探讨SparkSreaming之前,先要了解什么是批处理,什么是流处理.
- 批处理: 也叫离线处理T+1的模式,以Hive + Spark为主
- 流处理: 水流 也叫实时处理, SparkStreaming(秒级别,微批次处理) + StructeStreaming(毫秒级别) + Flink(毫秒级别)
- 流试计算: 对无边界的数据进行连续不断的处理、聚合和分析。
SparkStreaming介绍:
-
类似于Apache Storm,用于流式数据的处理. 具有高吞吐,容错能力强等特点.
-
支持多种数据源,例如: Kafka、Flume、Twitter、ZeroMQ 结果输出也能保存到很多地方 例如: HDFS MySQL
-
Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。

-
目前的版本的SparkStreaming,最小的Batch Size的选取在0.5~5秒钟之间
,能满足流式准实时计算, 对实时性要求非常高的如高频实时交易场景则不太适合。 -
Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
-
Spark生态系统当中一个重要的框架,建立在SparkCore之上

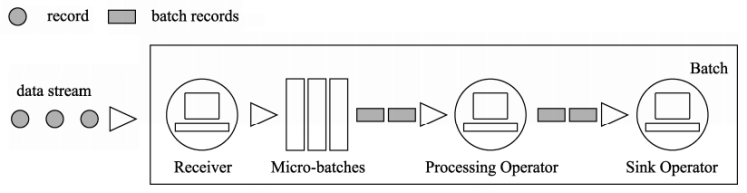
- 将流式数据按照时间间隔BatchInterval划分为很多部分,每一部分Batch(批次),针对每批次数据Batch当做RDD进行快速分析和处理
Streaming的计算模式
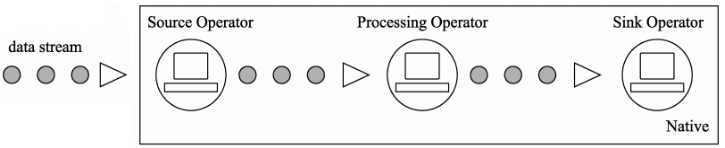
流式处理任务是大数据处理中很重要的一个分支, 不同的流处理框架有着不同的计算方式,主要分为两种:
- 原生流处理(Native): 以Flink和Storm为例,所有输入记录会一条接一条地被处理
- 微批处理(Batch): Spark Streaming 和 StructuredStreaming为例: 将输入的数据以某一时间间隔 T,切分成多个微批量数据,然后对每个批量数据进行处理