进程优先级和分类
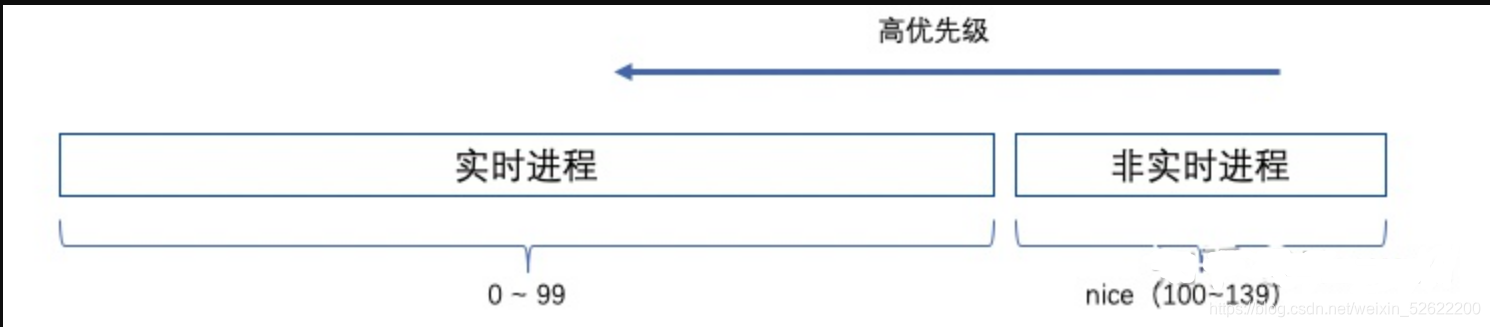
进程优先级代表进程需要运行的紧急程度和需要更多的运行时间片,Linux的优先级的范围是[0, 139],数值越小,优先级越高。用户态通过nice值设置优先级,nice值的范围是[-20,19],其映射到范围100—139。setpriority系统调用能修改进程的优先级0—139。
按照优先级又可以分为两类进程:
- 实时进程:要求最快速被响应,比如视频、工业机器控制程序等。
- 非实时进程:即普通进程,我们大部分程序使用的。其还可以细分为两类:1)交互式进程,需要响应前台请求。2)后台批处理进程,类似mr的计算。
Linux用task_struct表示一个进程(task_struct结构见文末,就不再解读了),通过以下3个字段表示优先级:
- prio:动态优先级,唯一被调度器使用的优先级字段,其依赖于normal_prio字段。调度器在运行期间可根据其倾向调整该值。
- static_prio:普通进程的优先级,仅能通过nice修改, static_prio的取值[100, 139],值越小优先级越高,其中MAX_RT_PRIO是最大的实时进程优先级值,同时nice[-20, 19],所以还需要加20。static_prio = MAX_RT_PRIO + nice +20
- rt_priority:实时进程的优先级,取值[0, 99],值越大优先级越大。
- normal_prio:归一化优先级,解决rt_priority单调递增、而static_prio单调递减问题。
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_rt_policy(p))
prio = MAX_RT_PRIO -1 - p->rt_priority; // 实时进程,转换为值约小优先级越高
else
prio = __normal_prio(p); // 普通进程,则直接返回
return prio;
}
static inline int __normal_prio(struct task_struct *p)
{
return p->static_prio;
}
调度策略和调度类
调度策略通过task_struct -> policy字段表示。实时进程的调度策略如下:
- SCHED_FIFO:先来先服务,高优先级抢占低优先级,相同优先级之间没有抢占,只有主动让出。
- SCHED_RR:轮流调度算法,高优先级抢占低优先级,相同优先级按时间片运行,时间片到期后其他进程可抢占。
- SCHED_DEADLINE:选择离deadline时间点最近的进程执行,直到执行完毕。
普通进程的调度策略:** SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE** 。根据名称应该都能猜出来策略是干嘛的。
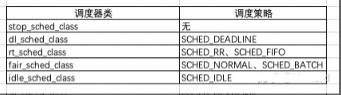
调度策略主要由调度类实现,主要的调度器类和对应的调度策略如下。
sched_class的核心方法如下:
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*update_curr) (struct rq *rq)
}
task_tick:tick中断的影响函数。
pick_next_task:选择下一个调入cpu的进程。
task_struct-> sched_class指向一个调度类链表,将实时进程的调度器类放在前面,保证实时进程先被处理和调度到。
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class
推荐自己的Linux、C/C++技术交流群:【960994558】整理了一些个人觉得比较好的学习书籍、大厂面试题、有趣的项目和热门技术视频资料共享在里面,有需要的可以自行添加哦!~(包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等等.)

调度算法的难点
- 快速响应高优先级的进程,同时不能饿死低优先级进程。
- 让高优先级进程有更多的运行时间,同时不能饿死低优先级的进程。
- 全局吞吐量最大。
Linux2.4以来,有O(N),O(1)、CFS(完全公平算法)调度器,O(N)和O(1)是根据算法复杂度来命名调度算法的,目前基本都使用CFS。
O(N)调度器
每个进程创建时,都会初始化该进程可执行的时间片数:counter,每次时钟中断counter–,counter == 0时就会换出cpu,然后重新遍历runqueue(存储当前所有RUNNING的进程)中动态优先级最高且有时间片的进程,由于采用轮训方式,所以为O(N) 复杂度。其动态优先级的计算逻辑如下:
实时进程prio = 1000 + p->rt_priority
// 20 - p->nice 是为了将nice变成单调递增(nice的取值[-20, 19])
普通进程prio = p->counter == 0 ? 0 : 20 - p->nice;
// 时间片counter的计算,counter。(*p)->counter >> 1为上一周期剩余counter打对折。
// priority直接作为进程时间片数量
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority
- epoch为一个周期,即all task都能得到cpu时间片的运行,避免饿死。
- 当prio大的进程counter != 0且state ==RUNNING时,prio小的进程在当前epoch内无法获得cpu时间片。进程的counter初始化为prio大小。
- counter == 0时,当前task的时间片用完,当前epoch无法再得到cpu时间。当所有RUNNING task的counter == 0时,重新分配所有task的counter。
- 有sleep task且counter != 0时,counter += 新counter + 剩余counter >>1,将剩余counter打对折后再加上新分配的counter
该调度器被2.4引入,但问题不少:
- 性能和扩展性低:进程切换和时间片分配都需要遍历所有进程,且该过程需要关中断,会阻塞所有中断和进程的运行。一旦进程数量变大,特别是SMP等多核结构下,性能下降明显。
- 等待时间长:如果总有新进程在1轮epoch快结束的时候加入,所有时间片用完的进程都需要等待。
- 对实时进程的支持不够:Linux2.4内核是非抢占的,当进程处于内核态时不会发生抢占,这对于真正的实时应用是不能接受的。
所以为了解决这些问题,引入O(1)调度器。
O(1) 调度器
实时进程prio = MAX_USER_RT_PRIO-1 - p->rt_priority; // 仅做归一化
// 精细化普通进程动态优先级计算,通能过bonus区分交互式进程
普通进程prio = max(100 , min(静态优先级 – bonus + 5) , 139))
// 时间片分配算法
静态优先级<120,time_slice = max((140-静态优先级)*20, MIN_TIMESLICE)
静态优先级>=120,time_slice = max((140-静态优先级)*5, MIN_TIMESLICE)
其中bonus是和sleep_avg(睡眠平均时间相关), sleep_avg越大,说明交互性越强,bouns为正,sleep_avg越小,说明占用cpu时间越长,可能为后台进程,作为惩罚bouns为负。
静态优先级值越小(优先级越大)time_slice(分配的时间片,等同于O(N)中的counter)越大。
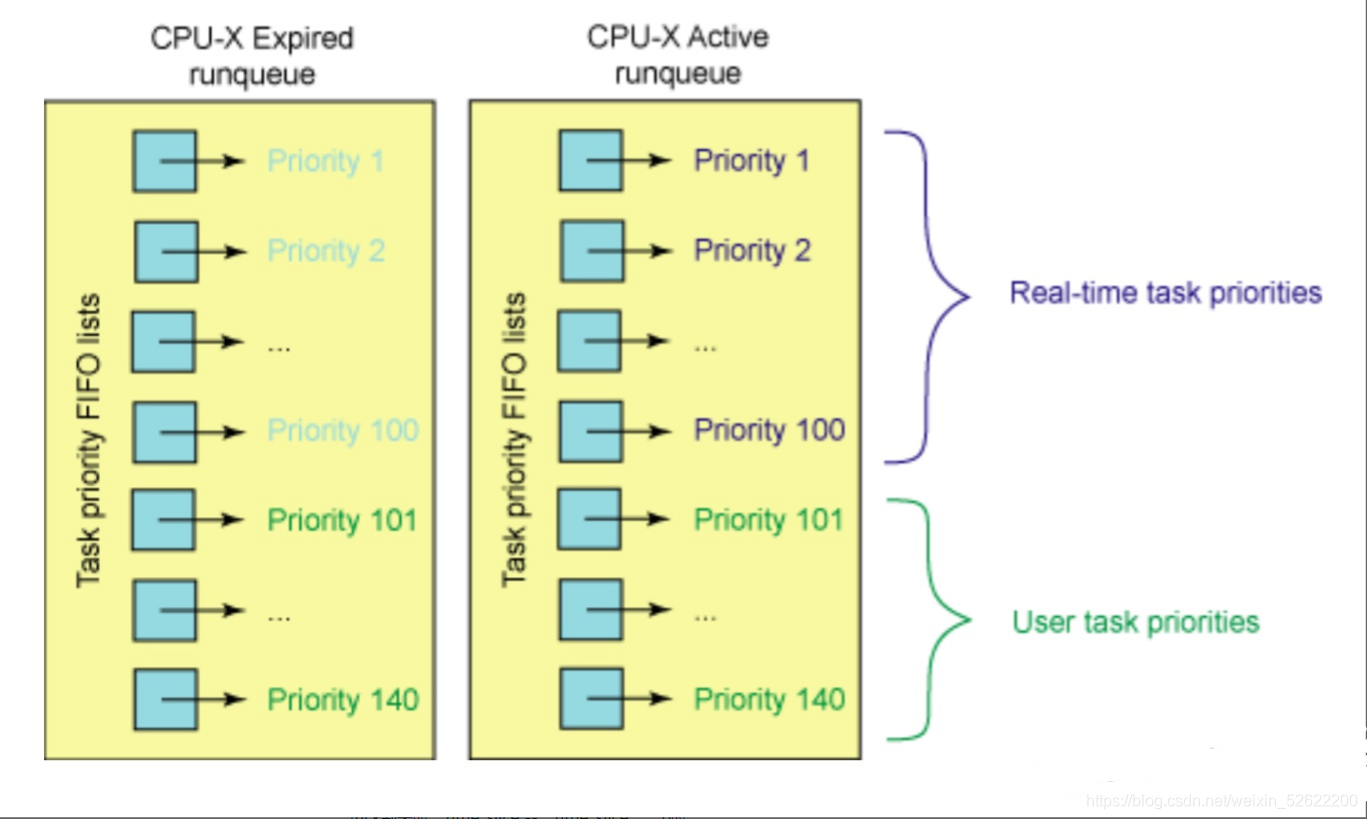
O(1)采用两个数组,Expired和Active,每个数据140个槽位,正好对应0 ~ 139优先级,对应静态优先级的进程加入对应槽位,在加上每个数组配一个bitmap,可以通过O(1)即找到当前数据中优先级最高的进程,且active数组确保其中所有进程有时间片。
当存在优先级更好且state == RUNNING的进程时,低优先级的进程无法获得cpu时间片。
当tick到来时,time_slice --,time_slice == 0时:
-
对于实时进程和交互式进程,重新计算其时间片并放入active数组,cpu时间超过阀值后还是会进入expire数组。实时进程可直接根据优先级判断,交互式进程的判断标准如下
动态优先级 ≤ 3*静态优先级/4 + 28
-
对于非实时、非交互式进程,重新计算其时间片并放入expire数组。
-
当active数组的进程都移动到了expire数组后,然后进行交互,expire数组变为active数组。
O(1)解决的问题:
- 在进程切换时,O(1)的查询算法效率远高于O(N),解决了服务器场景下的扩展性问题,不会随着进程的增加而增加调度时间。
- 在进程切换时,完成时间片的计算,避免O(N)整体重新计算时间片带来的开销,减少关中断时间和整体阻塞时间内。
- kernel 2.5引入O(1),同时支持内核态抢占,所以实时进程和交互式进程被内核态阻塞的时间更短。
O(1)调度器还存在的问题:
- 将优先级更高的进程分配更大的连续时间片,这是程序员YY的,貌似主观正确,但从用户看有意义吗?实际中,其实意义不大。将需求拆解下,高优先级通常出现于交互式进程,其大部分时间处于阻塞(等待用户输入),其需要的不是大量的cpu时间片,而是用户响应后立即获得cpu执行的权利。而低优先级的后台进程,恰恰需要大量的时间去计算,只是实时进程需要执行是能快速让出即可。
- 用户使用交互式程序时卡顿情况很多,原因是O(1)使用一个固定的公式(如上文动态优先级 ≤ 3*静态优先级/4 + 28)去YY该进程对于用户是否是交互式进程,导致现实中很多case覆盖不到。此时很多工程师希望修改交互进程的判断公式来改善,后来证明都无果。其实个人理解,问题的本质是用简单的归类方法去分析了线性分布的事物,比如A、B两个进程,其实很难说清楚A是交互进程、B为非交互进程,然后A、B执行调度时完全区别对待。正确的表达方式是A的交互性比B高,A调度的应优先于B,调度策略相同,但优先的粒度不同而已。
- time_slice粒度粗,如果tick间隔是10ms,则1个time_slice则代表10ms。只要高优先级的进程还有1个time_slice,低优先级的进程有N多time_slice都得不到执行。
CFS调度器
公平调度器的主要设计思想:抛弃时间片,不事先分配时间片,不去YY该进程需要多少时间片。抛弃动态优先级的思路,仅使用静态优先级,维护完全公平。不去主观的将交互式、非交互式进程进行分类,维持优先级的线性分布。
公平调度的主要思想如下:
// ideal_time:每个进程应该运行的时间
// sum_runtime:运行队列中所有任务运行完一遍的时间
// se.weight:当前进程的权重
// cfs.weight:整个cfs_rq的总权重
ideal_time = sum_runtime *se.weight/cfs_rq.weight
首先根据nice值转为weight,假设现在系统有A,B,C三个进程,A.weight=1,B.weight=2,C.weight=3,那么我们可以计算出整个公平调度队列的总权重是cfs_rq.weight = 6,那么A、B、C占用的时时间片分别为1/6、2/6、3/6。
如何实现呢?CFS使用虚拟运行时间记录每个进程过往运行的时间,每次调度时,选用虚拟运行时间最小的进程运行,永远向vruntime(进程1) = vruntime(进程2) = vruntime(进程3)…的理想态靠拢。vruntime = 实际运行时间 * 系数,优先级高的进程系数小,使得vruntime的增长率小,从而得到比低优先级进程更靠前的调度次序和更多的cpu时间。
vruntime(虚拟运行时间) += delta_exec(实际运行时间) * NICE_0_LOAD / weight
// nice -> 权重对应数组,nice[-20, 19]应对sched_prio_to_weight[0, 39]
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
其中weight和NICE_0_LOAD都是通过prio_to_weight数组进行转换的,nice越大(优先级越小),weight值越小。NICE_0_LOAD是nice=0的权重。从注释中可以看出,nice相差1,cpu time应该相差10%,固推导出weight之间的倍数是1.25。比如系统仅有A、B两个进程,cpu总共有20ms的时间片,nice(A)=0,nice(B)=0,weight(A)=1024,weight(B)=1024,同时满足vruntime(A) = vruntime(B),则delta_exec(A) = 10,delta_exec(B) = 10。如果此时nice(B)++,则B的cpu time应该减少10%,weight(B)=820,同时还要满足vruntime(A) = vruntime(B),则delta_exec(A)=11,delta_exec(B) = 9,B相比之前减少10%的cpu运行时间。
进程的权重存储在调度实体sched_entity.load_weight中,避免每次都计算。
看起来cfs很美好?但现实情况是很复杂的:
- 新fork的进程vruntime根据sched_child_runs_first,sched_features.START_DEBIT,以cfs_rq.min_vruntime为基础来设置。否则新进程的vruntime=0,在很长一段时间内,老进程无法得到cpu时间。
sched_features // 控制调度器特性的开关,每个bit表示调度器的一个特性
sched_features.START_DEBIT //新进程的第一次运行要有延迟。若设置该bit,则新进程的vruntime会在min_vruntime的基础上再增大
sched_child_runs_first //fork后子进程先于父进程运行.若是父进程的vruntime更小,就对换父、子进程的vruntime,保证子进程先运行
- 休眠进程被唤醒时会补偿vruntime,逻辑如下。目标是尽量让被唤醒的进程(交互式进程)尽快得到cpu时间,同时避免睡眠长时间的进程长时间占用cpu。
vruntime = max(se->vruntime, cfs_cq->min_vruntime - sysctl_sched_latency >> 1)
如果系统中长时间sleep的是非交互式进程(如定时任务),则不希望被唤醒时进行抢占,可通过以下标志位关掉唤醒时抢占或调高唤醒进程抢占的门槛。
sched_features.WAKEUP_PREEMPT // 禁止唤醒时抢占
sched_wakeup_granularity_ns // 当前进程vruntime - 唤醒进程vruntime > sched_wakeup_granularity_ns才允许唤醒抢占
- 在cfs_rq.left_most(vruntime最小),也不一定会被调度。比如A、B两个进程vruntime相同,A运行1ms(由于前一进程sleep所以A被调度),tick来了,此时A
vruntime大于B vruntime,此时如果调度会有很大的开销。所以在来个配置参数:sched_min_granularity_ns,如果正在运行的进程运行时间小于sched_min_granularity_ns是不允许调离cpu的。 - 进程从一个cpu调度到另一个cpu时,会根据新cpu的cfs_rq.min_vruntime做调整,以保证到新cpu不会占太大便宜。uti作为是调离当前cpu时,vruntime
-= 当前cfs_rq.min_vruntime,调入新cpu时,vruntime += 新cfs_rq.min_vruntime。
7、调度数据结构
受限于篇幅,此处只分析CFS调度器用到的数据结构。
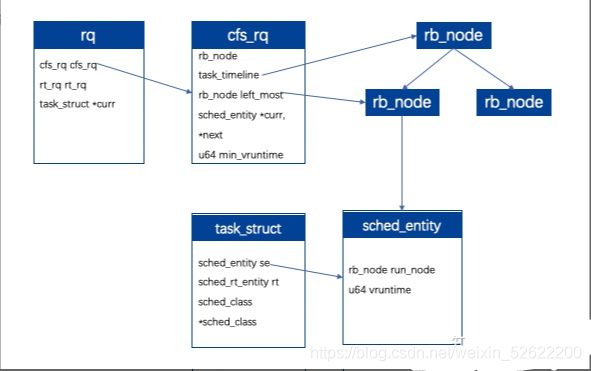
对于每个cpu,都有runqueue(struct rq)保存进程的调度队列,cfs和实时进程使用两个队列。其中cfs_rq中存储了rb_node构成的红黑树,其根据vruntime进行排序,cfs_rq.left_most保存了最左边rb_node,即当前vruntime最小的节点,即下一次调度可能换入cpu。每一个rb_node关联一个sched_entity,同时进程描述符task_struct也唯一有用1个sched_entity。当每次clock_tick到来时,首先调用update_time更新vruntime,然后选择left_most->sched_entity->task_struct进入cpu运行。
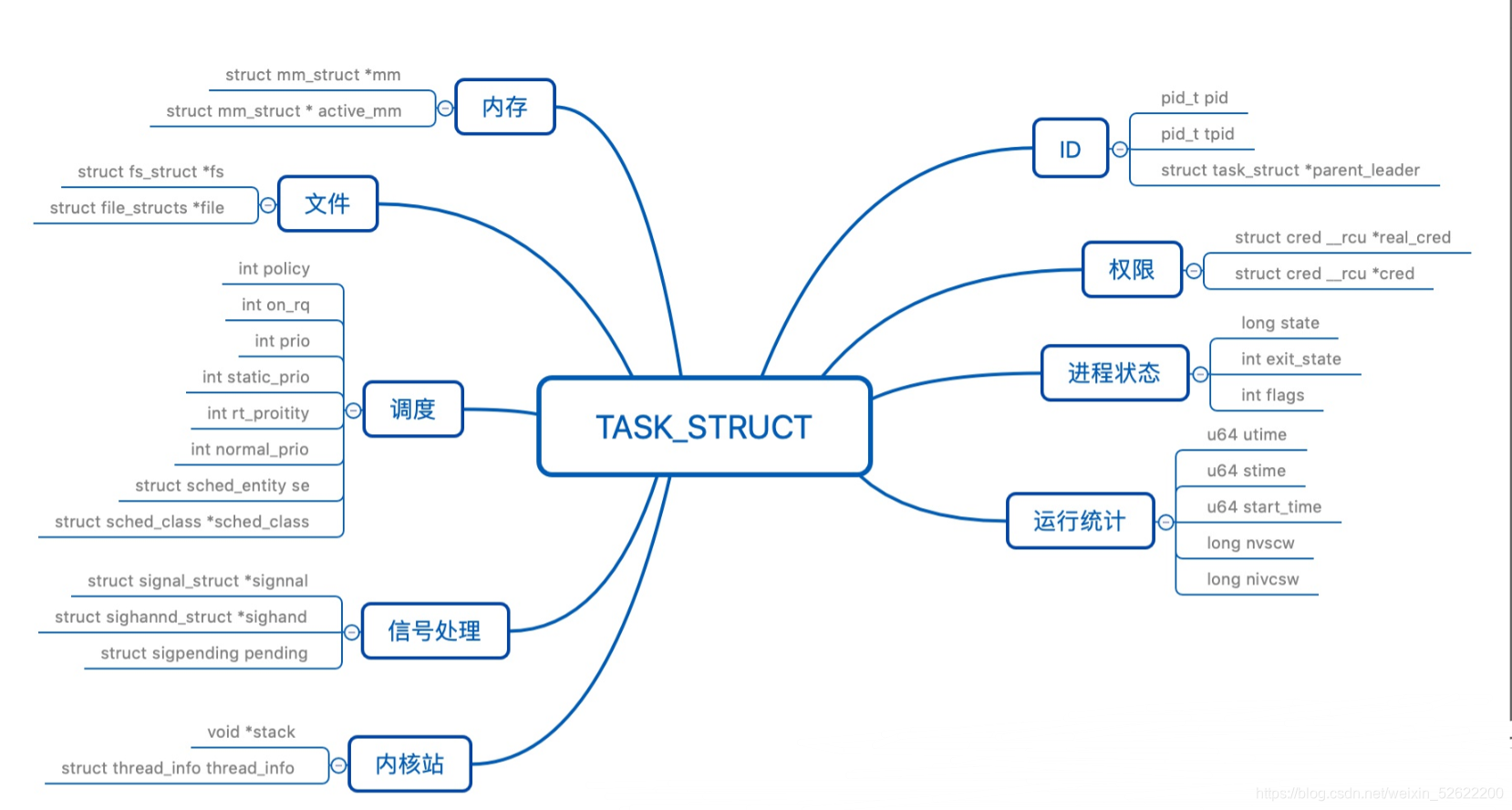
附:
task_struct结构:
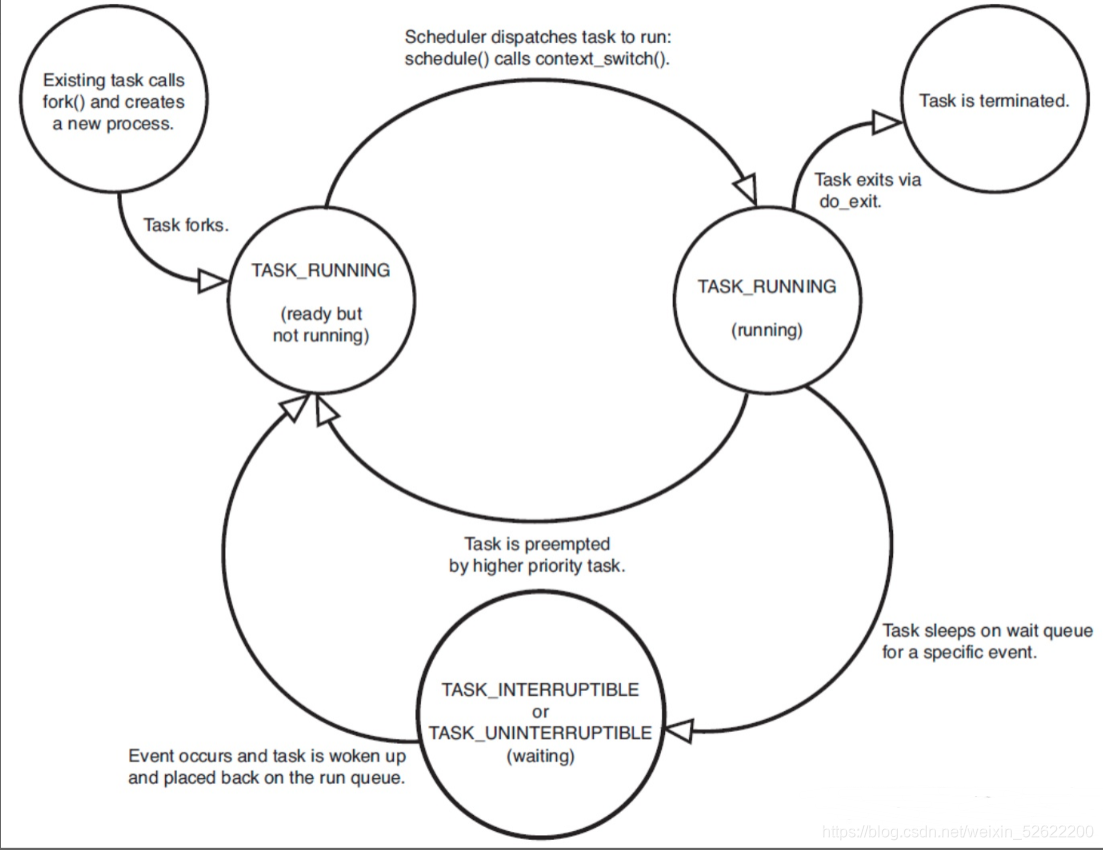
task_struct.state:进程状态机