一般的神经机器翻译模型(NMT)实现的是一种语言到另一种语言的翻译,也就是用在特定的语言对之间。最近一些工作开始将一般的NMT扩展到多语言的场景。目前两种通常的做法是:一、为每种源语言单独准备一个encoder,每种目标语言也准备一个decoder,然后encoder和decoder之间共享一个注意力层。二、不管源端和目标端多少种语言统一一个encoder,一个decoder,然后attention。
1.《Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder》:一个encoder-decoder
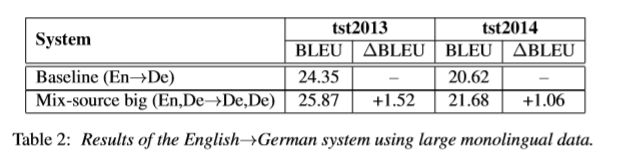
低资源平行语料(En->De)情况下:融合单语语料(De->De)或其他低资源平行语料(例如Fr->De)能够提升模型效果。

融合大量单语语料情况下:也可以提升模型效果。
零资源:有De->En,En->Fr的平行语料,没有单独De->Fr的平行语料,看看De->Fr的翻译效果。

一个箭头(->)代表一个模型,例如Direct(De->Fr)就是有平行语料的情况下训练一个模型,Pivot(De->En->Fr)就是训练两个模型,En作为中间语言。发现效果并不好。
2. 《Multilingual NMT with a language-indepent attention bridge》(2019ACL)独立的encoder,decoder+share attention