TFIDF
-
TF
Term Frequency,即词频,它表示一个词在文档中出现的次数。计算公式:
某个词出现越多,表示它约重要。
某个词越少见,就越能表达一篇文章的特性,反之则越不能。 -
IDF
Inverse Document Frequency,即逆文档频率,它是一个表达词语重要性的指标。
计算公式:
如果所有文章都包涵某个词,该词的 ,即重要性为零。停用词的IDF约等于0。
如果某个词只在很少的文章中出现,则IDF很大,其重要性也越高。
-
TF-IDF
扫描二维码关注公众号,回复: 11554294 查看本文章
计算公式:
-
如果某个词在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词具有很好的类别区分能力
LDA
-
LDA定义
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。
文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。
-
LDA生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程:
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。 -
LDA整体流程
定义:文档集合D,主题(topic)集合T
D中每个文档d看作一个单词序列 ,wi表示第i个单词,设d有n个单词。
D中涉及的所有不同单词组成一个大集合VOCABULARY(简称VOC),LDA以文档集合D作为输入,希望训练出的两个结果向量(设聚成k个topic,VOC中共包含m个词):
对每个D中的文档d,对应到不同Topic的概率 ,其中, 表示d对应T中第 个topic的概率。计算方法: ,其中 表示d中对应第i个topic的词的数目,n是d中所有词的总数。
对每个T中的topic t,生成不同单词的概率 ,其中, 表示t生成VOC中第i个单词的概率。计算方法同样很直观, ,其中 表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。LDA的核心公式如下:
直观的看这个公式,就是以Topic作为中间层,可以通过当前的 和 给出了文档d中出现单词w的概率。其中 利用 计算得到, 利用 计算得到。
实际上,利用当前的 和 ,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的 ,然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响 和 。
LSA
-
定义
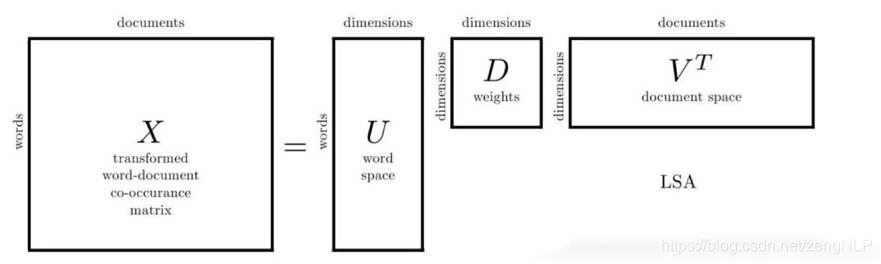
LSA(latent semantic analysis)潜在语义分析也可以称为 LSI(latent semantic index)。使用向量来表示词(iterms)和文档(documents),并通过向量间的关系来表示词和文档之间的相似度。
LSA 的核心思想是将词和文档映射到潜在语义空间,再比较其相似性。
-
解释
矩阵U :每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。矩阵V :每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。
矩阵D: 则表示类词和文章类之间的相关性。
我们只要对关联矩阵X 进行一次奇异值分解(SVD),我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)
-
-
实例

图中一共有10篇文章,选择代表词11个,矩阵中的数字代表横坐标中的词对应的纵坐标中的文章中出现的词频,对这个矩阵进行SVD分解: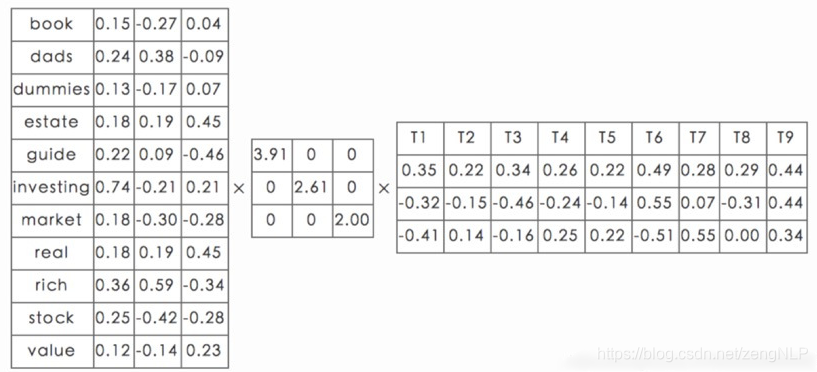
-
LSA的优点
1)低维空间表示可以刻画同义词,同义词会对应着相同或相似的主题。
2)降维可去除部分噪声,使特征更鲁棒。
3)充分利用冗余数据。
4)无监督。
5)与语言无关。 -
LSA的缺点
1)LSA可以解决一义多词问题
2)SVD的优化目标基于L-2 norm 或者 Frobenius Norm 的,这相当于隐含了对数据的高斯分布假设。而 term 出现的次数是非负的,这明显不符合 Gaussian 假设,而更接近 Multi-nomial 分布。
3)特征向量的方向没有对应的物理解释。
4)SVD的计算复杂度很高,而且当有新的文档来到时,若要更新模型需重新训练。
5)没有刻画term出现次数的概率模型。
6)对于count vectors 而言,欧式距离表达是不合适的。