目录
2.3 Storm,SparkStreaming和Flink的对比
3.1 StreamingContext和Receiver说明
SparkStreaming基础
1 流式计算
流式计算就像水流一样,数据连绵不断的产生,并被快速处理。
流式计算特点:①数据是无界的(unbounded);②数据是动态的;③计算速度是非常快的;④计算不止一次;⑤计算不能终止
离线计算特点 :①数据是有界的(Bounded) ;②数据静态的 ;③计算速度通常较慢 ;④计算只执行一次 ;⑤计算终会终止
1.1 常见的离线和流式计算框架
常见的离线计算框架:mapreduce,spark-core,flink-dataset
常见的流式计算框架 :storm(jstorm) ,spark-streaming,flink-datastream(blink)
2 SparkStreaming简介
SparkStreaming,和SparkSQL一样,也是Spark生态栈中非常重要的一个模块,主要是用来进行流式计算的框架。流式计算框架,从计算的延迟上面,又可以分为纯实时流式计算和准实时流式计算,SparkStreaming是属于的准实时计算框架。
纯实时的计算,指的是来一条记录(event事件),启动一次计算的作业;离线计算,指的是每次计算一个非常大的一批(比如几百G,好几个T)数据;准实时呢,介于纯实时和离线计算之间的一种计算方式。
SparkStreaming是SparkCore的api的一种扩展,使用DStream(discretized stream or DStream)作为数据模型,基于内存处理连续的数据流,本质上还是RDD的基于内存的计算。
DStream,本质上是RDD的序列。
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。

2.1 核心概念DStream
类似于SparkCore中的RDD和SparkSQL中的Dataset、DataFrame,在SparkStreaming中的编程模型是DStream(离散化的流)。DStream是对一个时间段内产生的一些列RDD的封装,也就是说一个DStream内部包含多个RDD。
DStream可以通过输入算子来创建,也可以通过高阶算子,比如map、flatMap等等进行转换产生。

2.2 工作原理
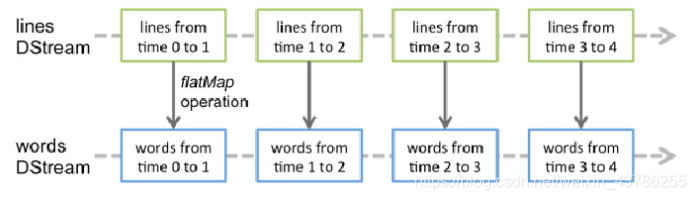
对DStream应用的算子,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作。
还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
2.3 Storm,SparkStreaming和Flink的对比

2.4 如何选择流式处理框架
(1)Storm:
①建议在需要纯实时,不能忍受1秒以上延迟的场景下使用,要求纯实时进行交易和分析时。 ②要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm,但是Spark Streaming也可以保证数据的不丢失。③如果我们需要考虑针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),我们也可以考虑用Storm
(2)Spark Streaming
①不满足上述Storm要求的话,我们可以考虑使用Spark Streaming来进行实时计算。 ②考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询、图计算和MLIB机器学习等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
(3)Flink
支持高吞吐、低延迟、高性能的流处理 支持带有事件时间的窗口(Window)操作 支持有状态计算的Exactly-once语义 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作 支持具有Backpressure功能的持续流模型 支持基于轻量级分布式快照(Snapshot)实现的容错 一个运行时同时支持Batch on Streaming处理和Streaming处理 Flink在JVM内部实现了自己的内存管理 支持迭代计算 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存。
3 SparkStreaming实时案例
SparkStreaming中的入口类,称之为StreamingContext,但是底层还是得需要依赖SparkContext。
object _01SparkStreamingWordCountOps {
def main(args: Array[String]): Unit = {
/*
StreamingContext的初始化,需要至少两个参数,SparkConf和BatchDuration
SparkConf不用多说
batchDuration:提交两次作业之间的时间间隔,每次会提交一个DStream,将数据转化batch--->RDD
所以说:sparkStreaming的计算,就是每隔多长时间计算一次数据
*/
val conf = new SparkConf()
.setAppName("SparkStreamingWordCount")
.setMaster("local[*]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
//业务
val lines:ReceiverInputDStream[String] = ssc.socketTextStream(hostname, port.toInt)
val retDStream:DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_, 1)).reduceByKey(_+_)
retDStream.print()
//为了执行的流式计算,必须要调用start来启动
ssc.start()
//为了不至于start启动程序结束,必须要调用awaitTermination方法等待程序业务完成之后调用stop方法结束程序,或者异常
ssc.awaitTermination()
}
}3.1 StreamingContext和Receiver说明
(1)关于local
当将上述程序中的master由local[*],修改为local的时候,程序业务不变,发生只能接收数据,无法处理数据。 local[*]和local的区别:后者只为当前程序提供一个线程来处理,前者提供可用的所有的cpu的core来处理,当前情况下为2或者4。
SparkStreaming优先使用线程资源来接收数据,其次才是对数据的处理,接收数据的对象就是Receiver。所以,如果读取数据的时候有receiver,程序的线程个数至少为2。
(2)关于start
start方法是用来启动当前sparkStreaming应用的,所以,是不能在ssc.start()之后再添加任何业务逻辑
start()方法只会让当前的计算执行一次,要想持续不断的进行接收数据,计算数据,就需要使用awaitTermination方法

(3)关于Receiver
Receiver就是数据的接收者,把资源分成了两部分,一部分用来接收数据,一部分用来处理数据。Receiver接收到的数据,其实就是一个个的batch数据,是RDD,存储在Executor内存。Receiver就是Executor内存中的一部分。
4 SparkStreaming和HDFS整合
SparkStreaming监听hdfs的某一个目录,目录下的新增文件,做实时处理。这种方式在特定情况下还是挺多的。需要使用的api为:ssc.fileStream()。
监听的文件,必须要从另一个相匹配的目录移动到其它目录。
(1)监听本地:无法读取手动拷贝,或者剪切到指定目录下的文件,只能读取通过流写入的文件。
(2)监听hdfs:正常情况下,我们可以读取到通过put上传的文件,还可以读取通过cp拷贝的文件,但是读取不了mv移动的文件。读取文件的这种方式,没有额外的Receiver消耗线程资源,所以可以指定master为local
object SparkStreamingHDFS {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("SparkStreamingHDFS")
.setMaster("local[2]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
//读取local中数据 --->需要通过流的方式写入
// val lines = ssc.textFileStream("file:///E:/data/monitored")
//读取hdfs中数据
val lines = ssc.textFileStream("hdfs://bigdata01:9000/data/spark")
lines.print()
ssc.start()
ssc.awaitTermination()
}
}5 SparkStreaming与Kafka整合
kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。
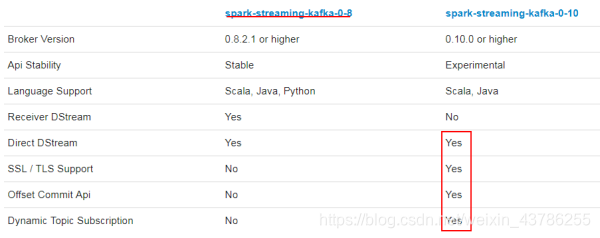
SparkStreaming和Kafka的整合有两大版本——spark-streaming-kafka-0-8和spark-streaming-kafka-0-10。spark-streaming-kafka-0-8版本还有两种方式——Receiver和Direct方式。
5.1 spark-stremaing-kafka-0-8
依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.2.2</version>
</dependency>(1)Receiver的方式
/**
* 使用kafka的receiver-api读取数据
*/
object SparkStreamingKafkaReceiverOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("SparkStreamingKafkaReceiverOps")
.setMaster("local[*]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
val kafkaParams = Map[String, String](
"zookeeper.connect" -> "bigdata01:2181,bigdata02:2181,bigdata03:2181/kafka",
"group.id" -> "receiver",
"zookeeper.connection.timeout.ms" -> "10000"
)
val topics = Map[String, Int](
"spark" -> 3
)
val messages:ReceiverInputDStream[(String, String)] = KafkaUtils
.createStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics,StorageLevel.MEMORY_AND_DISK_SER_2)
messages.print()
ssc.start()
ssc.awaitTermination()
}
}这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。
在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。 (如果要开启wal,需要在sparkconf中配置参数:spark.streaming.receiver.writeAheadLog.enable=true)
数据会丢失原因:
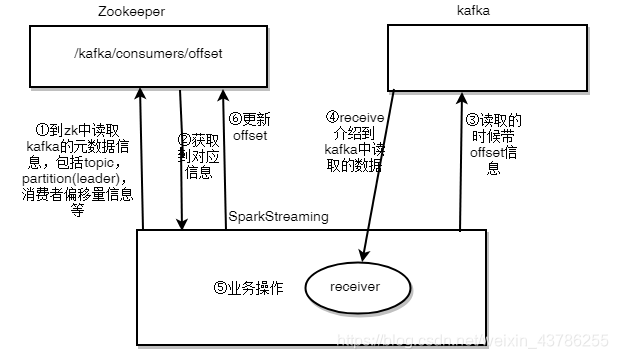
在上图消费的过程中,需要处理数据和offset两件事,任何一个出问题都会导致处理失败:
①数据处理成功,保存偏移量失败:数据被重复消费at-least-once
②偏移量保存成功,数据处理失败:数据最多只能被处理一次at-most-once
③都处理成功:数据恰好处理一次:exactly-once
要想达到数据恰好处理一次那就只能将offset和数据处理保证在一个事务中,保证其原子性
注意:
①Kafka的topic分区和Spark Streaming中生成的RDD分区没有关系。 在KafkaUtils.createStream中增加分区数量只会增加单个receiver的线程数,不会增加Spark的并行度
②可以创建多个的Kafka的输入DStream, 使用不同的group和topic, 使用多个receiver并行接收数据。
③如果启用了HDFS等有容错的存储系统,并且启用了写入日志,则接收到的数据已经被复制到日志中。因此,输入流的存储级别设置StorageLevel.MEMORY_AND_DISK_SER(即使用KafkaUtils.createStream(...,StorageLevel.MEMORY_AND_DISK_SER))的存储级别。
(2)Direct的方式
//基于direct方式整合kafka
object parkStreamingKafkaDirectOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("parkStreamingKafkaDirectOps")
.setMaster("local[*]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "direct",
"auto.offset.reset" -> "largest"
)
val topics = "spark".split(",").toSet
val messages: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
messages.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
val offsetRDD = rdd.asInstanceOf[HasOffsetRanges]
val offsetRanges = offsetRDD.offsetRanges
for(offsetRange <- offsetRanges) {
val topic = offsetRange.topic
val partition = offsetRange.partition
val fromOffset = offsetRange.fromOffset
val untilOffset = offsetRange.untilOffset
println(s"topic:${topic}\tpartition:${partition}\tstart:${fromOffset}\tend:${untilOffset}")
}
rdd.count()
}
})
ssc.start()
ssc.awaitTermination()
}
}优势:
①更加简单的并行度:Direct模式下面,不再像receiver的方式,如果提高消费的性能,需要创建多个InputStream,最后将它们进行union,之后整体进行操作。Direct模式中,topic的分区数就和rdd的分区是一一对应的,此时我们每个rdd的分区就用来消费topic中的一个分区。
②性能较高:Receiver模式下面,为了保证数据零丢失,开启了WAL。但是会对数据多两次备份——kafka本身和wal,同时在备份过程中肯定需要时间,所以性能不是很高。而Direct模式,因为没有receiver,也就没有wal,只需要有足够的retention策略,我们就可以从kafka中进行恢复。因为此时的偏移量被我们的程序所控制。
③一致性(Exactly-once)的语义
在流式计算过程中会有不同的语义,这些语义产生的原因,就是一条记录被处理一次,被处理多次,一次或者一次也没有被处理,对应语义称之为Exactly once,at least once, at most once。不管是at least还是at most都会造成计算结果和真实的结果有偏差,不是我们所乐见的。
receiver的这种方式,会造成数据at least once,因为wal的存在,spark程序和偏移量之间的读写关系不一致。而在Direct的情况下可以保证数据的Exactly once semantics,因为我们使用的kafka底层的api,可以更加精准地在程序中把握偏移量。此时我们就不需要使用zookeeper,而使用checkpoint来存储偏移量。
但是,为了保证数据输出的一致性语义,则需要spark程序的输出是幂等操作或者是原子性操作。
幂等说明:多次操作结果都一样,把这种操作称之为幂等操作,比如数据库的delete操作
(3)offset的问题
/*
offset的checkpoint(检查点)
把需要管理的相关数据保存在某一个目录下面,后续的时候直接从该目录中读取即可,
在此处就是保存offset数据
*/
object CheckpointKafkaDirectOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("CheckpointKafkaDirectOps")
.setMaster("local")
val duration = Seconds(2)
val checkpoint = "file:///E:/data/chk"
def createFunc():StreamingContext = {
val ssc = new StreamingContext(conf, duration)
ssc.checkpoint(checkpoint)
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "checkpointgroup",
"auto.offset.reset" -> "smallest"
)
val topics = "spark".split(",").toSet
val messages: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
messages.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("num: " + rdd.getNumPartitions)
val offsetRDD = rdd.asInstanceOf[HasOffsetRanges]
val offsetRanges = offsetRDD.offsetRanges
for(offsetRange <- offsetRanges) {
val topic = offsetRange.topic
val partition = offsetRange.partition
val fromOffset = offsetRange.fromOffset
val untilOffset = offsetRange.untilOffset
println(s"topic:${topic}\tpartition:${partition}\tstart:${fromOffset}\tend:${untilOffset}")
}
rdd.count()
}
})
ssc
}
//创建或者恢复出来一个StreamingContext
val ssc = StreamingContext.getOrCreate(checkpoint, createFunc)
ssc.start()
ssc.awaitTermination()
}
}这种方式,虽然能够解决offset跟踪问题,但是会在checkpoint目录下面产生大量的小文件,并且操作进行磁盘的IO操作,性能相对较差。那我们选择其他方式管理offset偏移量,常见的管理offset偏移量的方式有如下:zookeeper、redis、hbase、mysql、elasticsearch、kafka,zookeeper也不建议使用,zookeeper太重要了,zk负载过高,容易出故障。
(4)zookeeper管理offset
/*
基于direct方式整合kafka
使用zk手动管理offset
*/
object KafkaDirectZKOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("KafkaDirectZKOps")
.setMaster("local")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "DirectZK",
"auto.offset.reset" -> "smallest"
)
val topics = "spark".split(",").toSet
val messages: InputDStream[(String, String)] = createMsg(ssc, kafkaParams, topics)
messages.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("-------------------------------------------")
println(s"Time: $bTime")
println("###########count: " + rdd.count())
storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges, kafkaParams("group.id"))
println("-------------------------------------------")
}
})
ssc.start()
ssc.awaitTermination()
}
/*
从zk中读取手动保存offset信息,然后从kafka指定offset位置开始读取数据,如果没有读取到offset信息,那么从最开始或者从最新的位置开始读取信息
*/
def createMsg(ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(String, String)] = {
//从zk中读取offset
val fromOffsets: Map[TopicAndPartition, Long] = getFromOffsets(topics, kafkaParams("group.id"))
var messages: InputDStream[(String, String)] = null
if(fromOffsets.isEmpty) {//没有读到offset
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
} else {//读取到了offset,从指定位置开始读取
val messageHandler = (msgHandler:MessageAndMetadata[String, String]) => (msgHandler.key(), msgHandler.message())
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc,
kafkaParams, fromOffsets, messageHandler)
}
messages
}
/*
从zk中读取offset信息
首先,定义offset交互的信息,比如数据的存放位置,存放格式
官方的操作:/kafka/consumers/${group.id}/offsets/${topic}/${partition} -->data为offset
存放位置&数据:/kafka/consumers/offsets/${topic}/${group.id}/${partition} -->data为offset
其次,用什么和zk中交互
zookeeper原生的api
curatorFramework(选择)
*/
def getFromOffsets(topics:Set[String], group:String):Map[TopicAndPartition, Long] = {
val offsets = mutable.Map[TopicAndPartition, Long]()
for (topic <- topics) {
val path = s"${topic}/${group}"
//判断当前路径是否存在
checkExists(path)
for(partition <- JavaConversions.asScalaBuffer(client.getChildren.forPath(path))) {
val fullPath = s"${path}/${partition}"
val offset = new String(client.getData.forPath(fullPath)).toLong
offsets.put(TopicAndPartition(topic, partition.toInt), offset)
}
}
offsets.toMap
}
def storeOffsets(offsetRanges: Array[OffsetRange], group:String) = {
for(offsetRange <- offsetRanges) {
val topic = offsetRange.topic
val partition = offsetRange.partition
val offset = offsetRange.untilOffset
val path = s"${topic}/${group}/${partition}"
checkExists(path)
client.setData().forPath(path, offset.toString.getBytes)
}
}
def checkExists(path:String): Unit = {
if(client.checkExists().forPath(path) == null) {//路径不能存在
client.create().creatingParentsIfNeeded().forPath(path)
}
}
val client = {
val client = CuratorFrameworkFactory.builder()
.connectString("bigdata01:2181,bigdata02:2181,bigdata03:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.namespace("kafka/consumers/offsets")
.build()
client.start()
client
}
}(5)redis管理offset
导入redis的maven依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>redis的操作工具类:
//入口类:Jedis -->代表的是redis的一个客户端连接,相当于Connection
public class JedisUtil {
static JedisPool pool;
static {
JedisPoolConfig config = new JedisPoolConfig();
String host = "bigdata01";
int port = 6379;
pool = new JedisPool(config, host, port);
}
public static Jedis getJedis() {
return pool.getResource();
}
public static void release(Jedis jedis) {
jedis.close();
}
}/*
基于direct方式整合kafka
使用redis手动管理offset
*/
object KafkaDirectRedisOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("KafkaDirectRedisOps")
.setMaster("local")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "redisOps",
"auto.offset.reset" -> "smallest"
)
val topics = "spark".split(",").toSet
val messages: InputDStream[(String, String)] = createMsg(ssc, kafkaParams, topics)
messages.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("-------------------------------------------")
println(s"Time: $bTime")
println("count: " + rdd.count())
storeOffsets(rdd.asInstanceOf[HasOffsetRanges].offsetRanges, kafkaParams("group.id"))
println("-------------------------------------------")
}
})
ssc.start()
ssc.awaitTermination()
}
/*
从zk中读取手动保存offset信息,然后从kafka指定offset位置开始读取数据,当然如果没有读取到offset信息,
那么从最开始或者从最新的位置开始读取信息
*/
def createMsg(ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(String, String)] = {
//从zk中读取offset
val fromOffsets: Map[TopicAndPartition, Long] = getFromOffsets(topics)
var messages: InputDStream[(String, String)] = null
if(fromOffsets.isEmpty) {//没有读到offset
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
} else {//读取到了offset,从指定位置开始读取
val messageHandler = (msgHandler:MessageAndMetadata[String, String]) => (msgHandler.key(), msgHandler.message())
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc,
kafkaParams, fromOffsets, messageHandler)
}
messages
}
/*
从redis中读取offset信息K-V
首先,定义offset交互的信息,比如数据的存放位置,存放格式
topic partition offset group
五种数据结构:
string
topic|group|partition offset
list
a
b
c
hash
key field-value ...
topic group|partition offset
group topic|partition offset
set
zset
其次,用什么和redis中交互
*/
def getFromOffsets(topics:Set[String]):Map[TopicAndPartition, Long] = {
val offsets = mutable.Map[TopicAndPartition, Long]()
val jedis = JedisUtil.getJedis
for (topic <- topics) {
val gpo = jedis.hgetAll(topic)
for((gp, offset) <- gpo) {
val partition = gp.substring(gp.indexOf("|") + 1).toInt
offsets.put(TopicAndPartition(topic, partition), offset.toLong)
}
}
JedisUtil.release(jedis)
offsets.toMap
}
def storeOffsets(offsetRanges: Array[OffsetRange], group:String) = {
val jedis = JedisUtil.getJedis
for(offsetRange <- offsetRanges) {
val topic = offsetRange.topic
val partition = offsetRange.partition
//untilOffset:结束offset
val offset = offsetRange.untilOffset
val gp = s"${group}|${partition}"
jedis.hset(topic, gp, offset.toString)
}
JedisUtil.release(jedis)
}
}6 消费kafka的时候常见的问题
6.1 生产速率过高
问题描述:SparkStreaming程序消费的能力要低于拉取kafka数据的能力,久而久之会造成数据的堆积,产生比如数据存储压力,计算压力,造成程序异常。
(1)解决方式一:提高消费能力
提高消费能力,最简单的就是提高并行度,在SparkStreaming基于Direct模式下增加topic的partition个数
(2)解决方式二:限流
添加一个配置参数即可——spark.streaming.kafka.maxRatePerPartition(基于Direct模式,每秒从每一个kafka 分区中读取到的最大的记录条数。
假设有一个Topic,分区有3个,streaming程序的batchInterval=2s,配置的改参数为spark.streaming.kafka.maxRatePerPartition=200,请问该stremaing程序每个批次最多能读取:2 * 3 * 200 = 1200
6.2 偏移量过期
解决方案:每次从zk中读到偏移量的之后,和当前Kafka topic partition的offset进行比较,如果异常,在读取数据之前进行offset修正。如果zk中保存到的偏移量小于kafka读取到的偏移量,将其设置为最小偏移量,反之设置为最大偏移量。
7 DStream常见的的transformation
| map(func) | 对DStream中的各个元素进行func函数操作,返回返回一个新的DStream |
| flatMap(func) | 与map方法类似,不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数返回值为true的DStream元素并返回一个新的DStream |
| repartition(numPartition) | 增加或减少DStream中的分区数,从而改变DStream的并行度 |
| union(otherDStream) | 将源DSTream和输入参数为otherDStream的元素合并,返回一个新的DStream |
| count() | 通过对DStream中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成一个DStream |
| reduce(func) | 通过对DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成一个DStream |
| countByValue() | 对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
| reduceByKey(func,[numTasks]) | 利用func函数对源DStream中的key进行聚合操作,返回返回新的(K,V)对构成DStream |
| join(otherDStream,[numTasks]) | 输入为(K,V),(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
| cogroup(otherDStream,[numTasks]) | 输入为(K,V),(K,W)类型的DStream,返回一个新的(K,(Seq[V],Seq[W]))类型的DStream |
| transform(func) | 通过对RDD-to-RDD函数作用域源码DStream中的各个RDD,可以是任意的RDD操作,返回一个新的RDD |
| updateStateByKey(func) | 根据key的前置状态和key的新志,对比key进行更新,返回一个新状态的DStream |
| window函数 |
(1)cogroup:ogroup就是groupByKey的另外一种变体,groupByKey是操作一个K-V键值对,而cogroup一次操作两个,有点像join,不同之处在于返回值结果:
val ds1:DStream[(K, V)]
val ds2:DStream[(K, w)]
val cg:DStream[(K, (Iterable[V], Iterable[W]))] = ds1.cogroup(ds1)(2)transform:DStream提供的所有的transformation操作,除transform外都是DStream-2-DStream操作,没有一个DStream和RDD的直接操作,而DStream本质上是一系列RDD,所以RDD-2-RDD操作是显然被需要的,所以此时官方api中提供了一个为了达成此操作的算子——transform操作。
最常见的就是DStream和rdd的join操作,还有DStream重分区(分区减少,coalsce)。也就是说transform主要就是用来自定义官方api没有提供的一些操作。
下个举个例子说明transform:动态黑名单过滤,利用SparkStreaming的流处理特性,可实现实时黑名单的过滤实现。可以使用leftouter join 对目标数据和黑名单数据进行关联,将命中黑名单的数据过滤掉。
/**
* 在线黑名单过滤
*
* 需求:
* 从用户请求的nginx日志中过滤出黑名单的数据,保留白名单数据进行后续业务统计。
* data structure
* 27.19.74.143##2016-05-30 17:38:20##GET /static/image/common/faq.gif HTTP/1.1##200##1127
*/
object lineBlacklistFilterOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("lineBlacklistFilterOps")
.setMaster("local[*]")
val duration = Seconds(2)
val ssc = new StreamingContext(conf, duration)
//自定义一个简单的黑名单RDD
val blacklistRDD:RDD[(String, Boolean)] = ssc.sparkContext.parallelize(List(
("27.19.74.143", true),
("110.52.250.126", true)
))
//接入外部的数据流
val lines:DStream[String] = ssc.socketTextStream("bigdata01", 9999)
//黑名单过滤
// 110.52.250.126##2016-05-30 17:38:20##GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1##200##1292
val ip2OtherDStream:DStream[(String, String)] = lines.map(line => {
val index = line.indexOf("##")
val ip = line.substring(0, index)
val other = line.substring(index + 2)
(ip, other)
})
val filteredDStream:DStream[(String, String)] = ip2OtherDStream.transform(rdd => {
val join = rdd.leftOuterJoin(blacklistRDD)
join.filter{case (ip, (left, right)) => {
!right.isDefined
}}.map{case (ip, (left, right)) => {
(ip, left)
}}
})
filteredDStream.print()
//重分区
// filteredDStream.transform(_.coalesce(8))
ssc.start()
ssc.awaitTermination()
}
}(3)updateStateByKey:根据于key的前置状态和key的新值,对key进行更新,返回一个新状态的Dstream。其实就是统计截止到目前为止key的值。
通过分析,在这个操作中需要两个数据,一个是key的前置状态,一个是key的新增(当前批次的数据);还有历史数据(前置状态)得需要存储在磁盘,不应该保存在内存中。同时key的前置状态可能有可能没有。
为了达到这个目的,最直接就得需要一个位置来存储当前key的历史的状态。在SparkStreaming中,这个位置就存储在checkpoint的目录中。得需要两个步骤:第一,定义状态;第二,定义状态函数。

举例说明:计算截止到目前为止的全网总交易额,总流量
object SparkStreamingUSBOps {
def main(args: Array[String]): Unit = {
if(args == null || args.length < 3) {
println(
"""
|Parameter Errors ! Usage: <batchInterval> <host> <port>
""".stripMargin)
System.exit(-1)
}
val Array(batchInterval, host, port) = args //模式匹配
val conf = new SparkConf()
.setAppName("SparkStreamingUSBOps")
.setMaster("local[*]")
val checkpoint = "file:///E:/data/chk"
def createFunc():StreamingContext = {
val ssc = new StreamingContext(conf, Seconds(batchInterval.toLong))
ssc.checkpoint(checkpoint)
val linesDStream:ReceiverInputDStream[String] = ssc.socketTextStream(host, port.toInt)
val pairs = linesDStream.flatMap(_.split("\\s+")).map((_, 1))
//更新key的状态
val usb:DStream[(String, Int)] = pairs.updateStateByKey[Int]((seq, option) => updateFunc(seq, option))
usb.print()
ssc
}
/**
* getActiveOrCreate: 获的一个Active的StreamingContext或者创建一个信息
* getOrCreate: 创建一个或者恢复一个
*/
val ssc = StreamingContext.getOrCreate(checkpoint, createFunc)
ssc.start()
ssc.awaitTermination()
}
/**
*基于key的前置状态,和当前状态进行合并,转化为最新的状态
* 现在要统计总交易额:
* 数据实时被打进计算系统。
* long sum = 0;
* 每一个批次的值:newValue
* 总交易:sum += newValue
* 前置状态
* 去年的时候,reduel的18岁,
* 今年,refuel:19岁
* @param current 当前批次的key对应的vlaue
* @param previous 当前key对应的前置状态,可能有,可能没有
* @return
*/
def updateFunc(current:Seq[Int], previous:Option[Int]): Option[Int] = {
println(s"current: ${current.mkString(",")}--->previous: ${previous}")
// var sum = 0
// for(cur <- current) {
// sum += cur
// }
// val historyVal = previous.getOrElse(0)
// sum += historyVal
//
// Option(sum)
Option(current.sum + previous.getOrElse(0))
}
}
(4)window:窗口函数
是一个在流式计算领域中普遍都存在的一个概念——窗口函数。指的是一个窗口的数据,因为在Streaming中,每次计算的是一个批次的数据。这个窗口的概念跨域了批次,也就是说同时计算的数据,可以是多个批次的。

这个窗口操作,需要两个参数:windowLength窗口长度;slidingInterval计算频率或者滑动频率。
每隔M长的时间,去统计过去N长时间产生的数据。M就是slidingInterval,N就是windowLength。
注意:此时不再以前的每个批次都提交一次作业,多个批次的数据合并到一起一同提交,所以需要拥有足够的内存容纳下下多个批次的数据。同时这里的streaming统计都是基于batchInterval来进行提交的,所以这里的windowLength和slidingInterval必须都是batchInterval(批处理时间间隔)的整数倍。
举例说明如下:
/**
* 基于window的窗口函数操作
* 基本上所有的dstream的算子函数都有对应的window操作
* 每隔2个时间单位,统计过去3个时间单位的数据
* 1 2 3 4 5
* ① ②
*/
object parkStreamingWindowsOps {
def main(args: Array[String]): Unit = {
if(args == null || args.length < 3) {
println(
"""
|Parameter Errors ! Usage: <batchInterval> <host> <port>
""".stripMargin)
System.exit(-1)
}
val Array(batchInterval, host, port) = args //模式匹配
val windowLen = Seconds(batchInterval.toLong * 3)
val slidingDuration = Seconds(batchInterval.toLong * 2)
val conf = new SparkConf()
.setAppName("parkStreamingWindowsOps")
.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(batchInterval.toLong))
val lines = ssc.socketTextStream(host, port.toInt)
val ret = lines.flatMap(_.split("\\s+")).map((_, 1))
.reduceByKeyAndWindow(
(v1:Int, v2:Int) => reduceFunc(v1, v2),
windowLen,
slidingDuration
)
ret.print()
ssc.start()
ssc.awaitTermination()
}
def reduceFunc(v1:Int, v2:Int):Int = v1 + v2
}8 缓存和CheckPoint机制
8.1 缓存持久化
其实和RDD的持久化一样,通过persist()方法来实现。需要指定持久化策略,大多算子默认情况下,持久化策略为MEMORY_AND_DISK_SER_2。
8.2 checkpoint机制
(1)为什么需要checkpoint
每一个Spark Streaming应用,正常来说,都是要7*24小时运转的,这就是实时计算程序的特点。因为要持续不断的对数据进行计算。因此,对实时计算应用的要求,应该是必须要能够对与应用程序逻辑无关的失败,进行容错。
如果要实现这个目标,Spark Streaming程序就必须将足够的信息checkpoint到容错的存储系统上,从而让它能够从失败中进行恢复。
(2)Checkpoint相关
①元数据
配置信息:创建Spark Streaming应用程序的配置信息,比如SparkConf中的信息
DStream操作信息:定义了Spark Stream应用程序的计算逻辑的DStream操作信息。
未处理的batch信息:那些job正在排队,还没处理的batch信息。
②数据
对于一些将多个batch的数据进行聚合的,有状态的transformation操作,这是非常有用的。在这种transformation操作中,生成的RDD是依赖于之前的batch的RDD的,这会导致随着时间的推移,RDD的依赖链条变得越来越长。要避免由于依赖链条越来越长,导致的一起变得越来越长的失败恢复时间,有状态的transformation操作执行过程中间产生的RDD,会定期地被checkpoint到可靠的存储系统上,比如HDFS。从而削减RDD的依赖链条,进而缩短失败恢复时,RDD的恢复时间。
(3)启动checkpoint
ssc.checkpoint(path)
注意:要注意的是,并不是说,所有的Spark Streaming应用程序,都要启用checkpoint机制,如果即不强制要求从Driver失败中自动进行恢复,又没使用有状态的transformation操作,那么就不需要启用checkpoint。事实上,这么做反而是有助于提升性能的。
使用了有状态的transformation操作——比如updateStateByKey,或者reduceByKeyAndWindow操作,被使用了,那么checkpoint目录要求是必须提供的,也就是必须开启checkpoint机制,从而进行周期性的RDD checkpoint。
①开启的方式
普通的checkpoint就使用上述的checkpoint即可,但是如果是driver要从失败中进行恢复,就行修改程序。主要修改的就是StreamingContext的构建方式val ssc = StreamingContext.getOrCreate(checkpoint, func)
/*
offset的checkpoint(检查点)
把需要管理的相关数据保存在某一个目录下面,后续的时候直接从该目录中读取即可,
在此处就是保存offset数据
*/
object CheckpointWithKafkaDirectOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
val conf = new SparkConf()
.setAppName("CheckpointWithKafkaDirectOps")
.setMaster("local")
val duration = Seconds(2)
val checkpoint = "file:///E:/data/chk"
def createFunc():StreamingContext = {
val ssc = new StreamingContext(conf, duration)
ssc.checkpoint(checkpoint)
val kafkaParams = Map[String, String](
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "Checkpoint",
"auto.offset.reset" -> "smallest"
)
val topics = "spark".split(",").toSet
val messages: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
messages.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {
println("num: " + rdd.getNumPartitions)
val offsetRDD = rdd.asInstanceOf[HasOffsetRanges]
val offsetRanges = offsetRDD.offsetRanges
for(offsetRange <- offsetRanges) {
val topic = offsetRange.topic
val partition = offsetRange.partition
val fromOffset = offsetRange.fromOffset
val untilOffset = offsetRange.untilOffset
println(s"topic:${topic}\tpartition:${partition}\tstart:${fromOffset}\tend:${untilOffset}")
}
rdd.count()
}
})
ssc
}
//创建或者恢复出来一个StreamingContext
val ssc = StreamingContext.getOrCreate(checkpoint, createFunc)
ssc.start()
ssc.awaitTermination()
}
}9 DriverHA
9.1 原理
由于流计算系统是长期运行、且不断有数据流入,因此其Spark守护进程(Driver)的可靠性至关重要,它决定了Streaming程序能否一直正确地运行下去。 Driver实现HA的解决方案就是将元数据持久化,以便重启后的状态恢复。如图一所示,Driver持久化的元数据包括: Block元数据(图中的绿色箭头):Receiver从网络上接收到的数据,组装成Block后产生的Block元数据; Checkpoint数据(图中的橙色箭头):包括配置项、DStream操作、未完成的Batch状态、和生成的RDD数据等;
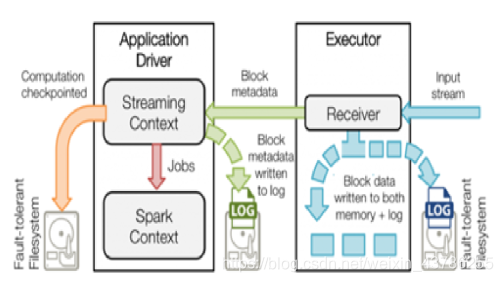
恢复计算(图中的橙色箭头):使用Checkpoint数据重启driver,重新构造上下文并重启接收器。恢复元数据块(图中的绿色箭头):恢复Block元数据。
恢复未完成的作业(图中的红色箭头):使用恢复出来的元数据,再次产生RDD和对应的job,然后提交到Spark集群执行。 通过如上的数据备份和恢复机制,Driver实现了故障后重启、依然能恢复Streaming任务而不丢失数据,因此提供了系统级的数据高可靠。
9.2 DriverHA的配置
#!/bin/sh
SPARK_HOME=/home/refuel/opt/moudle/spark
$SPARK_HOME/bin/spark-submit \
--master spark://bigdata01:7077 \
--deploy-mode cluster \
--class com.refuel.bigdata.streaming.SparkStreamingDriverHAOps \
--executor-memory 600M \
--executor-cores 2 \
--driver-cores 1 \
--supervise \
--total-executor-cores 3 \
hdfs://ns1/jars/spark/sparkstreaming-drverha.jar 2 bigdata01 9999 \
hdfs://ns1/checkpoint/spark/driverha9.3 Driver代码实现
object SparkStreamingDriverHAOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.spark_project").setLevel(Level.WARN)
if(args == null || args.length < 4) {
System.err.println(
"""
|Parameter Errors! Usage: <batchInterval> <host> <port> <checkpoint>
""".stripMargin)
System.exit(-1)
}
val Array(batchInterval, host, port, checkpoint) = args
val conf = new SparkConf()
.setAppName("SparkStreamingDriverHA")
.setMaster("local[*]")
def createFunc():StreamingContext = {
val ssc = new StreamingContext(conf, Seconds(batchInterval.toLong))
ssc.checkpoint(checkpoint)
val lines:DStream[String] = ssc.socketTextStream(host, port.toInt)
val pairs:DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_, 1))
val usb:DStream[(String, Int)] = pairs
.updateStateByKey((seq, option) => Option(seq.sum + option.getOrElse(0)))
usb.print()
ssc
}
val ssc = StreamingContext.getOrCreate(checkpoint, createFunc)
ssc.start()
ssc.awaitTermination()
}
}10. Spark Streaming 性能调优
10.1 设置合理的CPU
很多情况下Streaming程序需要的内存不是很多,但是需要的CPU要很多。在Streaming程序中,CPU资源的使用可以分为两大类:
(1)用于接收数据;
(2)用于处理数据。我们需要设置足够的CPU资源,使得有足够的CPU资源用于接收和处理数据,这样才能及时高效地处理数据。
10.2 接受数据的调优
(1)通过网络接收数据时(比如Kafka、Flume、ZMQ、RocketMQ、RabbitMQ和ActiveMQ等),会将数据反序列化,并存储在Spark的内存中。
(2)如果数据接收成为系统的瓶颈,那么可以考虑并行化数据接收。每一个输入DStream都会在某个Worker的Executor上启动一个Receiver,该Receiver接收一个数据流。因此可以通过创建多个输入DStream,并且配置它们接收数据源不同的分区数据,达到接收多个数据流的效果。
举例说明:一个接收4个Kafka Topic的输入DStream,可以被拆分为两个输入DStream,每个分别接收二个topic的数据。这样就会创建两个Receiver,从而并行地接收数据,进而提升吞吐量。多个DStream可以使用union算子进行聚合,从而形成一个DStream。然后后续的transformation算子操作都针对该一个聚合后的DStream即可。
(3)使用inputStream.repartition(<number of partitions>)即可。这样就可以将接收到的batch,分布到指定数量的机器上,然后再进行进一步的操作。
(4)数据接收并行度调优,除了创建更多输入DStream和Receiver以外,还可以考虑调节block interval。通过参数,spark.streaming.blockInterval,可以设置block interval,默认是200ms。对于大多数Receiver来说,在将接收到的数据保存到Spark的BlockManager之前,都会将数据切分为一个一个的block。而每个batch中的block数量,则决定了该batch对应的RDD的partition的数量,以及针对该RDD执行transformation操作时,创建的task的数量。每个batch对应的task数量是大约估计的,即batch interval / block interval。
举个例子:①batch interval为3s,block interval为150ms,会创建20个task。如果你认为每个batch的task数量太少,即低于每台机器的cpu core数量,那么就说明batch的task数量是不够的,因为所有的cpu资源无法完全被利用起来。要为batch增加block的数量,那么就减小block interval。
②推荐的block interval最小值是50ms,如果低于这个数值,那么大量task的启动时间,可能会变成一个性能开销点。
10.3 设置合理的并行度
如果在计算的任何stage中使用的并行task的数量没有足够多,那么集群资源是无法被充分利用的。举例来说,对于分布式的reduce操作,比如reduceByKey和reduceByKeyAndWindow,默认的并行task的数量是由spark.default.parallelism参数决定的。你可以在reduceByKey等操作中,传入第二个参数,手动指定该操作的并行度,也可以调节全局的spark.default.parallelism参数。该参数说的是,对于那些shuffle的父RDD的最大的分区数据。对于parallelize或者textFile这些输入算子,因为没有父RDD,所以依赖于ClusterManager的配置。如果是local模式,该默认值是local[x]中的x;如果是mesos的细粒度模式,该值为8,其它模式就是Math.max(2, 所有的excutor上的所有的core的总数)。
10.4 序列化调优
数据序列化造成的系统开销可以由序列化格式的优化来减小。在流式计算的场景下,有两种类型的数据需要序列化。
①输入数据:默认情况下,接收到的输入数据,是存储在Executor的内存中的,使用的持久化级别是StorageLevel.MEMORY_AND_DISK_SER_2。这意味着,数据被序列化为字节从而减小GC开销,并且会复制以进行executor失败的容错。因此,数据首先会存储在内存中,然后在内存不足时会溢写到磁盘上,从而为流式计算来保存所有需要的数据。这里的序列化有明显的性能开销——Receiver必须反序列化从网络接收到的数据,然后再使用Spark的序列化格式序列化数据。
②流式计算操作生成的持久化RDD:流式计算操作生成的持久化RDD,可能会持久化到内存中。例如,窗口操作默认就会将数据持久化在内存中,因为这些数据后面可能会在多个窗口中被使用,并被处理多次。然而,不像Spark Core的默认持久化级别,StorageLevel.MEMORY_ONLY,流式计算操作生成的RDD的默认持久化级别是StorageLevel.MEMORY_ONLY_SER ,默认就会减小GC开销。
在上述的场景中,使用Kryo序列化类库可以减小CPU和内存的性能开销。使用Kryo时,一定要考虑注册自定义的类,并且禁用对应引用的tracking(spark.kryo.referenceTracking)。
10.5 batchInterval
如果想让一个运行在集群上的Spark Streaming应用程序可以稳定,它就必须尽可能快地处理接收到的数据。换句话说,batch应该在生成之后,就尽可能快地处理掉。对于一个应用来说,这个是不是一个问题,可以通过观察Spark UI上的batch处理时间来定。batch处理时间必须小于batch interval时间。
在构建StreamingContext的时候,需要我们传进一个参数,用于设置Spark Streaming批处理的时间间隔。Spark会每隔batchDuration时间去提交一次Job,如果你的Job处理的时间超过了batchDuration的设置,那么会导致后面的作业无法按时提交,随着时间的推移,越来越多的作业被拖延,最后导致整个Streaming作业被阻塞,这就间接地导致无法实时处理数据,这肯定不是我们想要的。
另外,虽然batchDuration的单位可以达到毫秒级别的,但是经验告诉我们,如果这个值过小将会导致因频繁提交作业从而给整个Streaming带来负担,所以请尽量不要将这个值设置为小于500ms。在很多情况下,设置为500ms性能就很不错了。
那么,如何设置一个好的值呢?我们可以先将这个值位置为比较大的值(比如10S),如果我们发现作业很快被提交完成,我们可以进一步减小这个值,知道Streaming作业刚好能够及时处理完上一个批处理的数据,那么这个值就是我们要的最优值。
10.6 内存调优
内存调优的另外一个方面是垃圾回收。对于流式应用来说,如果要获得低延迟,肯定不想要有因为JVM垃圾回收导致的长时间延迟。有很多参数可以帮助降低内存使用和GC开销:
①DStream的持久化:正如在“数据序列化调优”一节中提到的,输入数据和某些操作生产的中间RDD,默认持久化时都会序列化为字节。与非序列化的方式相比,这会降低内存和GC开销。使用Kryo序列化机制可以进一步减少内存使用和GC开销。进一步降低内存使用率,可以对数据进行压缩,由spark.rdd.compress参数控制(默认false)。
②清理旧数据:默认情况下,所有输入数据和通过DStream transformation操作生成的持久化RDD,会自动被清理。Spark Streaming会决定何时清理这些数据,取决于transformation操作类型。例如,你在使用窗口长度为10分钟内的window操作,Spark会保持10分钟以内的数据,时间过了以后就会清理旧数据。但是在某些特殊场景下,比如Spark SQL和Spark Streaming整合使用时,在异步开启的线程中,使用Spark SQL针对batch RDD进行执行查询。那么就需要让Spark保存更长时间的数据,直到Spark SQL查询结束。可以使用streamingContext.remember()方法来实现。
③CMS垃圾回收器:使用并行的mark-sweep垃圾回收机制,被推荐使用,用来保持GC低开销。虽然并行的GC会降低吞吐量,但是还是建议使用它,来减少batch的处理时间(降低处理过程中的gc开销)。如果要使用,那么要在driver端和executor端都开启。在spark-submit中使用--driver-java-options设置;使用spark.executor.extraJavaOptions参数设置。-XX:+UseConcMarkSweepGC。
