前言:一个多月业余学习马马虎虎完成了tushare数据的储存跟数据使用这一进度,发现还有很多不懂的知识,基础很不牢固,只能边学习边巩固了,写完这一篇文章后,接下开始学习数据的分析了,再往后就开始学习写股票策略了,还有5个月就过完2020年了,希望年末达到自己理想的状态。下面放出代码:
import pandas as pd
import tushare as ts
import pymysql
import os
import docx
import time
import datetime
import warnings
from urllib import parse
from sqlalchemy import create_engine
from docx.shared import Cm, Inches
from docx.shared import RGBColor,Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
warnings.filterwarnings('ignore')
#pd.set_option()就是pycharm输出控制显示的设置
pd.set_option('expand_frame_repr', False)#True就是可以换行显示。设置成False的时候不允许换行
pd.set_option('display.max_columns', None)# 显示所有列
#pd.set_option('display.max_rows', None)# 显示所有行
pd.set_option('colheader_justify', 'centre')# 显示居中
pro = ts.pro_api('要到tushare官网注册个账户然后将token复制到这里,可以的话请帮个忙用文章末我分享的链接注册,谢谢')
#df_basic = pro.stock_basic() 获取基础信息数据,包括股票代码、名称、上市日期、退市日期等
#df_daily = pro.daily() 获取所有股票日行情信息,或通过通用行情接口获取数据,包含了前后复权数据,停牌期间不提供数据
#df_daily_basic = pro.daily_basic()获取全部股票每日重要的基本面指标,可用于选股分析、报表展示等。
def tushare_to_mysql(st_date, ed_date): #tushare数据整理并导入mysql
#此方法连接数据库,密码可以输入特殊字符串
engine = create_engine('mysql://root:%[email protected]:3306/你的数据库名称?charset=utf8' % parse.unquote_plus('你的数据库密码'))
print('数据库连接成功')
trade_d = pro.trade_cal(exchange='SSE', is_open='1',start_date=st_date,end_date=ed_date,fields='cal_date')
for date in trade_d['cal_date'].values:
df_basic = pro.stock_basic(exchange='', list_status='L') #再获取所有股票的基本信息
df_daily = pro.daily(trade_date=date) # 先获得所有股票的行情数据,成交额单位是千元,成交量是手
df_daily_basic = pro.daily_basic(ts_code='', trade_date=date,fields='ts_code, turnover_rate, turnover_rate_f,'
' volume_ratio, pe, pe_ttm, pb, ps, ps_ttm,'
' dv_ratio, dv_ttm, total_share, float_share,'
' free_share, total_mv, circ_mv ') #获取每日指标,单位是万股,万元
df_first = pd.merge(left=df_basic, right=df_daily, on='ts_code', how='outer') # on='ts_code'以ts_code为索引,合并数据,how='outer',取并集
df_all = pd.merge(left=df_first, right=df_daily_basic, on='ts_code', how='outer')
# 数据清洗,删除symbol列数据,跟ts_code数据重复
df_all = df_all.drop('symbol', axis=1)
for w in ['name', 'area', 'industry', 'market']: # 在'name', 'area', 'industry', 'market'列内循环填充NaN值
df_all[w].fillna('问题股', inplace=True)
#df_all['amount'] = df_all['amount'] / 100000 # 千转亿
#df_all['circ_mv'] = df_all['circ_mv'] / 10000 # 万转亿
#df_all['total_mv'] = df_all['total_mv'] / 10000 # 万转亿
df_all['ts_code'] = df_all['ts_code'].astype(str) # 强制转换成str字符串格式
df_all['list_date'] = pd.to_datetime(df_all['list_date']) # 本地储存前一定要先转化成日期格式先
df_all['trade_date'] = pd.to_datetime(df_all['trade_date'])
#对获取的股票数据列名称进行重命名以方便阅读
df_all = df_all.rename(columns={
'ts_code': '股票代码', 'name': '股票名称', 'area': '所在地域', 'industry': '行业'
, 'market': '市场类型', 'list_date': '上市日期', 'trade_date': '交易日期', 'change': '涨跌额'
, 'pct_chg': '涨跌幅', 'vol': '成交量(手)', 'amount': '成交额(千元)', 'turnover_rate': '换手率(%)'
, 'turnover_rate_f': '流通换手率', 'volume_ratio': '量比', 'pe': '市盈率', 'pe_ttm': '滚动市盈率'
, 'pb': '市净率', 'ps': '市销率', 'ps_ttm': '滚动市销率', 'dv_ratio': '股息率'
, 'dv_ttm': '滚动股息率', 'total_share': '总股本(万股)', 'float_share': '流通股本(万股)'
, 'free_share': '自由流通股本(万股)', 'total_mv': '总市值(万元)', 'circ_mv': '流通市值(万元)'})
#亏损的为空值
engine.execute('drop table if exists {}_ts;'.format(date)) #删除重复的数据表
print('%s is downloading....' % (str(date)))
df_all.to_sql('{}_ts'.format(date),engine,index=False)
print('{}成功导入数据库'.format(date))
def get_mysql_data_analysis(st_date, ed_date):
trade_d = pro.trade_cal(exchange='SSE', is_open='1', start_date=st_date, end_date=ed_date, fields='cal_date')
conn = pymysql.connect(host='localhost', user='root', password='你的密码', db='tushare', charset='utf8') #连接数据库
for date_now in trade_d['cal_date'].values:
cursor = conn.cursor() #创建游标
sql = 'select * from {}_ts;'.format(date_now)
cursor.execute(sql) #执行sql操作
col_result = cursor.description #cursor.description方法会将每个字段的字段名,字段类型,字段长度...等等字段的属性列出来.
result = cursor.fetchall() #获取所有数据
columns = [] #设置空列表用来存放数据库列段名称
for i in range(len(col_result)):
columns.append(col_result[i][0]) # 获取字段名,咦列表形式保存
df = pd.DataFrame(list(result),columns=columns)
df = df.set_index('股票代码', drop=False) #必须重新设置索引
#df.fillna(0, inplace=True) #fillna填充缺失数据,传入inplace=True直接修改原对象
df['成交额(千元)'] = df['成交额(千元)']/100000 #千转亿
df['流通市值(万元)'] = df['流通市值(万元)']/10000 #万转亿
df['总市值(万元)'] = df['总市值(万元)']/10000 #万转亿
# 添加交易所列
df.loc[df['股票代码'].str.startswith('3'), 'exchange'] = 'CY'
df.loc[df['股票代码'].str.startswith('6'), 'exchange'] = 'SH'
df.loc[df['股票代码'].str.startswith('0'), 'exchange'] = 'SZ'
#此change表示的是价格变化的多少,不是指上涨下跌的百分比
df_up = df[df['涨跌额'] > 0.00] #找出上涨的股票
df_even = df[df['涨跌额'] == 0.00] #找出走平的股票
df_down = df[df['涨跌额'] < 0.00] #找出下跌的股票
# 找出涨停的股票
limit_up = df[df['涨跌额']/df['pre_close'] >= 0.097]
#print(limit_up['list_date'])
limit_down = df[df['涨跌额']/df['pre_close'] <= -0.0970]
# 涨停股数中的未封板股,上市日期小于15天
limit_up_new = limit_up[pd.to_datetime(date_now) - limit_up['上市日期'] <= pd.Timedelta(days=15)]
#print(pd.to_datetime(date_now))
# 涨停股数中次新股,上市日期小于1年
limit_up_fresh = limit_up[pd.to_datetime(date_now) - limit_up['上市日期'] <= pd.Timedelta(days=365)]
# 涨停股数中的未封板股,上市日期小于15天
limit_down_new = limit_down[pd.to_datetime(date_now) - limit_down['上市日期'] <= pd.Timedelta(days=15)]
# 涨停股数中次新股,上市日期小于1年
limit_down_fresh = limit_down[pd.to_datetime(date_now) - limit_down['上市日期'] <= pd.Timedelta(days=365)]
#df_up.shape[0]获取上涨的行数,df.shape[1]获取列数,df.values获取值
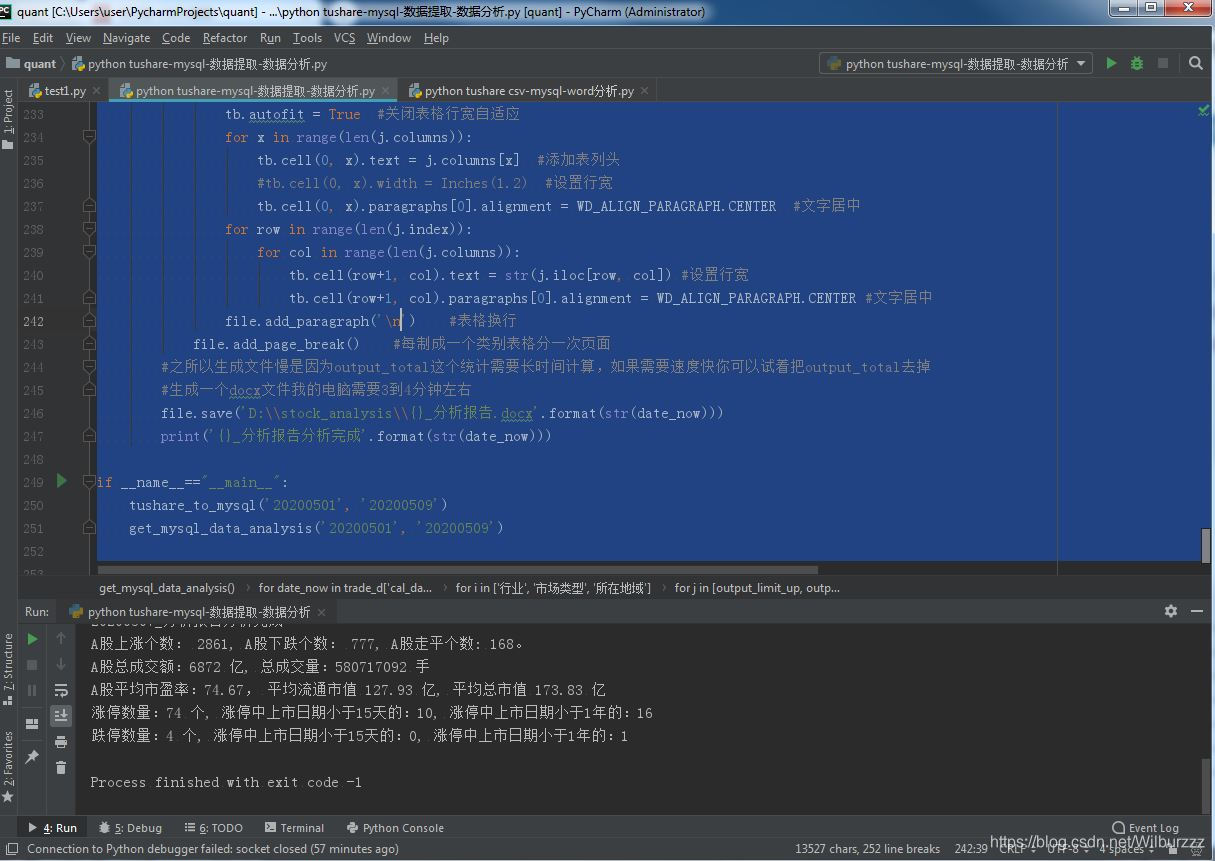
print('A股上涨个数: %d, A股下跌个数: %d, A股走平个数: %d。' % (df_up.shape[0], df_down.shape[0], df_even.shape[0]))
print('A股总成交额:%d 亿, 总成交量:%d 手' % (df['成交额(千元)'].sum(), df['成交量(手)'].sum()))
print('A股平均市盈率:%.2f, 平均流通市值 %.2f 亿, 平均总市值 %.2f 亿' % (df['市盈率'].mean(), df['流通市值(万元)'].mean(), df['总市值(万元)'].mean()))
print('涨停数量:%d 个, 涨停中上市日期小于15天的:%d, 涨停中上市日期小于1年的:%d' % (limit_up.shape[0], limit_up_new.shape[0], limit_up_fresh.shape[0]))
print('跌停数量:%d 个, 涨停中上市日期小于15天的:%d, 涨停中上市日期小于1年的:%d' % (limit_down.shape[0], limit_down_new.shape[0], limit_down_fresh.shape[0]))
file = docx.Document()
#设置总标题,居中
headb = file.add_heading('%s中国股市今日收盘分析报告' % (date_now), level=0).alignment = WD_ALIGN_PARAGRAPH.CENTER
head1 = file.add_heading('股市基本概况:',level=1) #设置一级标题
#添加段落内容
text1 = file.add_paragraph() #首先创建一个空的段落,然后再往里面加文字,这样方便设置文字格式字体等设置,另外一种写法,缺点不能单独设置字体属性
# text1 = file.add_paragraph('A股上涨个数: %d, A股下跌个数: %d, A股走平个数: %d。' % (df_up.shape[0], df_down.shape[0], df_even.shape[0]))
text1.add_run('A股上涨个数:').bold = True #添加文字并设置粗体
text1.add_run('{} '.format(str(df_up.shape[0]))).font.color.rgb = RGBColor(255, 0, 0) #添加变量
text1.add_run('A股下跌个数:').bold = True
text1.add_run('{} '.format(str(df_down.shape[0]))).font.color.rgb = RGBColor(0, 255, 0)
text1.add_run('A股走平个数:').bold = True
text1.add_run('{} '.format(str(df_even.shape[0]))).font.color.rgb = RGBColor(0, 0, 255)
text1.line_spacing = Pt(25) #设置段落行距
text1.style = 'List Bullet' # 设置项目符号列表
text2 = file.add_paragraph()
text2.add_run('A股总成交额:').bold = True
text2.add_run('{}'.format(str(round(df['成交额(千元)'].sum(),2)))).font.color.rgb = RGBColor(128, 0, 128)
text2.add_run('亿 ')
text2.add_run('总成交量:').bold = True
text2.add_run('{}'.format(str(round(df['成交量(手)'].sum(),2)))).font.color.rgb = RGBColor(128, 0, 128)
text2.add_run('手 ')
text2.line_spacing = Pt(25)
text2.style = 'List Bullet'
text3 = file.add_paragraph()
text3.add_run('A股平均市盈率:').bold = True
text3.add_run('{} '.format(str(round(df['市盈率'].mean())))).font.color.rgb = RGBColor(128, 0, 128)
text3.add_run('平均流通市值:').bold = True
text3.add_run('{}'.format(str(round(df['流通市值(万元)'].mean(),2)))).font.color.rgb = RGBColor(128, 0, 128)
text3.add_run('亿')
text3.add_run('\n')
text3.add_run('平均总市值:').bold = True
text3.add_run('{}'.format(str(round(df['总市值(万元)'].mean(),2)))).font.color.rgb = RGBColor(128, 0, 128)
text3.add_run('亿 ')
text3.line_spacing = Pt(25)
text3.style = 'List Bullet'
text3.add_run('\n')
text4 = file.add_paragraph()
text4.add_run('涨停数量:').bold = True
text4.add_run('{}'.format(str(limit_up.shape[0]))).font.color.rgb = RGBColor(255, 0, 0)
text4.add_run('个 ')
text4.add_run('涨停中上市日期小于15天的:').bold = True
text4.add_run('{}'.format(str(limit_up_new.shape[0]))).font.color.rgb = RGBColor(255, 0, 0)
text4.add_run('个 ')
text4.add_run('\n')
text4.add_run('涨停中上市日期小于1年的:').bold = True
text4.add_run('{}'.format(str(limit_up_fresh.shape[0]))).font.color.rgb = RGBColor(255, 0, 0)
text4.add_run('个 ')
text4.line_spacing = Pt(25)
text4.style = 'List Bullet'
text5 = file.add_paragraph()
text5.add_run('跌停数量:').bold = True
text5.add_run('{}'.format(str(limit_down.shape[0]))).font.color.rgb = RGBColor(0, 255, 0)
text5.add_run('个 ')
text5.add_run('跌停中上市日期小于15天的:').bold = True
text5.add_run('{}'.format(str(limit_down_new.shape[0]))).font.color.rgb = RGBColor(0, 255, 0)
text5.add_run('个 ')
text5.add_run('\n')
text5.add_run('跌停中上市日期小于1年的:').bold = True
text5.add_run('{}'.format(str(limit_down_fresh.shape[0]))).font.color.rgb = RGBColor(0, 255, 0)
text5.add_run('个 ')
text5.line_spacing = Pt(25)
text5.style = 'List Bullet'
file.add_page_break() #添加分页符
def get_output(df, columns='_industry', name='_limit_up'): #自定义计算平均市盈率,平均流通市值等函数,方便后面调用
# df.copy(deep= False)和df.copy()都是浅拷贝,是复制了旧对象的内容,然后重新生成一个新对象,改变旧对象不会影响新对象。
df = df.copy()
output = pd.DataFrame()
#df.groupby(columns)根据列值分组数据,并根据股票代码统计数据
output = pd.DataFrame(df.groupby(columns)['股票代码'].count())
output['平均市盈率'] = round(df.groupby(columns)['市盈率'].mean(),2)
output['平均流通市值(亿)'] = round(df.groupby(columns)['流通市值(万元)'].mean(),2)
output['平均总市值(亿)'] = round(df.groupby(columns)['总市值(万元)'].mean(),2)
output['平均成交量(手)'] = round(df.groupby(columns)['成交量(手)'].mean(),2)
output['平均成交额(亿)'] = round(df.groupby(columns)['成交额(千元)'].mean(),2)
#依据ts_code进行降序,排序后的数据集替换原来的数据
output.sort_values('股票代码', ascending=False, inplace=True)
#改列值名字,将ts_code改成name+‘_count’的形式
output.rename(columns={
'股票代码': name + '合计'}, inplace=True)
return output
for i in ['行业', '市场类型', '所在地域']:
# 对涨停的股票分析
output_limit_up = get_output(limit_up, columns=i, name='涨停').reset_index()
# 对跌停的股票分析
output_limit_down = get_output(limit_down, columns=i, name='跌停').reset_index()
# 对全量的股票分析
output_total = get_output(df, columns=i, name='全部').reset_index()
#添加表格开头类别说明
tabletext = file.add_paragraph()
tabletext.add_run('类别:').bold = True
tabletext.add_run('{} '.format(str(i))).font.color.rgb = RGBColor(222, 125, 44)
# print(output_limit_up)
# print(output_limit_down)
# print(output_total)
for j in [output_limit_up, output_limit_down]: #, output_total
#之所以生成文件慢是因为output_total这个统计需要长时间计算,如果需要速度快你可以试着把output_total去掉,当然你也可以在上面的列表内加上,变成for j in [output_limit_up, output_limit_down, output_total]
tb = file.add_table(rows=len(j.index)+1, cols=len(j.columns),style='Medium Grid 3 Accent 1')
tb.autofit = True #关闭表格行宽自适应
for x in range(len(j.columns)):
tb.cell(0, x).text = j.columns[x] #添加表列头
#tb.cell(0, x).width = Inches(1.2) #设置行宽
tb.cell(0, x).paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER #文字居中
for row in range(len(j.index)):
for col in range(len(j.columns)):
tb.cell(row+1, col).text = str(j.iloc[row, col]) #设置行宽
tb.cell(row+1, col).paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER #文字居中
file.add_paragraph('\n') #表格换行
file.add_page_break() #每制成一个类别表格分一次页面
#之所以生成文件慢是因为output_total这个统计需要长时间计算,如果需要速度快你可以试着把output_total去掉
#生成一个docx文件我的电脑需要3到4分钟左右
file.save('D:\\stock_analysis\\{}_分析报告.docx'.format(str(date_now)))
print('{}_分析报告分析完成'.format(str(date_now)))
if __name__=="__main__":
tushare_to_mysql('20200501', '20200509')
get_mysql_data_analysis('20200501', '20200509')
tushare注册链接:link