SparkStreaming基本使用与Window简单的介绍
1. SparkStreaming基本使用
1.1 pom.xml的依赖
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
1.2 入门级示例
- reduceByKey
object SparkStreaming1 {
// 过滤输出的log日志
Logger.getLogger("org").setLevel(Level.ERROR)
/**
* updateStateByKey方法所需要的函数,计算每个时间间隔的累计结果
*/
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
// 将值相加求和
val newCount = newValues.sum + runningCount.getOrElse(0)
Some(newCount)
}
def main(args: Array[String]): Unit = {
// master 需要 2 cores 防止饥饿场景
val conf = new SparkConf().setAppName("SparkStreaming1").setMaster("local[2]")
// 设置时间间隔为5秒,5秒钟的数据作为一个单元,给DStream进行处理
val streamingContext = new StreamingContext(conf, Seconds(5))
// 设置checkpoint的路径
streamingContext.checkpoint("./checkpoint")
// 设置 socket 机器 host + port , 返回的是5秒间隔的数据
val lines = streamingContext.socketTextStream("server01", 9999)
// 将5秒传递过来的数据进行运算,返回运算结果
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print() // 结果打印输出
streamingContext.start()
streamingContext.awaitTermination() // 等待
}
}
在linux的server01机器上,使用nc -lk 9999命令,输出text数据,在控制台打印的结果如下:。

- updateStateByKey
object SparkStreaming1 {
Logger.getLogger("org").setLevel(Level.ERROR)
/**
* updateStateByKey方法所需要的函数,计算每个时间间隔的累计结果
*/
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
// 将值相加求和
val newCount = newValues.sum + runningCount.getOrElse(0)
Some(newCount)
}
def main(args: Array[String]): Unit = {
// master 需要 2 cores 防止饥饿场景
val conf = new SparkConf().setAppName("SparkStreaming1").setMaster("local[2]")
// 设置时间间隔为5秒
val streamingContext = new StreamingContext(conf, Seconds(5))
// 设置checkpoint
streamingContext.checkpoint("./checkpoint")
// 设置 socket 机器 host + port
val lines = streamingContext.socketTextStream("server01", 9999)
// 将5秒传递过来的数据进行运算,返回运算结果
val result = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction)
result.print() // 结果打印输出
streamingContext.start() // 启动 SparkStreaming
streamingContext.awaitTermination() // 等待
}
}
控制台输出结果:
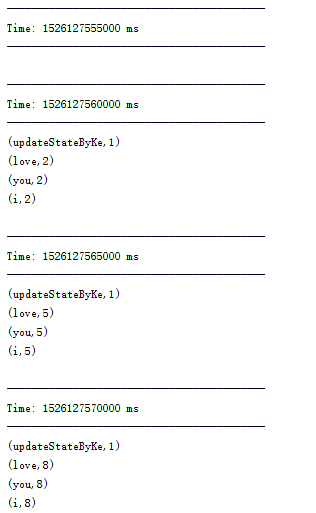
reduceByKey()只是对当前时间间隔数据进行计算,不会其他历史时间间隔计算的结果进行处理
updateStateByKey()可以对当前时间间隔的数据和历史计算结果进行处理。传入的函数参数和返回值类型为:func(newValues: Seq[Int], runningCount: Option[Int]):Option[Int]。这里的Int的泛型可以改为其他类型。
2. Window Option
Window操作是多次批处理的整合,是批处理间隔时间的整数倍。
基于Window操作都需要有2个参数,2者必须是批处理间隔时间的整数倍。
window时长:是一个窗口覆盖的流数据的时间长度,控制每次计算最近的多少个批次的数据,其实就是
windowDuration/batchInterval。slide时间间隔:是前一个窗口到后一个窗口所经过的时间长度,默认值与批处理时间间隔相等。
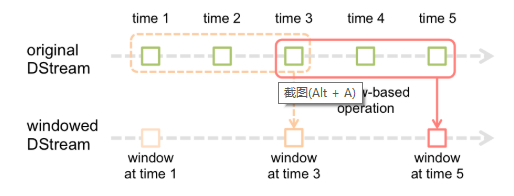
下面来下是示例:
object SparkStreaming2 {
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkStreaming2").setMaster("local[2]")
val streamingContext = new StreamingContext(conf, Seconds(5))
val lines = streamingContext.socketTextStream("server01", 9999)
val windowDuration = Seconds(30) // window的窗口有效时间
val slideDuration = Seconds(10) // 窗口滑动时间
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKeyAndWindow((a: Int, b: Int) => a + b, windowDuration, slideDuration)
result.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
结果如图:

我们可以看出,silde窗口滑动时间是计算Window窗口长度内的数据,输出结果。