
吴恩达老师DeepLearning.ai课程笔记
【吴恩达Deeplearning.ai笔记一】直观解释逻辑回归
【吴恩达deeplearning.ai笔记二】通俗讲解神经网络上
【吴恩达deeplearning.ai笔记二】通俗讲解神经网络下想提高一个深层神经网络的训练效率,需从各个方面入手,优化整个运算过程,同时预防其中可能发生的各种问题。
本文涉及优化深层神经网络中的数据划分,模型估计,预防过拟合,数据集标准化,权重初始化,梯度检验等内容。
1数据划分
想要建立一个神经网络模型,首先,就是要设置好整个数据集中的训练集(Training Sets)、开发集(Development Sets)和测试集(Test Sets)。
采用训练集进行训练时,通过改变几个超参数的值,将会得到几种不同的模型。开发集又称为交叉验证集(Hold-out Cross Validation Sets),它用来找出建立的几个不同模型中表现最好的模型。之后将这个模型运用到测试集上进行测试,对算法的好坏程度做无偏估计。通常,会直接省去最后测试集,将开发集当做“测试集”。
一个需要注意的问题是,需要保证训练集和测试集的来源一致,否则会导致最后的结果存在较大的偏差。
2模型估计
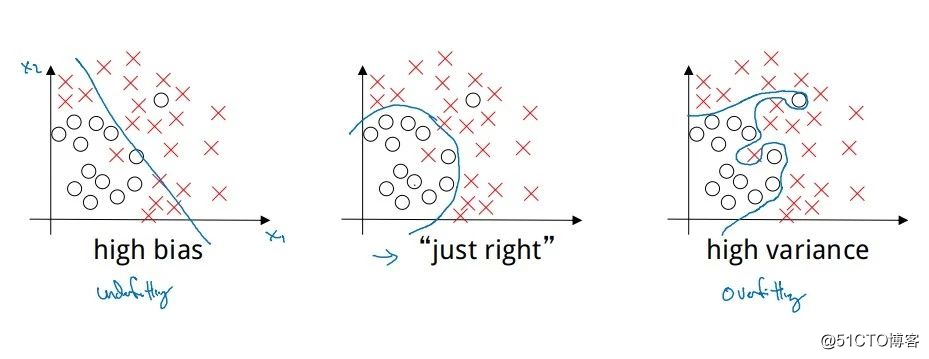
如图中的左图,对图中的数据采用一个简单的模型,例如线性拟合,并不能很好地对这些数据进行分类,分类后存在较大的偏差(Bias),称这个分类模型欠拟合(Underfitting)。
右图中,采用复杂的模型进行分类,例如深度神经网络模型,当模型复杂度过高时变容易出现过拟合(Overfitting),使得分类后存在较大的方差(Variance)。
中间的图中,采用一个恰当的模型,才能对数据做出一个差不多的分类。
通常采用开发集来诊断模型中是否存在偏差或者时方差:
- 当训练出一个模型后,发现训练集的错误率较小,而开发集的错误率却较大,这个模型可能出现了过拟合,存在较大方差;
- 发现训练集和开发集的错误率都都较大时,且两者相当,这个模型就可能出现了欠拟合,存在较大偏差;
- 发现训练集的错误率较大时,且开发集的错误率远较训练集大时,这个模型就有些糟糕了,方差和偏差都较大。
只有当训练集和开发集的错误率都较小,且两者的相差也较小,这个模型才会是一个好的模型,方差和偏差都较小。
模型存在较大偏差时,可采用增加神经网络的隐含层数、隐含层中的节点数,训练更长时间等方法来预防欠拟合。而存在较大方差时,则可以采用引入更多训练样本、对样本数据正则化(Regularization)等方法来预防过拟合。
3预防过拟合之L2正则化
向逻辑回归的成本函数中加入L2正则化(也称“L2范数”)项: 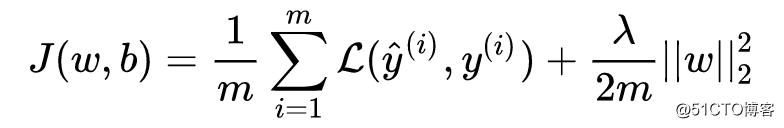
其中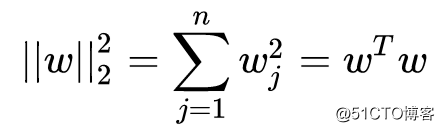
L2正则化是最常用的正则化类型,也存在L1正则化项: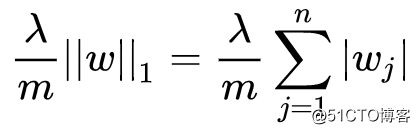
由于L1正则化最后得到 ω 中将存在大量的 0 ,使模型变得稀疏化,所以一般都使用L2正则化。其中的参数 λ 称为正则化参数,这个参数通常通过开发集来设置。
向神经网络的成本函数加入正则化项: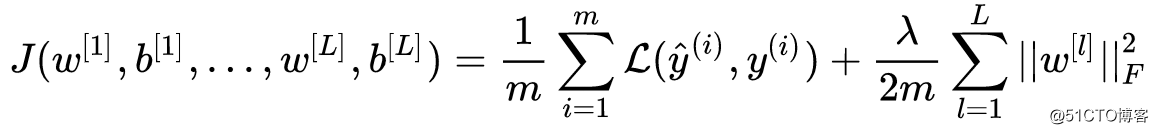
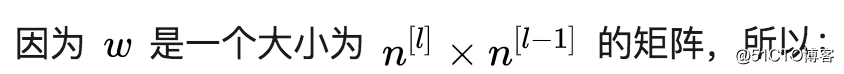
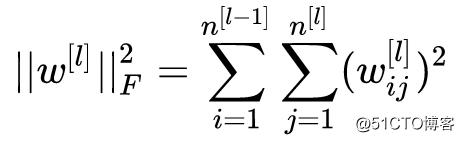
这被称为弗罗贝尼乌斯范数(Frobenius Norm),所以神经网络的中的正则化项被称为弗罗贝尼乌斯范数矩阵。
加入正则化项后,反向传播时有: 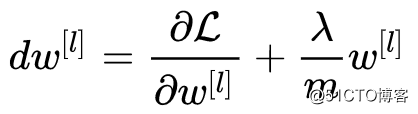
更新参数时有: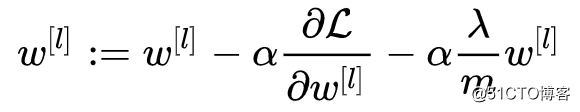

所以L2正则的过程也被称为权值衰减(Weight Decay)。
参数 λ 用来调整式中两项的相对重要程度,较小 λ 偏向于最后使原本的成本函数最小化,较大的 λ 偏向于最后使权值 ω 最小化。当 λ 较大时,权值 ω[ι] 便会趋近于 0 ,相当于消除深度神经网络中隐藏单元的部分作用。
另一方面,在权值 ω[L] 变小之下,输入样本X随机的变化不会对神经网络模造成过大的影响,神经网络受局部噪音的影响的可能性变小。这就是正则化能够降低模型方差的原因。
4预防过拟合之随机失活正则化
随机失活(DropOut)正则化,就是在一个神经网络中对每层的每个节点预先设置一个被消除的概率,之后在训练随机决定将其中的某些节点给消除掉,得到一个被缩减的神经网络,以此来到达降低方差的目的。
DropOut正则化较多地被使用在计算机视觉(Computer Vision)领域。
使用Python编程时可以用反向随机失活(Inverted DropOut)来实现DropOut正则化:
对于一个神经网络第3层
keep.prob = 0.8
d3 = np.random.randn(a3.shape[0],a3.shape[1]) < keep.prob
a3 = np.multiply(a3,d3)
a3 /= keep.prob
z4 = np.dot(w4,a3) + b4其中的d3是一个随机生成,与第3层大小相同的的布尔矩阵,矩阵中的值为0或1。而keep.prob ≤ 1,它可以随着各层节点数的变化而变化,决定着失去的节点的个数。
例如,将keep.prob设置为0.8时,矩阵d3中便会有20%的值会是0。而将矩阵a3和d3相乘后,便意味着这一层中有20%节点会被消除。需要再除以keep_prob的原因,是因为后一步求z4中将用到a3,而a3有20%的值被清零了,为了不影响下一层z4的最后的预期输出值,就需要这个步骤来修正损失的值,这一步就称为反向随机失活技术,它保证了a3的预期值不会因为节点的消除而收到影响,也保证了进行测试时采用的是DropOut前的神经网络。
与之前的L2正则化一样,利用DropOut,可以简化神经网络的部分结构,从而达到预防过拟合的作用。另外,当输入众多节点时,每个节点都存在被删除的可能,这样可以减少神经网络对某一个节点的依赖性,也就是对某一特征的依赖,扩散输入节点的权重,收缩权重的平方范数。
5预防过拟合之数据扩增法
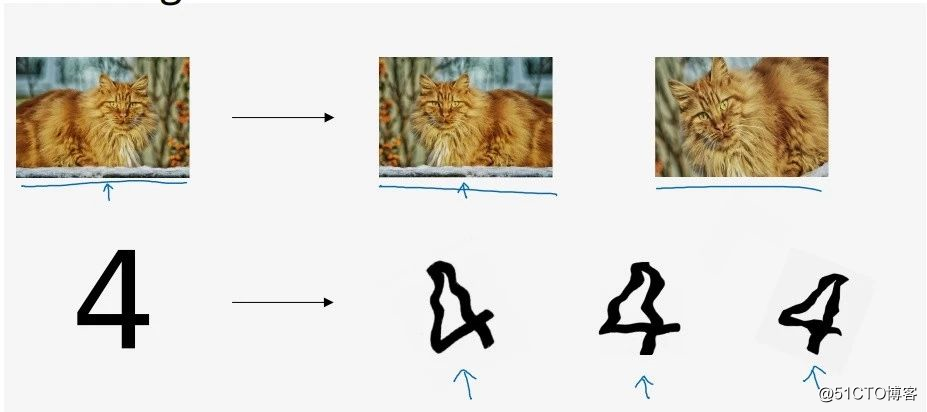
数据扩增(Data Augmentation)是在无法获取额外的训练样本下,对已有的数据做一些简单的变换。例如对一张图片进行翻转、放大扭曲,以此引入更多的训练样本。
6预防过拟合之早停止法

早停止(Early Stopping)是分别将训练集和开发集进行梯度下降时成本变化曲线画在同一个坐标轴内,在箭头所指两者开始发生较大偏差时就及时进行纠正,停止训练。
在中间箭头处,参数w将是一个不大不小的值,理想状态下就能避免过拟合的发生。然而这种方法一方面没有很好得降低成本函数,又想以此来避免过拟合,一个方法解决两个问题,哪个都不能很好解决。
7标准化数据集
对训练及测试集进行标准化的过程为: 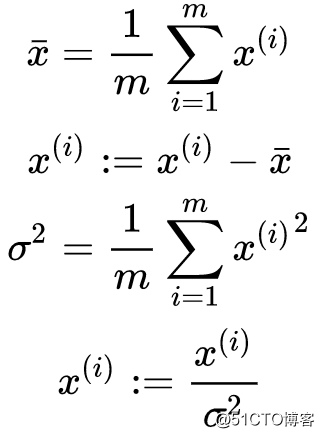
原始数据为:
经过前两步,x减去它们的平均值后: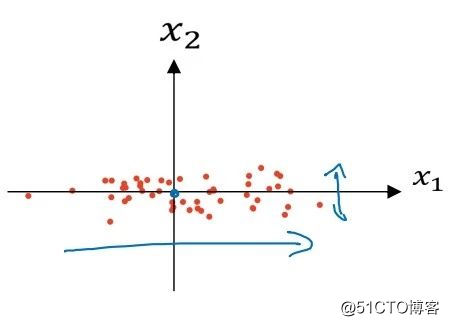
经过后两步,x除以它们的方差后: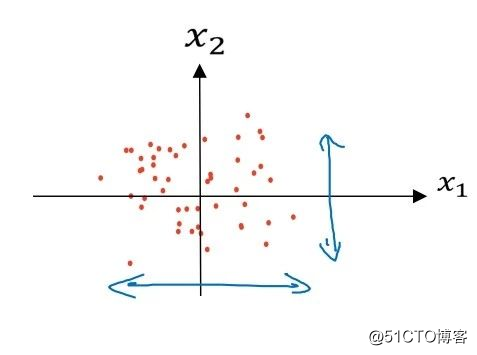
数据集未进行标准化时,成本函数的图像及梯度下降过程将是: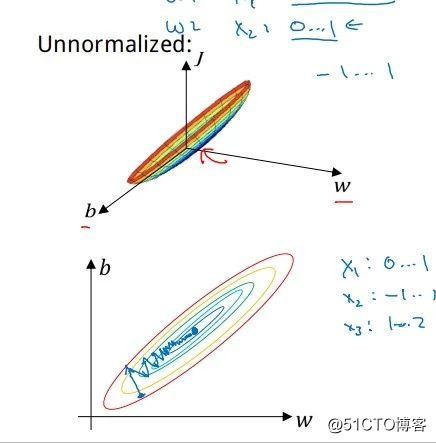
而标准化后,将变为: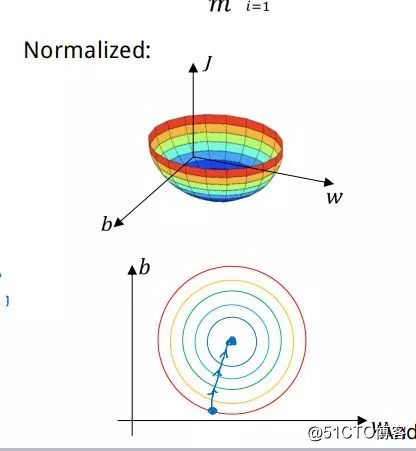
8初始化权重
在之前的建立神经网络的过程中,提到权重 ω 不能为 0 ,而将它初始化为一个随机的值。然而在一个深层神经网络中,当 ω 的值被初始化过大时,进入深层时呈指数型增长,造成梯度爆炸;过小时又会呈指数级衰减,造成梯度消失。
Python中将 ω 进行随机初始化时,使用numpy库中的np.random.randn()方法,randn是从均值为0的单位标准正态分布(也称“高斯分布”)进行取样。
随着对神经网络中的某一层输入的数据量n的增长,输出数据的分布中,方差也在增大。结果证明,可以除以输入数据量n的平方根来调整其数值范围,这样神经元输出的方差就归一化到 1 了,不会过大导致到指数级爆炸或过小而指数级衰减。也就是将权重初始化为:
w = np.random.randn(layers_dims[l],layers_dims[l-1]) \* np.sqrt(1.0/layers_dims[l-1])这样保证了网络中所有神经元起始时有近似同样的输出分布。
当激活函数为ReLU函数时,权重最好初始化为:
w = np.random.randn(layers_dims[l],layers_dims[l-1]) \* np.sqrt(2.0/layers_dims[l-1])以上结论的证明过程见参考资料。
9梯度检验
梯度检验的实现原理,是根据导数的定义,对成本函数求导,有: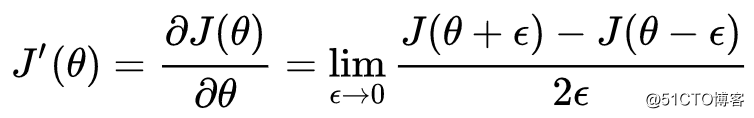
则梯度检验公式: 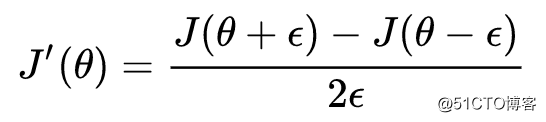
其中当 ε 越小时,结果越接近真实的导数也就是梯度值。可以使用这种方法,来判断反向传播进行梯度下降时,是否出现了错误。
梯度检验的过程,是对成本函数的每个参数 θ[i] 加入一个很小的 ε ,求得一个梯度逼近值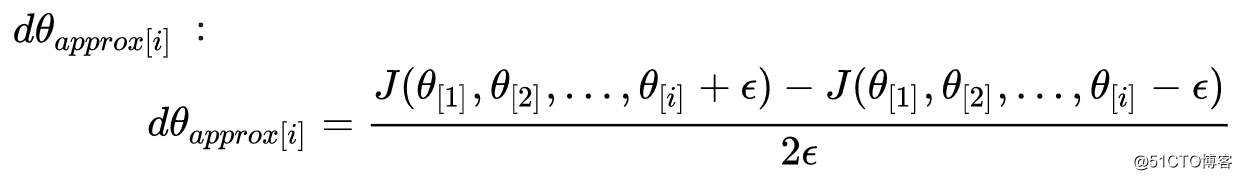
以解析方式求得 J'(θ) 在 J'(θ) 时的梯度值dθ ,进而再求得它们之间的欧几里得距离: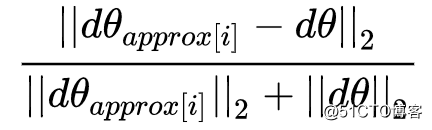

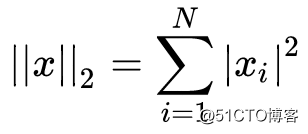
当计算的距离结果与 ε 的值相近时,即可认为这个梯度值计算正确,否则就需要返回去检查代码中是否存在bug。
需要注意的是,不要在训练模型时进行梯度检验,当成本函数中加入了正则项时,也需要带上正则项进行检验,且不要在使用随机失活后使用梯度检验。
注:本文涉及的图片及资料均整理翻译自Andrew Ng的Deep Learning系列课程,版权归其所有。翻译整理水平有限,如有不妥的地方欢迎指出。
推荐阅读:
视频 | 憋不出论文怎么办?不如试试这几种办法
【深度学习实战】pytorch中如何处理RNN输入变长序列padding
【机器学习基本理论】详解最大后验概率估计(MAP)的理解
欢迎关注公众号学习交流~ 