进程四要素
要给进程下一个确切的定义不是件容易的事情。不过,一般来说linux系统中的进程都具备下列诸要素:
- 有一段程序供其执行,就好像一场戏要有个剧本一样。这段程序不一定是进程所专有,可以与其他进程共用,就好像不同剧团的许多场演出可以共用一个剧本一样。
- 有起码的私有财产,这就是进程专用的系统堆栈空间。
- 有户口,这就是在内核中的一个task_struct数据结构,操作系统教科书中常称为进程控制块。有了这个数据结构,进程才能成为内核调度的一个基本单位接受内核的调度。同时,这个结构又是进程的财产登记卡,记录着进程所占用的各项资源。
- 有独立的存储空间,意味着拥有专有的用户空间:进一步,还意味着除前述的系统空间堆栈外还有其专用的用户空间堆栈。注意,系统空间是不能独立的,任何进程都不可能直接(不通过系统调用)改变系统空间的内容(除其本身的系统空间堆栈以外)。
这四条都是必要条件,缺了其中任何一条就不称其为进程。如果只具备乐前面三条而缺第四条,那就称为线程。特别地,如果完全没有用户空间,就称为内核线程(kernel thread);而如果共享用户空间则就称为用户线程。在不致引起混淆的场合,二者也都往往简称为线程。读者在内存管理中看到过的kswapd,就是一个内核线程。读者要注意,不要把这里的线程与有些系统中在用户空间的同一进程内实现到的线程相混淆。那种线程显然不拥有独立、专用的系统堆栈,也不作为一个调度单位直接受内核调度。而且,既然linux内核提供了对线程的支持,一般也就没有必要再进程内部,即用户空间中自行实现线程。
另一方面,进程与线程的区分也不是十分严格的,一般在讲到进程时常常也包括了线程。事实上,在linux(以及Unix)系统中,许多进程在诞生之初都与其父进程共用一个存储空间,所以严格说来还是线程:但是子进程可以建立起自己的存储空间,并与父进程分道扬镳,成为真正意义上的进程。再说,线程也有pid,也有task_struct结构,所以这两个词在使用中有时候并不严格加以区分,要根据上下文理解其含义。
还有,在linux系统中进程(process)和任务(task)是同一个意思,在内核的代码中也常常混用这两个名词和概念。例如,每一个进程都要有一个task_struct数据结构,而其号码却又是pid;唤醒一个睡眠进程的函数名为wake_up_process。之所以有这样的情况是因为linux源自Unix和i386系统结构,而Unix中的进程在Intel的技术资料中则称为任务(严格说来有点区别,但是对linux和Unix的实现来说是一码事)。
linux系统运行时的第一个进程时在初始化及恩典捏造出来的。而此后的进程或线程则都是由一个业已存在的进程像细胞分裂那样通过系统调用复制出来的,称为fork(分叉)或clone(克隆)。
除上述最起码的财产,即task_struct数据结构和系统堆栈外,一个进程还要有些附加的资源。例如,上面说过,独立的存储空间意味着进程拥有用户空间,因此,就要有用于虚存管理的mm_struct数据结构以及下属的vm_area_struct数据结构,以及相应的页面目录和页面表。但那些都是第二位的,从属于task_struct的资源,而task_struct数据结构则在这方面起着登记卡的作用。至于进程的具体实现,则在相当程度上取决于宿主CPU的系统结构。
在转入详细介绍进程的各个要素之前,我们先讲一下i386系统结构所提供的进程管理机制以及linux内核对这种机制的特殊运用和处理。读者可以结合内存管理的有关内容阅读。
Intel在i386系统结构的设计中考虑到了进程(任务)的管理和调度,并从硬件上支持任务间的切换。为此目的,Intel在i386系统结构中增设了另一种新的段,叫做任务状态段TSS。一个TSS虽说像代码段、数据段等一样,也是一个段,实际上却只是一个104字节的数据结构,或曰控制块,用以记录一个任务的关键性的状态信息,包括:
- 任务切换前夕(也就是切入点上)该任务各通用寄存器的内容。
- 任务切换前夕(切入点上)该任务各个段寄存区(包括ES、CS、SS、DS、FS和ES)的内容。
- 任务切换前夕(切入点上)该任务EFLAGS寄存器的内容。
- 任务切换前夕(切入点上)该任务指令地址寄存器EIP的内容。
- 指向前一个任务的TSS结构的段选择码。当前任务执行IRET指令时,就返回到由这个段选择码所指的(TSS所代表的)任务(返回地址则由堆栈决定)。
- 该任务的LDT段选择码,它指向任务的LDT。
- 控制寄存器CR3的内容,它指向任务的页面目录。
- 三个堆栈指针,分别为当前任务运行于0级、1级和2级时的堆栈指针,包括堆栈段寄存器SS0、SS1和SS2,以及ESP0、ESP1和ESP2的内容。注意,在CPU中只要一个SS和一个ESP寄存器,但是CPU在进入新的运行级别时会自动从当前任务的TSS中装入相应SS和ESP的内容,实现堆栈的切换。
- 一个用于程序跟踪的标志位T。当T标志位为1时,CPU就会在切入该进程时产生一次debug异常,这样就可以在debug异常的服务程序中安排所需的操作,如加以记录、显示等等。
- 在一个TSS段中,除了基本的104字节的TSS结构以外,还可以有一些附加的信息。其中之一是表示I/O权限的位图。i386系统结构允许I/O指令在比0级更低的状态下执行,也就是说可以将外设驱动实现于一个既非内核(0级)也非用户(3级)的空间中,这个位图就是用于这个目的的。另一个是中断重定向位图,用于vm86模式。
像其他的段一样,TSS也要在段描述表中有个表项。不过TSS的描述项只能在GDT中,而不能放在任何一个LDT中或IDT中。如果通过一个段选择项访问一个TSS,而选择项中的T1标志位为1(表示使用LDT),就会产生一次总保护GP异常。TSS描述项的结构与其他的段描述项基本相同(参看内存管理),但有一个B(busy)标志位,表示相应TSS所代表的任务是否正在运行或者正被中断。
另外,CPU中还增设了一个任务寄存器TR,指向当前任务的TSS。相应地,还增加了一条指令LTR,对TR寄存器进行装入操作。像CS和DS一样,TR也有一个不可见的部分,每当将一个段选择码装入TR中时,CPU就自动找到所选择的TSS描述项并将其装入到TR中的不可见部分,以加速以后对该TSS段的访问。
还有,在IDT表中,除中断门、陷阱门和调用门外,还定义了一种任务门。任务门中包含着一个TSS段选择码。当CPU因中断而穿过一个任务门时,就会将任务门中的段选择码自动装入TR,使TR指向新的TSS,并完成任务切换。CPU还可以通过JMP和CALL指令实现任务切换,当跳转或调用的目标段(代码段)实际上指向GDT表中的一个TSS描述项时,就会引起一次任务切换。
Intel的这种设计确实很周到,也为任务切换提供了一个非常简洁的机制。但是,请读者注意,由CPU自动完成的这种任务切换并不是像读者可能误以为的那样只相当于一条指令。实际上,i386的系统结构基本上是CISC的,而通过JMP指令或CALL指令(或中断)完成任务切换的过程可以说是典型的、甚至是几段的复杂指令执行过程,其执行过程长达300多个CPU时钟周期(一条POP指令占用12个CPU时钟周期)。在执行的过程中,CPU实际上作了所有可能需要做的事情,而其中有的事情在一定的条件下本来是可以简化的,有的事情则可能在一定的条件下应该按不同的方式组合。所以,i386 CPU所提供的这种任务切换机制就好像是一种高级语言的成分,你固然可以用它,但对操作系统的设计和实现而言,你往往会选择汇编语言来实现这个机制,已达到更高的效率和更大的灵活性。更重要的是,任务的切换往往不是孤立的,常常跟其他的操作联系在一起。例如,在Unix和linux系统中,任务切换就只发生于系统空间,因而与系统调用和中断密切联系在一起,并且有许多操作可以合并。
就如对i386所提供的许多其他功能一样,读者将会看到,linux内核实际上并不使用i386 CPU硬件提供的任务切换机制。不过,由于i386 CPU要求软件设置TR及TSS,内核中便只好走过场地设置好TR及TSS以满足CPU的要求。但是,内核中并不使用任务门、也不允许使用JMP或CALL指令实施任务切换。内核只是在初始化阶段设置TR,使之指向一个TSS,从此以后就再不改变TR的内容了。也就是说,每个CPU(如果有多个CPU的话)在初始化以后的全部运行过程中永远各自使用同一个TSS。同时,内核也不依靠TSS保存每个进程切换时的寄存器副本,而是将这些寄存器的副本保存在各个进程自己的系统空间堆栈中,就如读者在“中断、异常和系统调用”系列博客中所看到的那样。
这样一来,TSS中的绝大部分内容已经失去了原来的意义。可是,在“中断、异常和系统调用”中讲过,当CPU因中断或系统调用而从用户空间进入系统空间时,会由于运行级别的变化而自动更换堆栈。而新的堆栈指针,包括堆栈寄存器SS的内容和堆栈指针寄存器ESP的内容,则取自当前任务的TSS。由于在linux中只使用两个运行级别,即0级和3级,所以TSS中为另两个级别(即1级和2级)设置的堆栈指针副本也失去了意义。于是,对于linux内核来说,TSS中有意义的就只剩下了0级的堆栈指针,也就是SS0和ESP0两项了。Intel原来的意图是让TR的内容,随着不同的TSS,随着任务的切换而走马灯似的转。可是在linux内核中却变成了“铁打的营盘流水的兵”:就一个TSS,像一座营盘,一经建立再不动了。而里面的内容,也就是当前任务的系统堆栈指针,则随着进程的调度切换而流水似的变动。这里的原因在于:改变TSS中SS0和ESP0所花的开销比通过装入TR以更换一个TSS要小得多。因此,在linux内核找中,TSS并不是属于某个进程的资源,而是全局性的公共资源。在多处理器的情况下,尽管内核中却是有多个TSS,但是每个CPU仍旧只有一个TSS,一经装入就不再改了。
那么,这个TSS是什么样的呢?请看include/asm-i386/processor.h中对INIT_TSS的定义:
#define INIT_TSS { \
0,0, /* back_link, __blh */ \
sizeof(init_stack) + (long) &init_stack, /* esp0 */ \
__KERNEL_DS, 0, /* ss0 */ \
0,0,0,0,0,0, /* stack1, stack2 */ \
0, /* cr3 */ \
0,0, /* eip,eflags */ \
0,0,0,0, /* eax,ecx,edx,ebx */ \
0,0,0,0, /* esp,ebp,esi,edi */ \
0,0,0,0,0,0, /* es,cs,ss */ \
0,0,0,0,0,0, /* ds,fs,gs */ \
__LDT(0),0, /* ldt */ \
0, INVALID_IO_BITMAP_OFFSET, /* tace, bitmap */ \
{~0, } /* ioperm */ \
}这里把系统中第一个进程的SS0设置成__KERNEL_DS,而把ESP0设置成指向&init_stack的顶端。对INIT_TSS的引用则在kernel/init_task.c中给出:
/*
* per-CPU TSS segments. Threads are completely 'soft' on Linux,
* no more per-task TSS's. The TSS size is kept cacheline-aligned
* so they are allowed to end up in the .data.cacheline_aligned
* section. Since TSS's are completely CPU-local, we want them
* on exact cacheline boundaries, to eliminate cacheline ping-pong.
*/
struct tss_struct init_tss[NR_CPUS] __cacheline_aligned = { [0 ... NR_CPUS-1] = INIT_TSS };结构数组init_tss的大小为NR_CPUS,即系统中CPU的个数。每个TSS的内容都相同,都由INIT_TSS定义。此外,每个TSS的起始地址都与高速缓存中的缓冲行对齐。
数据结构tss_struct反映了TSS段的结构:
struct tss_struct {
unsigned short back_link,__blh;
unsigned long esp0;
unsigned short ss0,__ss0h;
unsigned long esp1;
unsigned short ss1,__ss1h;
unsigned long esp2;
unsigned short ss2,__ss2h;
unsigned long __cr3;
unsigned long eip;
unsigned long eflags;
unsigned long eax,ecx,edx,ebx;
unsigned long esp;
unsigned long ebp;
unsigned long esi;
unsigned long edi;
unsigned short es, __esh;
unsigned short cs, __csh;
unsigned short ss, __ssh;
unsigned short ds, __dsh;
unsigned short fs, __fsh;
unsigned short gs, __gsh;
unsigned short ldt, __ldth;
unsigned short trace, bitmap;
unsigned long io_bitmap[IO_BITMAP_SIZE+1];
/*
* pads the TSS to be cacheline-aligned (size is 0x100)
*/
unsigned long __cacheline_filler[5];
};
前面讲过,每个进程都有一个task_struct数据结构和一片用作系统空间堆栈的存储空间。这二者缺一不可,又有紧密的联系,所以在物理存储空间中也连在一起。内核在为每个进程分配一个task_struct结构时,实际上分配两个连续的物理页面(共8190字节)。这两个页面的底部用作进程的task_struct结构,而在结构的上面就用作进程的系统空间堆栈,见下图:

数据结构task_struct的大小约1K字节,所以进程系统空间堆栈的大小约7K字节。注意,系统空间堆栈的空间不像用户空间堆栈那样可以在运行时动态地扩展(见内存管理系列博客),而是静态地确定了的。所以,在中断服务程序、内核软中断服务程序以及其他设备驱动程序的设计中,应注意不能让这些函数嵌套太深,同时,在这些函数中也不宜使用太多、太大的局部变量。像下面程序中这样的局部变量就应该避免:
int something()
{
char buf[1024];
.....
}这里的buf是局部变量,因为是在堆栈中,它一下子就用掉了1K字节,显然是不合适的。
进程task_struct结构以及系统空间堆栈的这种特殊安排,决定了内核中一些宏操作的定义:
#define THREAD_SIZE (2*PAGE_SIZE)
#define alloc_task_struct() ((struct task_struct *) __get_free_pages(GFP_KERNEL,1))
#define free_task_struct(p) free_pages((unsigned long) (p), 1)THREAD_SIZE定义为两个页面,表示每个内核线程(一个进程必定同时又是一个内核线程)的这两项基本资源所占的物理存储空间大小。至于alloc_task_struct的实现,读者也许会想象成这样:
struct task_struct *t = kmalloc(sizeof(struct task_struct));实际上却不是,这是因为所分配的并不仅仅是task_struct数据结构的大小,而是连同系统空间堆栈所需的空间一起分配。注意,__get_free_pages中第二个参数的值1表示2^1,也就是两个页面。
当进程在系统空间运行时,常常需要访问当前进程自身的task_struct数据结构。为此目的,内核中定义了一个宏操作current,提供指向当前进程的task_struct结构的指针:
static inline struct task_struct * get_current(void)
{
struct task_struct *current;
__asm__("andl %%esp,%0; ":"=r" (current) : "0" (~8191UL));
return current;
}
#define current get_current()我们在内存管理中跳过了这段程序的解释,因为那时还没有讲到进程的系统空间堆栈与其task_struct结构之间的关系。
task_struct的定义如下:
struct task_struct {
/*
* offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long flags; /* per process flags, defined below */
int sigpending;
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
int lock_depth; /* Lock depth */
/*
* offset 32 begins here on 32-bit platforms. We keep
* all fields in a single cacheline that are needed for
* the goodness() loop in schedule().
*/
long counter;
long nice;
unsigned long policy;
struct mm_struct *mm;
int has_cpu, processor;
unsigned long cpus_allowed;
/*
* (only the 'next' pointer fits into the cacheline, but
* that's just fine.)
*/
struct list_head run_list;
unsigned long sleep_time;
struct task_struct *next_task, *prev_task;
struct mm_struct *active_mm;
/* task state */
struct linux_binfmt *binfmt;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
int dumpable:1;
int did_exec:1;
pid_t pid;
pid_t pgrp;
pid_t tty_old_pgrp;
pid_t session;
pid_t tgid;
/* boolean value for session group leader */
int leader;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr;
struct list_head thread_group;
/* PID hash table linkage. */
struct task_struct *pidhash_next;
struct task_struct **pidhash_pprev;
wait_queue_head_t wait_chldexit; /* for wait4() */
struct semaphore *vfork_sem; /* for vfork() */
unsigned long rt_priority;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer;
struct tms times;
unsigned long start_time;
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups;
gid_t groups[NGROUPS];
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
/* limits */
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* file system info */
int link_count;
struct tty_struct *tty; /* NULL if no tty */
unsigned int locks; /* How many file locks are being held */
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* signal handlers */
spinlock_t sigmask_lock; /* Protects signal and blocked */
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty */
spinlock_t alloc_lock;
};
先把结构中的几个特别重要的成分介绍一下,其余则留待以后用到的时候再来介绍。这些成分大体可以分成状态、性质、资源和组织等几大类。
第281行的state表示进程当前的运行状态,具体定义如下:
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_ZOMBIE 4
#define TASK_STOPPED 8
状态TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE均表示进程处于睡眠状态。但是,TASK_UNINTERRUPTIBLE表示进程处于深度睡眠而不受信号的干扰,而TASK_INTERRUPTIBLE则可以因信号的到来而被唤醒。内核中提供了不同的函数,让一个进程进入不同的深度的睡眠或将进程从睡眠中唤醒。具体的说,函数sleep_on和wake_up用于深度睡眠,而interruptible_sleep_on和wake_up_interruptible则用于浅度睡眠。深度睡眠一般只用于临界区和关键性的部分,而可中断的睡眠那就是通用的了。特别,当进程在阻塞性(blocking)的系统调用中等待某一事件发生时,应该进入可中断睡眠而不应深度睡眠。例如,当进程等待操作人员按某个键的时候,就不应该进入深度睡眠,否则就不能对别的事件做出反应,别的进程就不能通过发一个信号来杀掉这个进程了。还应该注意,这里的INTERRUPTIBLE或UNINTERRUPTIBLE跟中断毫无关系,而只是说睡眠能够因其他事件而中断,即唤醒。不过,所谓 其他事件主要是信号,而信号的概念实际上与中断的概念是相同的,所以这里所谓INTERRUPTIBLE也是指这种软中断而言。
TASK_RUNNING状态并不是表示一个进程正在执行中,或者说这个进程就是当前进程,而是表示这个进程可以被调度执行而成为当前进程。。当进程处于这样的可执行(或就绪)状态时,内核就将该进程的task_struct结构通过其队列头run_list(见309行)挂入一个运行队列。
TASK_ZOMBIE状态表示进程已经去世(exit)而户口尚未注销。
TASK_STOPPED主要用于调试目的。进程接收到一个SIGSTOP信号后就将运行状态改成TASK_STOPPED而进入挂起状态,然后在接收到一个SIGCONT信号时又将恢复继续运行。
第282行的flags也是反映进程状态的信息,但并不是运行状态,而是与管理有关的其他信息。这些标志位定义如下:
/*
* Per process flags
*/
#define PF_ALIGNWARN 0x00000001 /* Print alignment warning msgs */
/* Not implemented yet, only for 486*/
#define PF_STARTING 0x00000002 /* being created */
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_VFORK 0x00001000 /* Wake up parent in mm_release */
#define PF_USEDFPU 0x00100000 /* task used FPU this quantum (SMP) */代码作者所加的注释已经说明了各个标志位的作用,这里就不多说了。
除上述的state和flags以外,反映当前状态的成分还有下面这么一些:
sigpending--表示进程收到了信号但尚未处理。与这个标志相联系的是与信号队列有关sigqueue、sig等指针以及sigmask_lock等成分。后面的“进程间通信“中的信号博客和后面的有关叙述。
counter--与调度有关,详见“进程的调度与切换”博客。
need_resched--与调度有关,表示CPU从系统空间返回用户空间前夕要进行一次调度。
上列当前状态都反映了进程的动态特征,还有一些则反映静态特征:
addr_limit虚拟地址空间的上限。对进程而言是其用户空间的上限,所以是0xbfffffff;对内核线程而言则是系统空间的上限,所以是0xffffffff。
personality--由于Unix有许多不同的版本和变种,应用程序也就有了适用范围,例如Unix SVR4的应用程序就未必与为linux开发的其他软件完全兼容。所以根据执行程序的不同,每个进程都有其个性。下面看下定义的有关常数:
/* Flags for bug emulation. These occupy the top three bytes. */
#define STICKY_TIMEOUTS 0x4000000
#define WHOLE_SECONDS 0x2000000
#define ADDR_LIMIT_32BIT 0x0800000
/* Personality types. These go in the low byte. Avoid using the top bit,
* it will conflict with error returns.
*/
#define PER_MASK (0x00ff)
#define PER_LINUX (0x0000)
#define PER_LINUX_32BIT (0x0000 | ADDR_LIMIT_32BIT)
#define PER_SVR4 (0x0001 | STICKY_TIMEOUTS)
#define PER_SVR3 (0x0002 | STICKY_TIMEOUTS)
#define PER_SCOSVR3 (0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS)
#define PER_WYSEV386 (0x0004 | STICKY_TIMEOUTS)
#define PER_ISCR4 (0x0005 | STICKY_TIMEOUTS)
#define PER_BSD (0x0006)
#define PER_SUNOS (PER_BSD | STICKY_TIMEOUTS)
#define PER_XENIX (0x0007 | STICKY_TIMEOUTS)
#define PER_LINUX32 (0x0008)
#define PER_IRIX32 (0x0009 | STICKY_TIMEOUTS) /* IRIX5 32-bit */
#define PER_IRIXN32 (0x000a | STICKY_TIMEOUTS) /* IRIX6 new 32-bit */
#define PER_IRIX64 (0x000b | STICKY_TIMEOUTS) /* IRIX6 64-bit */
#define PER_RISCOS (0x000c)
#define PER_SOLARIS (0x000d | STICKY_TIMEOUTS)exec_domain--除了personality以外,应用程序还有一些其他的版本间的差异,从而形成了不同的执行域。这个指针就指向描述本进程所属执行域的数据结构。
binfmt--应用程序的文件格式,如a.out、ELF等。后面讲解exec系统调用会讲。
exit_code、exit_signal、pdeath_signal--详见“系统调用exit与wait4”。
pid--进程号。
pgrp、session、leader--当一个用户登录到系统时,就开始了一个进程组(session),此后创建的进程都属于这同一个session。此外,若干进程可以通过管道组合在一起,如ls |wc-l,从而形成进程组。详见exec系统调用。
rt_priority--实时优先级别,详见”进程的调度与切换”。
policy--适用于本进程的调度策略,详见“进程的调度与切换”。
parent_exec_id、self_exec_id--与进程组(session)有关,见“系统调用exit与wait4”
uid、euid、suid、fsuid、gid、egid、sgid、fsgid--主要与文件操作权限有关,见“文件系统”相关博客。
cap_effective,、cap_inheritable,、cap_permitted--一般进程都不能为所欲为,而是各自被赋予了各种不同的权限。例如,一个进程是否可以通过系统调用ptrace跟踪另一个进程,就是由该进程是否具有CAP_SYS_PTRACE授权决定的;一个进程是否有权重重新引导操作系统,则取决于改就能成是否具有CAP_SYS_BOOT授权。这样,就把进程的各种权限分细了,而不再是笼统的取决于一个进程是否是特权用户进程。每种权限由一个标志位代表,内核中提供了一个inline函数capable,用来检验当前进程是否具有某种权限。如capable(CAP_SYS_BOOT),就是检查当前进程是否有权重重引导操作系统(返回非0表示有权)。值得注意的是,对操作权限的这种划分与文件访问权限结合在一起,形成了系统安全性的基础。在现今的网络时代,这种安全性正在变得越来越重要,而这方面的研究与发展也是一个重要的课题。
user--指向一个user_struct结构,该数据结构代表着进程所属的用户。注意这跟Unix内核中每个进程的user结构时两码事。linux内核中的user结构是非常简单的,详见“系统调用fork”博客。
rlim--这是一个结构数组,表明进程对各种资源的使用数量所受的限制。读者在文件系统的博客中已经看到过其应用。数据结构rlimit的定义如下:
struct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
};对i386环境而言,进程可用资源共有RLIM_NLIMITS项,即11项。每种资源的限制在下面给出:
#define RLIMIT_CPU 0 /* CPU time in ms */
#define RLIMIT_FSIZE 1 /* Maximum filesize */
#define RLIMIT_DATA 2 /* max data size */
#define RLIMIT_STACK 3 /* max stack size */
#define RLIMIT_CORE 4 /* max core file size */
#define RLIMIT_RSS 5 /* max resident set size */
#define RLIMIT_NPROC 6 /* max number of processes */
#define RLIMIT_NOFILE 7 /* max number of open files */
#define RLIMIT_MEMLOCK 8 /* max locked-in-memory address space */
#define RLIMIT_AS 9 /* address space limit */
#define RLIMIT_LOCKS 10 /* maximum file locks held */
#define RLIM_NLIMITS 11
还有一些成分代表进程所占用和使用的资源,如mm、active_mm、fs、files、real_timer、times、it_real_value等,对这些成分都有专门的博客加以介绍,这里就不重复了。
至于统计信息,则主要有per_cpu_utime和per_cpu_stime两个数组,表示该进程在各个处理器上(在多处理器SMP结构中,一个进程可以受调度在不同的处理器上运行)运行于用户空间和系统空间的累计时间。而数据结构times中则是对这些时间的汇总。此外,还有对发生页面异常次数的统计min_flt、maj_flt以及换入、换出的次数nswap等。当一个进程通过do_exit结束其生命时,该进程的有关统计信息要合并到父进程中,所以对每项统计信息都有一项相应到的总计信息,如相对于min_flt有cmin_flt,在数据结构times中相对于tms_utime有tms_cutime等。
最后,每一个进程都不是鼓励地存在与系统中,而总是根据不同的目的、关系和需要与其他的进程相联系。从内核的角度看,则是要按不同的目的和性质将每个进程纳入不同的组织中。第一个组织是由每个进程的家庭和社会关系形成的宗族或家谱。这是一种树型的组织,通过指针p_opptr,、p_pptr,、p_cptr,、p_ysptr,、p_osptr构成。其中p_opptr和p_pptr指向父进程的task_struct结构,p_cptr指向最年轻的子进程,而p_ysptr和p_osptr则分别指向其哥哥和弟弟,从而形成一个子进程链。这些指针确定了一个进程在其宗族中的上、下、左、右关系,详见后面的对fork和exit的叙述。
下图就是这个进程家谱的示意图:
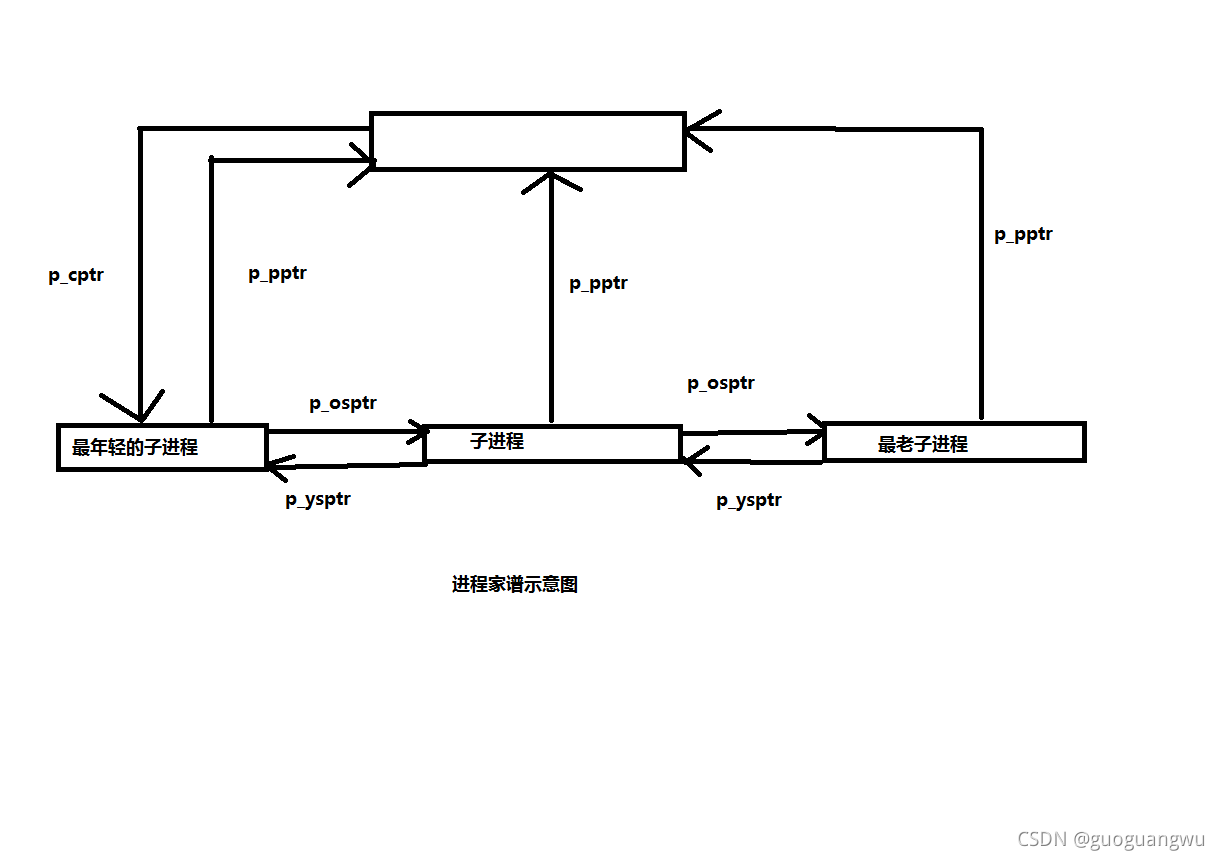
这个组织虽然确定了每个进程的宗族关系,涵盖了系统中所有的进程,但是,要在这个组织中根据进程号pid找到一个进程却非易事。进程号的分配是相当随机的,在进程号中并不包含任何可以用来找到一个进程的路径信息,而给定一个进程号要求找到该进程的task_struct结构却又是常常要用到的一个操作。于是,就有了第二个组织,那就是一个以杂凑表为基础的进程队列的阵列。当给定一个pid要找到该进程时,先对pid施行杂凑计算,以计算的结果为下标在杂凑表中找到一个队列,再顺着该队列就可以较容易地找到特定的进程了。杂凑表pidhash定义如下:
struct task_struct *pidhash[PIDHASH_SZ];
杂凑表的大小PIDHASH_SZ 定义如下:
#define PIDHASH_SZ (4096 >> 2)
杂凑表的大小为1024,。由于每个指针的大小是4 个字节,所以整个杂凑表(不包含各个队列)正好占一个页面。每个进程的task_struct数据结构都通过其pidhash_next和pidhash_pprev两个指针链入到杂凑表中的某个队列中,同一队列中所有进程的pid都具有相同的杂凑值。由于杂凑表的使用,要找到pid为某个给定值的进程就很迅速了。
当内核需要对每一个进程做点什么事情时,还需要将系统中所有的进程都组织成一个线性的队列,这样就可以通过一个简单的for循环或while循环遍历所有进程的task_struct结构。所以,第三个组织就是这么一个线性队列。系统中第一个建立的进程为init_task,这个进程就是所有进程的总根,所以这个线性队列就是以init_task为起点(也可把它看成一个队列头),后继每创建一个进程就通过其task_struct结构中的next_task和prev_task两个指针链入这个线性队列中。
每个进程都必然同时身处这三个队列之中,直到进程消亡时才从这三个队列中摘除,所以这三个队列都是静态的。
在运行的过程中,一个进程还可以动态地链接进可执行队列接受系统的调度。实际上,这是最重要的队列,一个进程只有在可执行队列中才有可能受到调度而投入运行。与前几个队列不同的是,一个进程的task_struct是通过其list_head数据结构run_list、而不是个别的指针,链接进可执行队列的。以前说过,这是用于双向链接的通用数据结构,具有一些与之配套的函数或宏操作,处理的效率比价高,也使代码得以简化。可执行队列的变化是非常频繁的,一个进程进入睡眠就从队列中脱链,被唤醒时则又链入到该队列中,在调度的过程中也有可能会改变一个进程在此队列中位置。详见“进程调度与切换”以及“系统调用nanosleep”中的有关叙述。