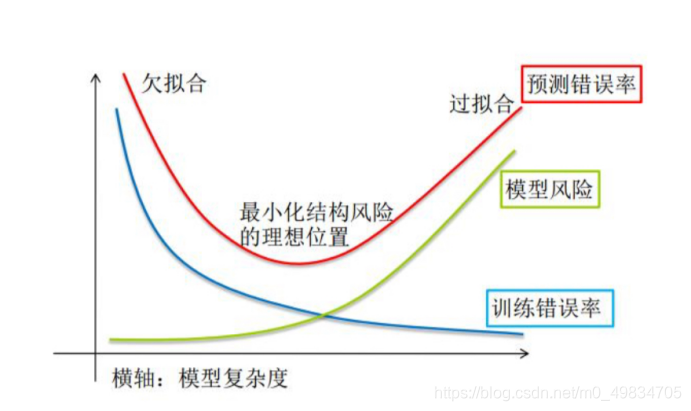
当我们讨论一个机器学习模型学习能力和泛化能力的好坏时,我们通常使用过拟合和欠拟合的概念,过拟合和欠拟合也是机器学习算法表现差的两大原因。
2) 过拟合overfitting:模型在训练数据上表现良好,在未知数据或者测试集上表现差。
3) 欠拟合underfitting:在训练数据和未知数据上表现都很差。
举例子:那一条曲线的拟合效果最好
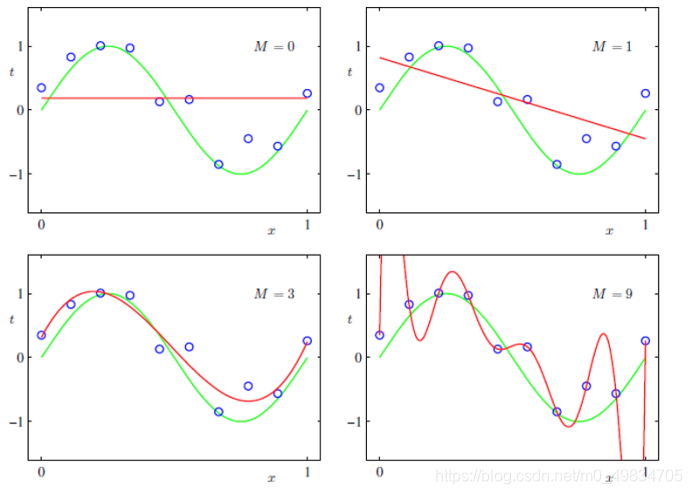
第一个图像和第二个图像是欠拟合的图像
- 欠拟合的现象
- 模型在训练数据集和测试数据集的效果都很差
- 欠拟合的发生的时间:
- 模型训练的初期
- 欠拟合发生的原因?
- 模型太过于简单
- y=t 或 y=-2x+3
- 模型太过于简单
- 如何解决欠拟合的问题?
- 增加多项式的特征
- 预测房价—面积,增加位置+房屋数量等
- y=k1x1+b===》y=k1xk2x2+b1
- 增加多项式的项的次数
- y=k1x1+b==》y=k1*x1**2+k2*xb
- 减少正则罚项
- 增加多项式的特征
第四个图像是过拟合的图像
- 过拟合的现象
- 模型在训练集上的效果很好,但是对于新数据或测试数据效果很差
- 过拟合的发生时期:
- 模型训练的中后期
- 过拟合的发生的原因:
- 模型太过于复杂+训练数据量太少+数据不纯
- 过拟合的解决办法:
- 1-增加正则罚项===>模型太过于复杂
- 2-重新采样训练数据
- 3-重新清洗数据
- 4-dropout方法–随机丢弃一些样本数据
选择一个好的模型要泛化性能好,避免欠拟合和过拟合.
遵循奥卡姆剃刀原则: 在具备相同或相似泛化能力的基础上,优先选择较为简单的模型. 本质就是: 防止模型过拟合
3.1 经验风险和结构风险
模型f(x)关于训练数据集的平均损失称之为经验风险(emprical risk)或经验损失(empirical loss),记作R(emp)
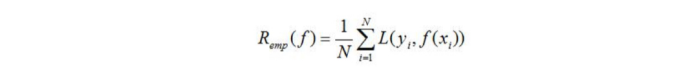
监督学习的两个基本策略:经验风险最小化和结构风险最小化。
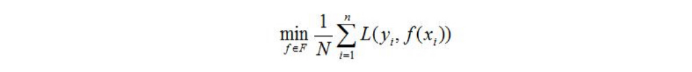
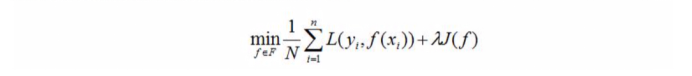
3.2 模型评估和模型选择
当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差就自然成为了学习方法评估的标准。

3.3 正则化
模型选择的典型方法是正则化,正则化一般形式如下:

经验风险较小的模型可能较复杂,这时正则化项的值会较大,正则化的作用是选择经验风险与模型复杂度同时较小的模型。
正则化项符合奥卡姆剃刀原理,在所有的可能的模型中,能够很好的解析已知数据并且十分简单的模型才是最好的模型,从贝叶斯估计的角度来看,正则化项对应于模型的先验概率,可以假设复杂的模型有较小的先验概率,简单的模型有较大的先验概率。
4. 拓展 常见的机器学习库
借助于近些年发展起来诸多强大的开源库,我们现在是进入机器学习领域的最佳时机。使用成熟的机器学习库帮我完成做好的算法,我们只需要了解清楚各个模型的参数如何调整就能够将模型应用于实际的业务场景。
- 基于Python的Sklearn库
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在NumPy,SciPy和matplotlib上
- 开源,可商业使用-获取BSD许可证

- 基于Scala的SparkMLLIB
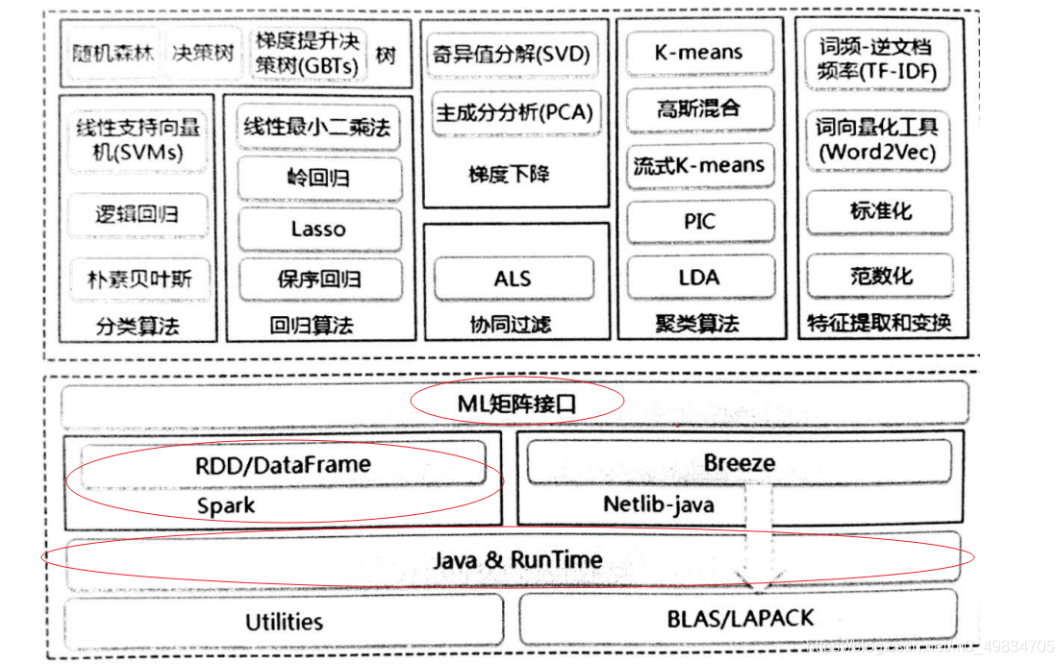
现在学习机器学习我们只需要使用已经现有的算法库,而将更多的经历放在对数据的认知、处理、整合上面.