参考了一部分别人的,自己也整理了一点,持续更新中…
计算机视觉算法岗面试题:在这里。
CNN结构特点
1.局部连接使网络可以提取数据的局部特征
2.首先权值共享就是滤波器共享,即是用相同的滤波器去扫一遍图像,提取一次特征,得到feature map。在卷积网络中,学好了一个滤波器,就相当于掌握了一种特征,这个滤波器在图像中滑动,进行特征提取,然后所有进行这样操作的区域都会被采集到这种特征,权值共享大大降低了网络的训练难度,一个滤波器只提取一个特征,在整个图片(或者语音/文本) 中进行卷积。
3.池化操作与多层次结构一起,实现了数据的降维,
4.多层次结构将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。
神经网络中权值共享的理解?
权值(权重)共享这个词是由LeNet5模型提出来的。以CNN为例,在对一张图偏进行卷积的过程中,使用的是同一个卷积核的参数。 比如一个3×3×1的卷积核,这个卷积核内9个的参数被整张图共享,而不会因为图像内位置的不同而改变卷积核内的权系数。说的再直白一些,就是用一个卷积核不改变其内权系数的情况下卷积处理整张图片(当然CNN中每一层不会只有一个卷积核的,这样说只是为了方便解释而已)。
激活函数的作用
激活函数实现去线性化。神经元的结构的输出为所有输入的加权和,这导致神经网络是一个线性模型。如果将每一个神经元(也就是神经网络的节点)的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了,这个非线性函数就是激活函数。 常见的激活函数有:ReLU函数、sigmoid函数、tanh函数。
卷积层和池化层有什么区别
卷积层有参数,池化层没有参数
经过卷积层节点矩阵深度会改变,池化层不会改变节点矩阵的深度,但是它可以缩小节点矩阵的大小
卷积层参数数量计算方法
假设输入层矩阵维度是96963,第一层卷积层使用尺寸为5x5、深度为16的过滤器(卷积核尺寸为5x5、卷积核数量为16),那么这层卷积层的参数个数为553*16+16=1216个
神经网络为什么用交叉熵损失函数
判断一个输出向量和期望的向量有多接近,交叉熵(cross entroy)是常用的评判方法之一。交叉熵刻画了两个概率分布之间的距离,是分类问题中使用比较广泛的一种损失函数。 给定两个概率分布p和q,通过q来表示p的交叉熵公式为: H(p,q)=−∑p(x)logq(x)
什么样的数据集不适合深度学习
1.数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
2.数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
什么是梯度消失和爆炸,怎么解决?
神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。深度神经网络中的梯度不稳定性,根本原因在于前面层上的梯度是来自于后面层上梯度的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。
梯度消失:前面的层比后面的层梯度变化更小,造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,如sigmoid函数最大的梯度值为0.25,而在无穷大时梯度接近为0,经过多个激活函数后很难再继续梯度下降,造成学习停止。
梯度爆炸:前面层比后面层梯度变化更快,造成模型无法收敛,故引起梯度爆炸问题。
解决梯度消失和梯度爆炸问题,常用的有以下几个方案:
1.预训练模型 + 微调。
2.梯度剪切 + 正则化。
3.relu、leakyrelu、prelu等激活函数。
4.BN批归一化。
5.残差结构。
7.选用合适的学习率。
Overfitting怎么解决
首先所谓过拟合,指的是一个模型过于复杂之后,它可以很好地“记忆”每一个训练数据中随机噪音的部分而忘记了去“训练”数据中的通用趋势。 过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
Parameter Norm Penalties(参数范数惩罚);Dataset Augmentation (数据集增强);Early Stopping(提前终止);Parameter Tying and Parameter Sharing (参数绑定与参数共享);Bagging and Other Ensemble Methods(Bagging 和其他集成方法);dropout;regularization; batch normalizatin。是解决Overfitting的常用手段。
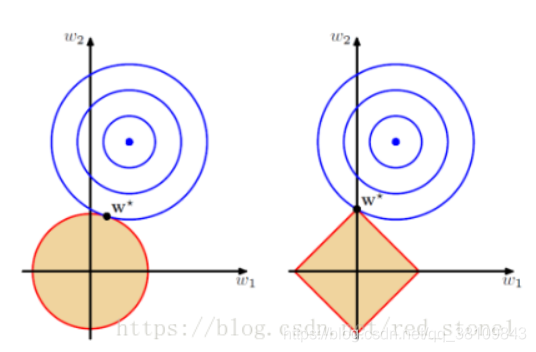
L1和L2区别
L1 范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。 比如 向量 A=[1,-1,3], 那么 A 的 L1 范数为 |1|+|-1|+|3|。简单总结一下就是:
L1 范数: 为 x 向量各个元素绝对值之和,L1 范数可以使权值稀疏,方便特征提取。
L2 范数: 为 x 向量各个元素平方和的 1/2 次方, L2 范数可以防止过拟合,提升模型的泛化能力。
Lp 范数: 为 x 向量各个元素绝对值 p 次方和的 1/p 次方. 在支持向量机学习过程中,L1 范数实际是一种对于成本函数求解最优的过程,因此,L1 范数正则化通过向成本函数中添加 L1 范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
有哪些常见的损失函数
- L1 loss:绝对差平均损失,又称MAE
.
2.L2 loss:平方差平均损失,又称MSE
3.Smooth L1 loss,又称Huber损失
4.BCE loss,二分类用的交叉熵损失,用的时候需要在该层前面加上 Sigmoid 函数
5.BCEWithlogitsLoss,将sigmoid函数集成到BCE loss上
6.CrossEntoryLoss,交叉熵损失函数
第一种形式:
第二种形式:
softmax的交叉熵:
7.NllLoss:负对数似然损失。
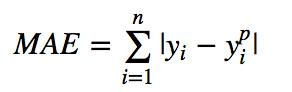
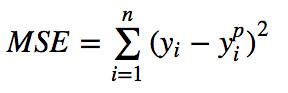
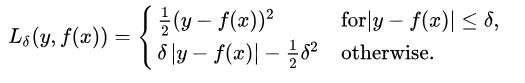
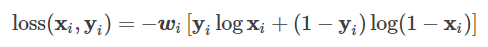
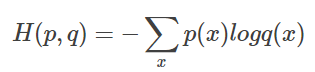

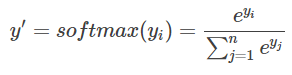
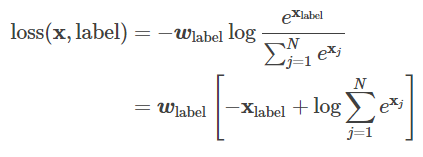
为什么sigmoid使用交叉熵而不使用平方差损失


什么是正则化,为什么用正则化?
正则化是为了防止过拟合, 进而增强泛化能力。
1.L2 正则化公式非常简单,在原来的损失函数基础上加上权重参数的平方和其中,Ein 是未包含正则化项的训练样本误差,λ 是正则化参数:
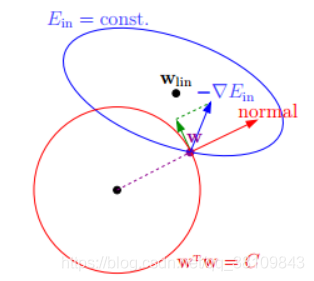
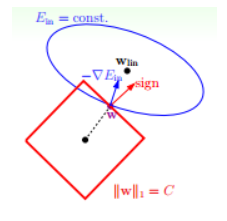
如上图所示,蓝色椭圆区域是最小化 Ein 区域,红色圆圈是 w 的限定条件区域。在没有限定条件的情况下,一般使用梯度下降算法,在蓝色椭圆区域内会一直沿着 w 梯度的反方向前进,直到找到全局最优值 wlin。例如空间中有一点 w(图中紫色点),此时 w 会沿着 -∇Ein 的方向移动,如图中蓝色箭头所示。但是,由于存在限定条件,w 不能离开红色圆形区域,最多只能位于圆上边缘位置,沿着切线方向。w 的方向如图中红色箭头所示。
根据最优化算法的思想:梯度为 0 的时候,函数取得最优值,构造新的损失函数。
2.L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值
L1正则化比L2正则化更具有稀疏性。

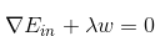

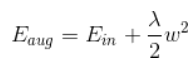
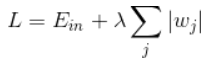
TensorFlow计算图
Tensorflow 是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow 中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
BN(批归一化)的作用
1.中间层神经元激活输入x从变化不拘一格的正态分布通过BN操作拉回到了均值为0,方差为1的高斯分布,使用缩放因子γ和移位因子β来执行此操作。这有两个好处:避免分布数据偏移;远离导数饱和区。即解决了反向传播过程中的梯度问题。
2.取消Local Response Normalization层。 由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上也没那么work。
3.移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
4.可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。
5.降低L2权重衰减系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
什么时候不适合用批归一化
1.小批量数据。
2.数据发布及其不平衡。
RNN循环神经网络理解
循环神经网络(recurrent neural network, RNN), 主要应用在语音识别、语言模型、机器翻译以及时序分析等问题上。 在经典应用中,卷积神经网络在不同的空间位置共享参数,循环神经网络是在不同的时间位置共享参数,从而能够使用有限的参数处理任意长度的序列。 RNN可以看做作是同一神经网络结构在时间序列上被复制多次的结果,这个被复制多次的结构称为循环体,如何设计循环体的网络结构是RNN解决实际问题的关键。 RNN的输入有两个部分,一部分为上一时刻的状态,另一部分为当前时刻的输入样本。
训练过程中模型不收敛,是否说明这个模型无效,致模型不收敛的原因有哪些?
不一定。导致模型不收敛的原因有很多种可能,常见的有以下几种:
1.没有对数据做归一化。
2.没有检查过你的结果。这里的结果包括预处理结果和最终的训练测试结果。
3.忘了做数据预处理。
4.忘了使用正则化。
5.Batch Size设的太大。
6.学习率设的不对。
7.最后一层的激活函数用的不对。
8.网络存在坏梯度。比如Relu对负值的梯度为0,反向传播时,0梯度就是不传播。
9.参数初始化错误。
10.网络太深。隐藏层神经元数量错误。
图像处理中平滑和锐化操作是什么?
平滑处理(smoothing)也称模糊处理(bluring),主要用于消除图像中的噪声部分,平滑处理常用的用途是用来减少图像上的噪点或失真,平滑主要使用图像滤波。在这里,我个人认为可以把图像平滑和图像滤波联系起来,因为图像平滑常用的方法就是图像滤波器。 在OpenCV3中常用的图像滤波器有以下几种:
1.方框滤波——BoxBlur函数
2.均值滤波(邻域平均滤波)——Blur函数
3.高斯滤波——GaussianBlur函数
4.中值滤波——medianBlur函数
5.双边滤波——bilateralFilter函数
图像锐化操作是为了突出显示图像的边界和其他细节图像锐化实现的方法是通过各种算子和滤波器实现的——Canny算子、Sobel算子、Laplacian算子以及Scharr滤波器。
VGG使用2个3*3卷积的优势在哪里?
(1). 减少网络层参数。用两个3x3卷积比用1个5x5卷积拥有更少的参数量,只有后者的2∗3∗3/15∗5=0.72。但是起到的效果是一样的,两个3x3的卷积层串联相当于一个5x5的卷积层,感受野的大小都是5×5,即1个像素会跟周围55的像素产生关联。
(2). 更多的非线性变换。2个3x3卷积层拥有比1个5x5卷积层更多的非线性变换(前者可以使用两次ReLU激活函数,而后者只有一次),使得卷积神经网络对特征的学习能力更强。
paper中给出的相关解释:三个这样的层具有7×7的有效感受野。那么我们获得了什么?例如通过使用三个3×3卷积层的堆叠来替换单个7×7层。首先,我们结合了三个非线性修正层,而不是单一的,这使得决策函数更具判别性。其次,我们减少参数的数量:假设三层3×3卷积堆叠的输入和输出有C个通道,堆叠卷积层的参数为3(32C2)=27C2个权重;同时,单个7×7卷积层将需要72C2=49C2个参数,即参数多81%。这可以看作是对7×7卷积滤波器进行正则化,迫使它们通过3×3滤波器(在它们之间注入非线性)进行分解。
Relu比Sigmoid效果好在哪里?
relu激活函数:
relu函数方程 ReLU 的输出要么是 0, 要么是输入本身。虽然方程简单,但实际上效果更好。
1.ReLU函数计算简单,可以减少很多计算量。反向传播求误差梯度时,涉及除法,计算量相对较大,采用ReLU激活函数,可以节省很多计算量;
2.避免梯度消失问题。对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失问题(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练;
3.可以缓解过拟合问题的发生。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
Relu的缺点
假设有一个神经网络的输入W遵循某种分布,对于一组固定的参数(样本),w的分布也就是ReLU的输入的分布。假设ReLU输入是一个低方差中心在+0.1的高斯分布。
在这个场景下:
大多数ReLU的输入是正数,因此
大多数输入经过ReLU函数能得到一个正值(ReLU is open),因此
大多数输入能够反向传播通过ReLU得到一个梯度,因此
ReLU的输入(w)一般都能得到更新通过随机反向传播(SGD)
现在,假设在随机反向传播的过程中,有一个巨大的梯度经过ReLU,由于ReLU是打开的,将会有一个巨大的梯度传给输入(w)。这会引起输入w巨大的变化,也就是说输入w的分布会发生变化,假设输入w的分布现在变成了一个低方差的,中心在-0.1高斯分布。
对fine-tuning(微调模型的理解),为什么要修改最后几层神经网络权值?
使用预训练模型的好处,在于利用训练好的模型权重去做特征提取,可以节省我们训练模型和调参的时间。至于为什么只微调最后几层神经网络权重,是因为:
1.CNN中更靠近底部的层(定义模型时先添加到模型中的层)编码的是更加通用的可复用特征,而更靠近顶部的层(最后添加到模型中的层)编码的是更专业业化的特征。微调这些更专业化的特征更加有用,它更代表了新数据集上的有用特征。
2.训练的参数越多,过拟合的风险越大。很多模型拥有超过千万的参数,在一个不大的数据集上训练这么多参数是有过拟合风险的,除非你的数据集像Imagenet那样大。
什么是dropout?
dropout可以防止过拟合,dropout简单来说就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型的泛化性更强,因为它不会依赖某些局部的特征。
以标准神经网络为例,正常的流程是:我们首先把输入数据x通过网络前向传播,然后把误差反向传播一决定如何更新参数让网络进行学习。使用dropout之后,过程变成如下:
1.首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变;
2.然后把输入x通过修改后的网络进行前向传播计算,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b);
(3). 然后重复这一过程:
恢复被删掉的神经元,此时被删除的神经元保持原样没有更新w参数,而没有被删除的神经元已经有所更新,从隐藏层神经元中随机选择一个一半大小的子集临时删除掉,同时备份被删除神经元的参数。
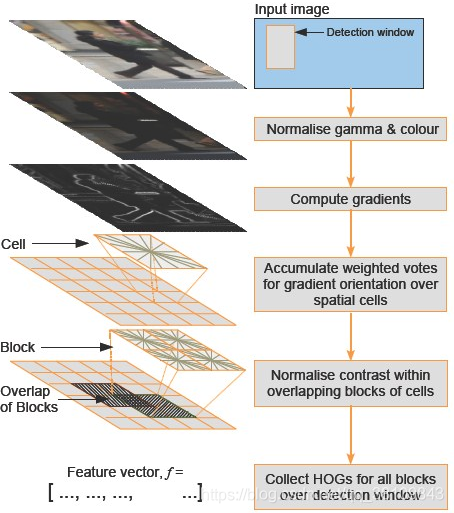
HOG算法原理描述
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。在深度学习取得成功之前,Hog特征结合SVM分类器被广泛应用于图像识别中,在行人检测中获得了较大的成功。
HOG特征原理:
HOG的核心思想是所检测的局部物体外形能够被光强梯度或边缘方向的分布所描述。通过将整幅图像分割成小的连接区域(称为cells),每个cell生成一个方向梯度直方图或者cell中pixel的边缘方向,这些直方图的组合可表示出(所检测目标的目标)描述子。为改善准确率,局部直方图可以通过计算图像中一个较大区域(称为block)的光强作为measure被对比标准化,然后用这个值(measure)归一化这个block中的所有cells。这个归一化过程完成了更好的照射/阴影不变性。 与其他描述子相比,HOG得到的描述子保持了几何和光学转化不变性(除非物体方向改变)。因此HOG描述子尤其适合人的检测。
HOG特征提取方法就是将一个image:
1.灰度化(将图像看做一个x,y,z(灰度)的三维图像)
2.划分成小cells(2*2)
3.计算每个cell中每个pixel的gradient(即orientation)
4.统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor。
HOG特征检测步骤
颜色空间归一化——–>梯度计算————->梯度方向直方图———->重叠块直方图归一化———–>HOG特征。
BN算法,为什么要在后面加加伽马和贝塔,不加可以吗?
最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入。不加也可以。
机器学习
Focal Loss 介绍一下
数据不平衡怎么办?
AUC的理解
AUC的计算公式
分类器的ROC曲线和相关指标
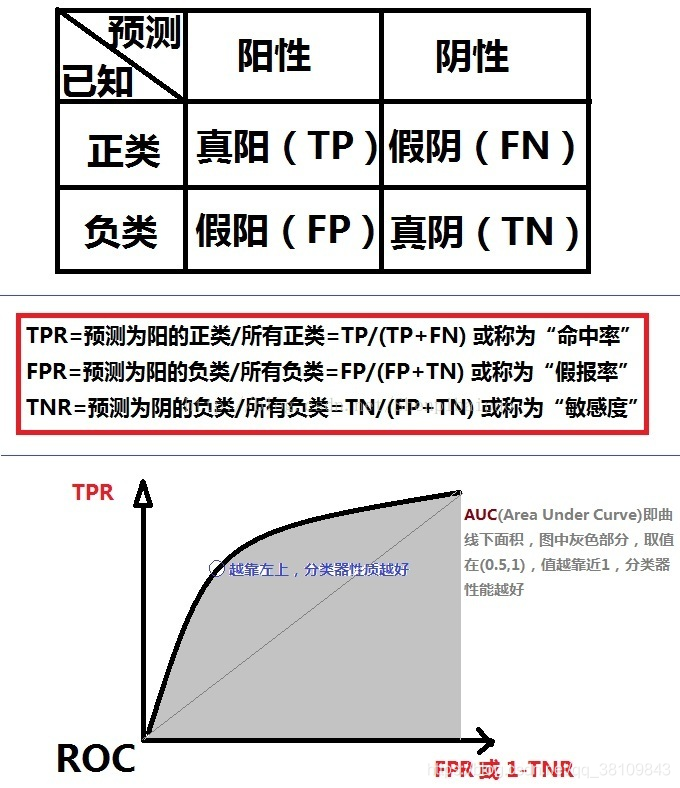
准确率(Accuracy):ACC=(TP+TN)/(TP+TN+FP+FN)
mAP是什么
P:precision即准确率,TP / (TP + FP),分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例;
R:recall即召回率,TP / (TP + FN),分类器认为是正类并且确实是正类的部分占所有确实是正类的比例;
目标检测中:
TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
FN: 没有检测到的GT的数量
PR曲线:以P和R为纵横坐标的曲线;
AP值:Average Precision平均精确度,为PR曲线下面积;
mAP:各类AP的平均值;
举例:
假设,对于Aeroplane类别,我们网络有以下输出(BB表示BoundingBox序号,IoU>0.5时GT=1):
BB | confidence | GT
----------------------
BB1 | 0.9 | 1
----------------------
BB2 | 0.9 | 1
----------------------
BB1 | 0.8 | 1
----------------------
BB3 | 0.7 | 0
----------------------
BB4 | 0.7 | 0
----------------------
BB5 | 0.7 | 1
----------------------
BB6 | 0.7 | 0
----------------------
BB7 | 0.7 | 0
----------------------
BB8 | 0.7 | 1
----------------------
BB9 | 0.7 | 1
----------------------
因此,我们有 TP=5 (BB1, BB2, BB5, BB8, BB9), FP=5 (重复检测到的BB1也算FP)。除了表里检测到的5个GT以外,我们还有2个GT没被检测到,因此: FN = 2. 这时我们就可以按照Confidence的顺序给出各处的PR值,如下:
rank=1 precision=1.00 and recall=0.14
----------
rank=2 precision=1.00 and recall=0.29
----------
rank=3 precision=0.66 and recall=0.29
----------
rank=4 precision=0.50 and recall=0.29
----------
rank=5 precision=0.40 and recall=0.29
----------
rank=6 precision=0.50 and recall=0.43
----------
rank=7 precision=0.43 and recall=0.43
----------
rank=8 precision=0.38 and recall=0.43
----------
rank=9 precision=0.44 and recall=0.57
----------
rank=10 precision=0.50 and recall=0.71
对于Recall >= 0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,我们选取此时Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0。此时Aeroplane类别的 AP = (0.14-0)*1 + (0.29-0.14)*1 + (0.43-0.29)*0.5 + (0.57-0.43)*0.5 + (0.71-0.57)*0.5 + (1-0.71)*0 = 0.5
mAP就是对每一个类别都计算出AP然后再计算AP平均值就好了。
IoU
#RT:RightTop
#LB:LeftBottom
def IOU(rectangle A, rectangleB):
W = min(A.RT.x, B.RT.x) - max(A.LB.x, B.LB.x)
H = min(A.RT.y, B.RT.y) - max(A.LB.y, B.LB.y)
if W <= 0 or H <= 0:
return 0;
SA = (A.RT.x - A.LB.x) * (A.RT.y - A.LB.y)
SB = (B.RT.x - B.LB.x) * (B.RT.y - B.LB.y)
cross = W * H
return cross/(SA + SB - cross)
什么是非极大值抑制
NMS:抑制不是极大值的元素,常用于目标检测中提取领域分数最高的窗口,且抑制分数低的窗口。对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式:选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空。
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
soft-NMS

代码:
ua = float((tx2 - tx1 + 1) * (ty2 - ty1 + 1) + area - iw * ih)
ov = iw * ih / ua #iou between max box and detection box
if method == 1: # linear
if ov > Nt:
weight = 1 - ov
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(ov * ov)/sigma)
else: # original NMS
if ov > Nt:
weight = 0
else:
weight = 1
boxes[pos, 4] = weight*boxes[pos, 4]
移动端深度学习框架知道哪些?
知名的有TensorFlow Lite、小米MACE、腾讯的FeatherCNN、ncnn等,百度的MDL,骁龙SNPE。
有哪些轻量化模型?
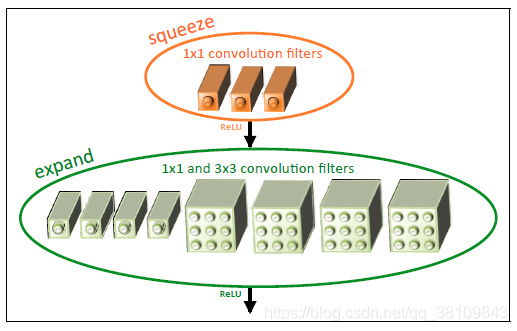
一、SequeezeNet:
核心思想:
1.使用1x1卷积核代替3x3卷积核,减少参数量;
2.通过squeeze layer限制通道数量,减少参数量;
3.借鉴inception思想,将1x1和3x3卷积后结果进行concat;为了使其feature map的size相同,3x3卷积核进行了padding;
4.减少池化层,并将池化操作延后,给卷积层带来更大的激活层,保留更多地信息,提高准确率;
5.使用全局平均池化代替全连接层;
1-3通过fire module实现,如下图所示:
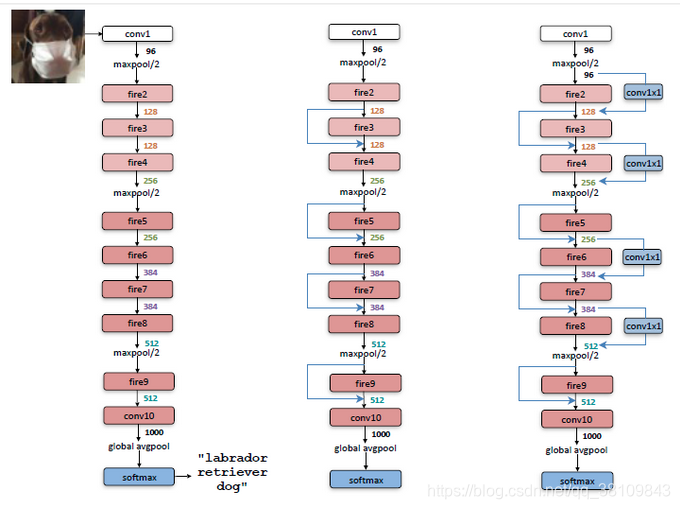
 网络结构:
网络结构:
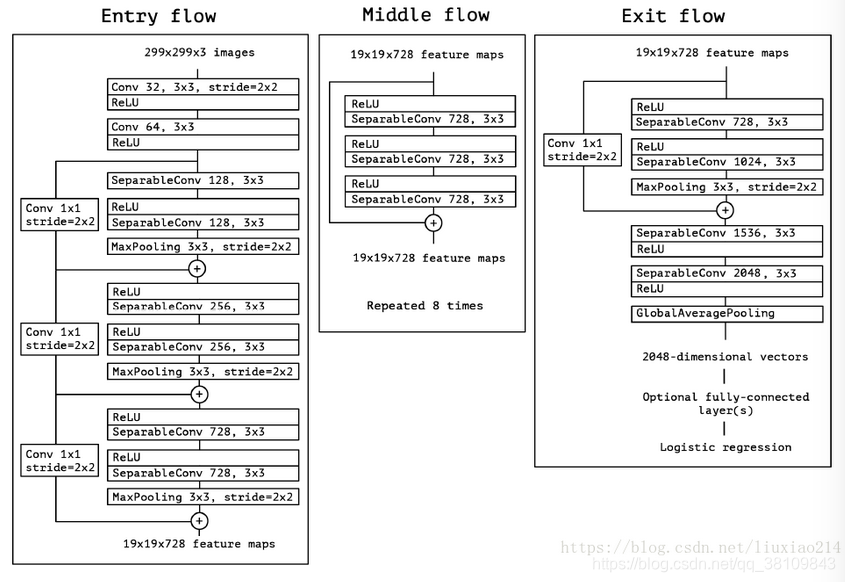
 二、Xception
二、Xception
核心思想:
主要采用depthwise separable convolution思想(这个后面在mobile net中详细解释)
首先xception类似于下图,但是区别有两点:
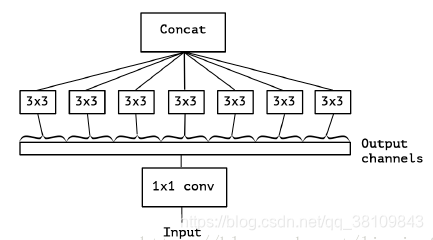
1.Xception中没有relu激活函数;
2.图4是先1x1卷积,后通道分离;xception是先进行通道分离,即depthwise separable convolution,然后再进行1x1卷积。
3.进行残差连接时,不再是concat,而是采用加法操作。
网络结构:
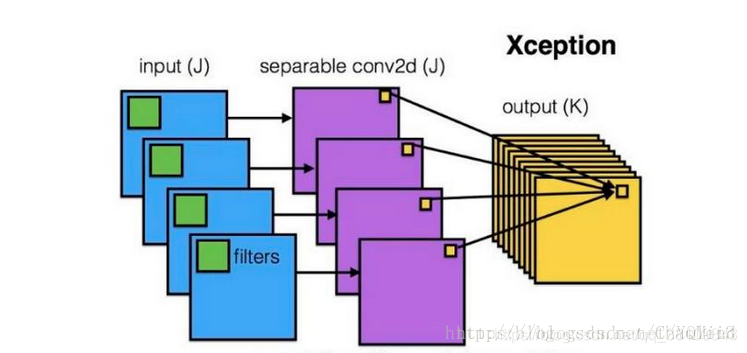
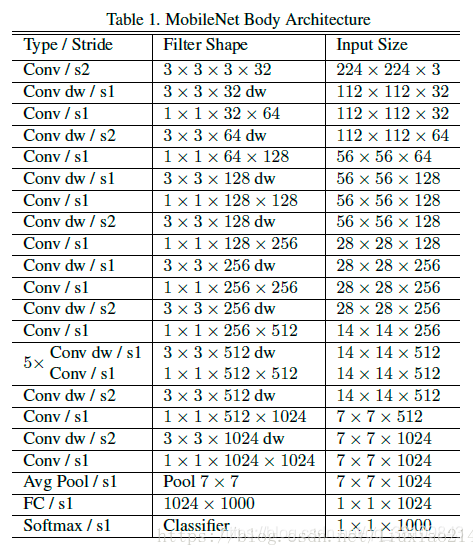
 三、MobileNet
三、MobileNet
核心思想:
1.主要采用depthwise separable convolution,就是分离卷积核;
2.设置宽度因子width multipler和分辨率因子resolution multiplier;
 与普通卷积的计算量相比,N为通道数,Dk为特征图的大小:
与普通卷积的计算量相比,N为通道数,Dk为特征图的大小:
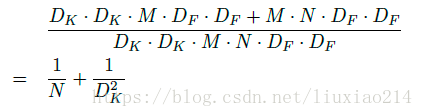
怎么才能使网络进一步压缩呢?可以进一步减少feature map的通道数和size,通过宽度因子减少通道数,分辨率因子减少size。
1、宽度因子α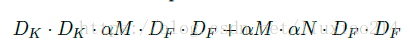
2、分辨率因子ρ

两个参数都属于(0,1]之间,当为1时则是标准mobileNet。
基本模块:
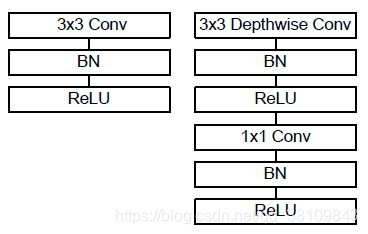
网络结构:
 四、ShuffleNet
四、ShuffleNet
核心思想:
1.借鉴resnext分组卷积思想,但不同的是采用1x1卷积核;
2.进行通道清洗,加强通道间的信息流通,提高信息表示能力。
分组卷积和通道清洗:
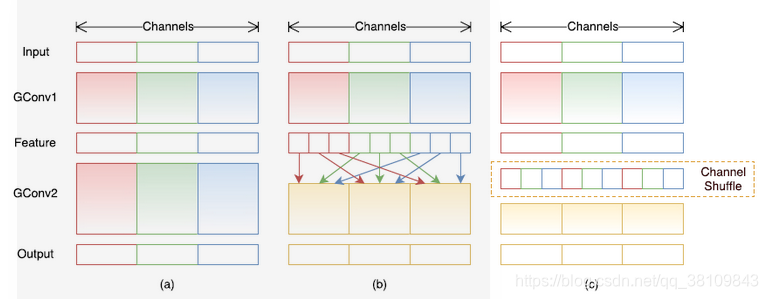 Shuffle的方法:
Shuffle的方法:
1.卷积后一共得到g×n个输出通道的feature map;
2.将feature map 进行 reshape为(g,n);
3.进行转置为(n,g);
4.对转置结果flatten,再分回g组作为下一层的输入。
三种Shuffle unit:
 网络结构:
网络结构:
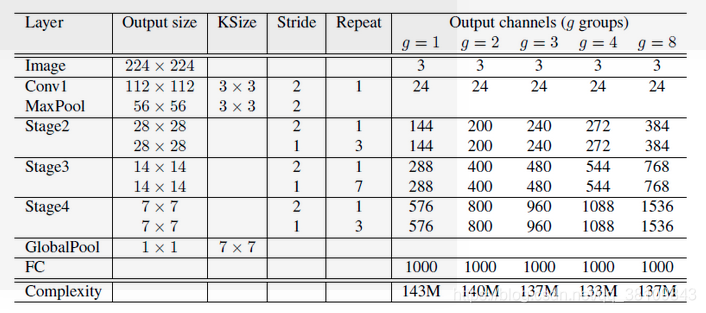
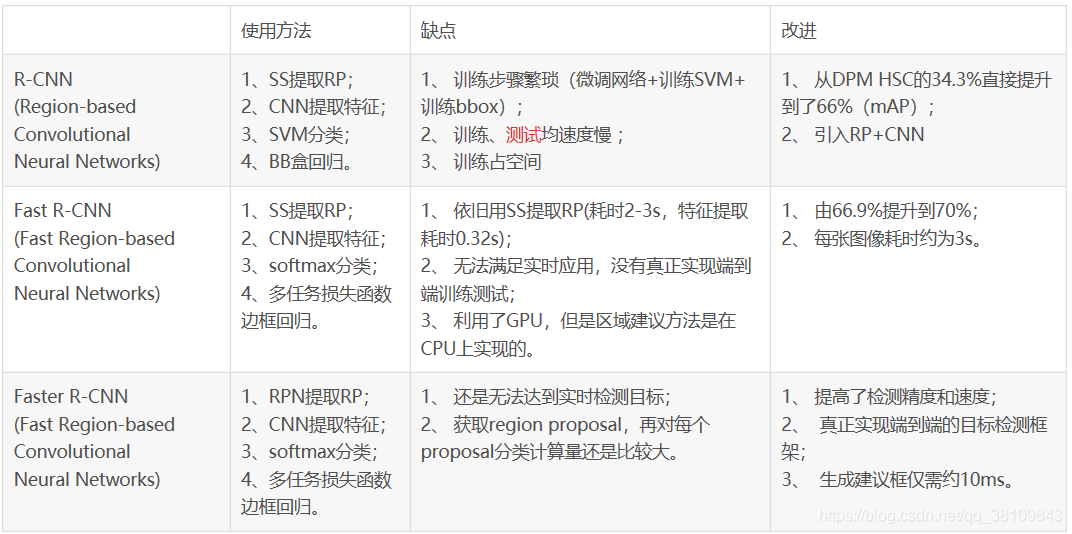
目标检测RCNN系列的区别
1.RCNN:
网络分为四个部分:区域划分、特征提取、区域分类、边框回归
区域划分:使用selective search算法画出2k个左右候选框,送入CNN
特征提取:使用imagenet上训练好的模型,进行finetune
区域分类:从头训练一个SVM分类器,对CNN出来的特征向量进行分类
边框回归:使用线性回归,对边框坐标进行精修
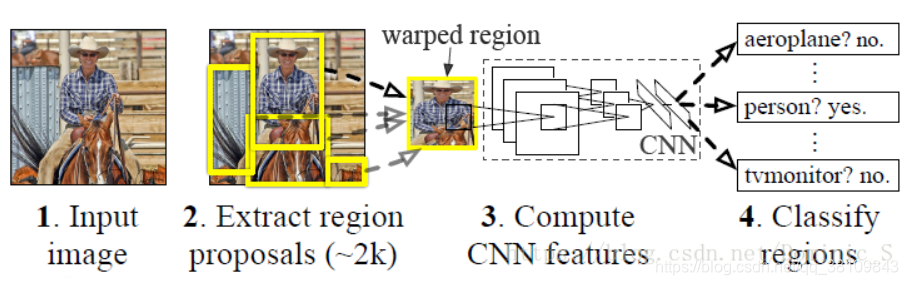
2.Fast RCNN
Fast R-CNN框架与R-CNN有两处不同:
① 最后一个卷积层后加了一个ROI pooling layer;
② 损失函数使用了multi-task loss(多任务损失)函数,将边框回归直接加到CNN网络中训练。分类Fast R-CNN直接用softmax替代R-CNN用的SVM进行分类。
③Fast R-CNN是端到端(end-to-end)的。

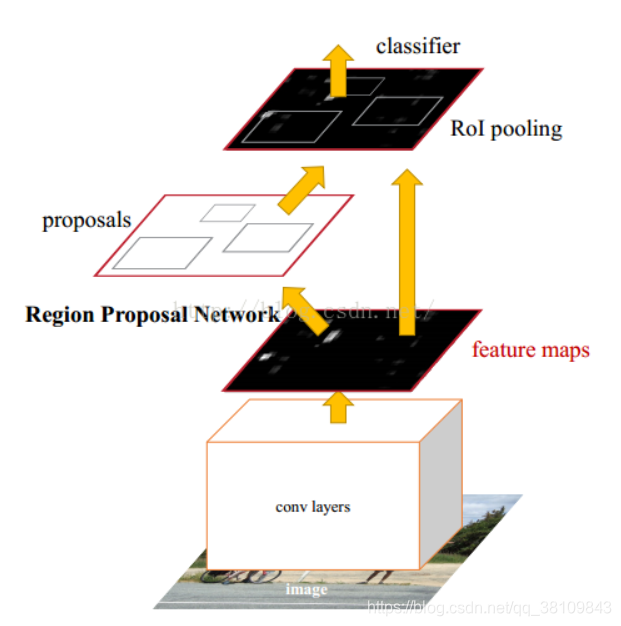
3.Faster RCNN
由两部分组成:
①PRN候选框提取模块;
②Fast R-CNN检测模块。
4.三者对比:
选择性搜索Selective Search(SS):
step0:生成区域集R,具体参见论文《Efficient Graph-Based Image Segmentation》
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
区域建议网络Region Proposal Network(RPN):
RPN在m,n特征图上会产生m * n * 9个anchor,计算每个产生的anchor和标注框的交并比IoU,大于0.7为前景,小于0.3为背景,去除0.3-0.7之间的anchor。对剩下的anchor输入RoIPooling层
图像哈希算法
1.均值哈希算法:
第一步,缩小尺寸。最快速的去除高频和细节,将图片缩小到8x8的尺寸,总共64个像素。摒弃不同尺寸、比例带来的图片差异。
第二步,简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
第三步,计算平均值。计算所有64个像素的灰度平均值。
第四步,比较像素的灰度。将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
第五步,计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
如果图片放大或缩小,或改变纵横比,结果值也不会改变。增加或减少亮度或对比度,或改变颜色,对hash值都不会太大的影响。最大的优点:计算速度快!
如果想比较两张图片,为每张图片构造hash值并且计算不同位的个数。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
2.感知哈希算法:
第一步,缩小尺寸。最快速的去除高频和细节,将图片缩小到8x8的尺寸,总共64个像素。摒弃不同尺寸、比例带来的图片差异。
第二步,简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
第三步,计算DCT(离散余弦变换)。DCT是把图片分解频率聚集和梯状形,虽然JPEG使用8 * 8的DCT变换,在这里使用32 * 32的DCT变换。
第四步,缩小DCT。虽然DCT的结果是32 * 32大小的矩阵,但我们只要保留左上角的8*8的矩阵,这部分呈现了图片中的最低频率。
第五步,计算平均值。计算所有64个值的平均值。
第六步,进一步减小DCT。这是最主要的一步,根据8 * 8的DCT矩阵,设置0或1的64位的hash值,大于等于DCT均值的设为”1”,小于DCT均值的设为“0”。结果并不能告诉我们真实性的低频率,只能粗略地告诉我们相对于平均值频率的相对比例。只要图片的整体结构保持不变,hash结果值就不变。能够避免伽马校正或颜色直方图被调整带来的影响。
第七步,计算哈希值。将64bit设置成64位的长整型,组合的次序并不重要,只要保证所有图片都采用同样次序就行了。将32 * 32的DCT转换成32 * 32的图像。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了(例如,自左到右、自顶向下、big-endian)。
得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算汉明距离。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
3.差异哈希算法
第一步,缩小尺寸,缩放到9 * 8尺寸。
第二步,转换灰度值,转换到0-255之间。
第三步,差异值计算,差异值是通过计算每行相邻像素的强度对比得出的。我们的图片为9 * 8的分辨率,那么就有8行,每行9个像素。差异值是每行分别计算的,也就是第二行的第一个像素不会与第一行的任何像素比较。每一行有9个像素,那么就会产生8个差异值,这也是为何我们选择9作为宽度,因为8bit刚好可以组成一个byte,方便转换为16进制值。
如果前一个像素的颜色强度大于第二个像素,那么差异值就设置为True(也就是1),如果不大于第二个像素,就设置为False(也就是0)。
第四步,转化为hash值,将差异值数组中每一个值看做一个bit,每8个bit组成为一个16进制值,将16进制值连接起来转换为字符串,就得出了最后的dHash值。
第五步,计算汉明距离,如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
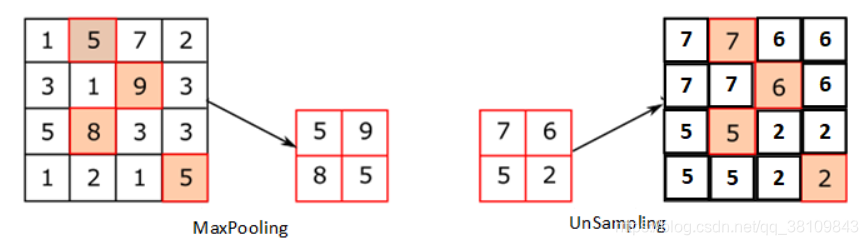
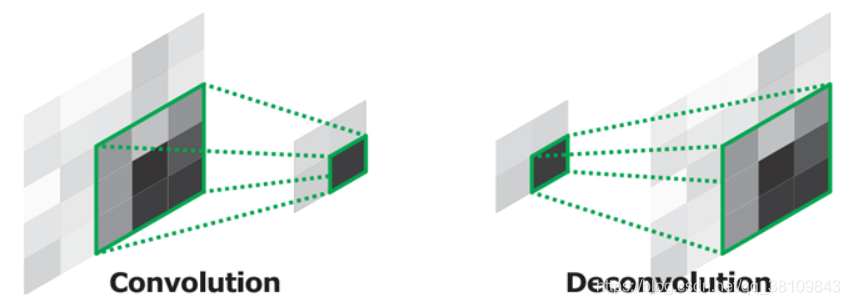
上池化,上采样,反卷积,空洞卷积的区别
1.上池化:
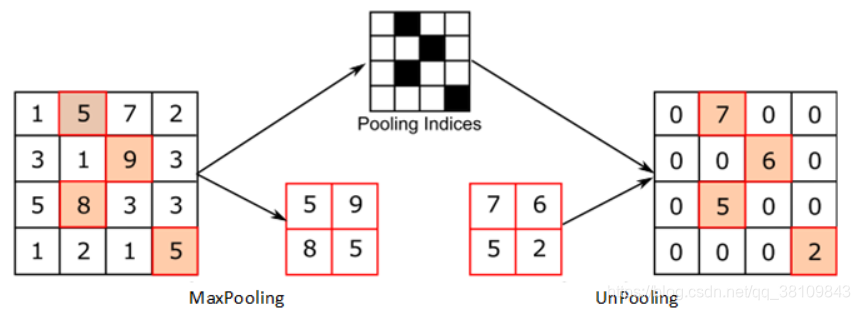
2.上采样:
3.反卷积:特征图补0,增大输出的特征图
4.空洞卷积:卷积核补0,增大感受野