就业问题选择
摘要
毕业生在毕业之际,面临着就业选择问题。他们有阿里、百度和腾讯的选择,但也要考虑工作环境、工资待遇、发展前途、住房条件等因素。我们可以利用层次分析法来确定每个因素之间的比重,得到每个选择的综合评分,得到客观准确的分析来帮助毕业生进行选择。
目录
一、 问题的重述 2
一、 问题的重述
师兄师姐面临毕业,他们有三个选择,阿里,腾讯, 百度,有以下四个因素决定,分别是工作环境,工资待遇,发展前途,住房条件。过多的因素和选择让他们无法进行客观的分析,得到最优的选择。
二、模型假设
- 层次分析法的比较矩阵的权重都是根据专家判断来进行给出的,具有准确性
三、变量说明
| 符号 |
变量名称 |
| C1 |
工作环境 |
| C2 |
工资待遇 |
| C3 |
发展前途 |
| C4 |
住房条件 |
| P1 |
阿里 |
| P2 |
腾讯 |
| P3 |
百度 |
四、模型的建立与求解
利用层次分析法对准则层里的影响因素和方案层的选择进行权重分析,得到满足一致性检验的权重,对每个方案进行综合评价,得到综合得分来进行排序。
- 建立递阶的层次结构:根据对问题的分析,缕清问题所包含的因素,确定出各个因素之间的关联和隶属关系,按这些因素的共同特性,将它们分为目标层、准则层、方案层等多个层次。
- 建立两两判断矩阵:判断矩阵表示针对上一层次的某元素,本层次与它有关的元素之前相对重要性的比较。
表 1 判断矩阵的一般形式
| A |
B1 |
B2 |
…… |
Bn |
| B1 |
b11 |
b12 |
…… |
b1n |
| B2 |
b21 |
b22 |
…… |
b2n |
| …… |
…… |
…… |
…… |
…… |
| Bn |
bn1 |
bn2 |
…… |
bnn |
- 判断矩阵中的 bij 一般采用九分制标度法,根据资料数据、专家意见或者系统分析人员的经验,经过反复研究后确定。
两两比较尺度表

- 计算各元素权重:通过对判断矩阵的运算,计算出本层所有元素对上一层相关元素的权重,再利用单层次权重的计算结果,进一步综合出对更上一层次元素的权重。通过权重排序,挑选出最优方案。
2.1.层次分析法的原理
层次分析法,简称 AHP,是由美国匹兹堡大学教授 T.L.Satty 于 20 世纪 70 年代提出的一种多目标决策分析方法论 [1]。其原理是将与决策有关的因素分解成目标层、准则层、方案层等若干层次,通过对各因素的计算和比较,得出不同因素的权重,为决策者选择最优方案提供参考依据 [2]。
2.2.建立评价体系

先构建判断矩阵:
判断矩阵C1‐P
| C1 |
P1 |
P2 |
P3 |
| P1 |
1 |
2 |
4 |
| P2 |
1/2 |
1 |
2 |
| P3 |
1/4 |
1/2 |
1 |
判断矩阵C2-P
| C2 |
P1 |
P2 |
P3 |
| P1 |
1 |
1/3 |
1/8 |
| P2 |
3 |
1 |
1/3 |
| P3 |
8 |
3 |
1 |
判断矩阵C3-P
| C3 |
P1 |
P2 |
P3 |
| P1 |
1 |
1 |
3 |
| P2 |
1 |
1 |
3 |
| P3 |
1/3 |
1/3 |
1 |
判断矩阵C4-P
| C4 |
P1 |
P2 |
P3 |
| P1 |
1 |
3 |
4 |
| P2 |
1/3 |
1 |
1 |
| P3 |
1/4 |
1 |
1 |
判断矩阵〇-C
| 〇 |
C1 |
C2 |
C3 |
C4 |
| C1 |
1 |
1/2 |
4 |
3 |
| C2 |
2 |
1 |
7 |
5 |
| C4 |
1/4 |
1/7 |
1 |
1/2 |
| C4 |
1/3 |
1/5 |
2 |
1 |

第一步:计算一致性指标CI
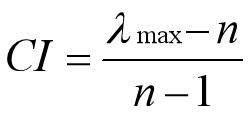
CI= 0.0072
第二步:查找对应的平均随机一致性指标RI

CR=0.0080
因为CR<0.10,所以该判断矩阵A的一致性可以接受。
第三步:计算每个因素的权重
| 影响因素 |
算术平均法 |
几何平均法 |
特征值法 |
| 工作环境 |
0.2880 |
0.2884 |
0.2884 |
| 工资待遇 |
0.5318 |
0.5329 |
0.5323 |
| 发展前途 |
0.0678 |
0.0674 |
0.0675 |
| 住房条件 |
0.1124 |
0.1113 |
0.1118 |
最终结果表格:
|
|
指标权重 |
阿里 |
腾讯 |
百度 |
| 工作环境 |
0.2884 |
0.5714 |
0.2857 |
0.1429 |
| 工资待遇 |
0.5323 |
0.0819 |
0.2363 |
0.6817 |
| 发展前途 |
0.0675 |
0.4286 |
0.4286 |
0.1429 |
| 住房条件 |
0.1118 |
0.6337 |
0.1919 |
0.1744 |
阿里的综合得分=0.2884*0.5714+0.5323*0.08+0.0675*0.4286+0.1118*0.6337
=0.308165
腾讯的综合得分=0.2884*0.2857+0.5323*0.2363+0.0675*0.4286+0.1118*0.1919
=0.258563
百度的综合得分=0.2884*0.1429+0.5323*0.6817+0.0675*0.1429+0.1118*0.1744
=0.433225

通过层次分析法,可以客观得出百度的综合分数最高,其次到阿里,最后到腾讯,每家公司评分相差不算非常大。
五、模型的评价与推广
5.1层次分析法优缺点分析
优点:系统性的分析方法。层次分析法把研究对象作为一个系统,按照分解、比较判断、综合的思维方式进行决策,成为继机理分析、统计分析之后发展起来的系统分析的重要工具。系统的思想在于不割断各个因素对结果的影响,而层次分析法中每一层的权重设置最后都会直接或间接影响到结果,而且在每个层次中的每个因素对结果的影响程度都是量化的,非常清晰明确。这种方法尤其可用于对无结构特性的系统评价以及多目标、多准则、多时期等的系统评价。
缺点:特征值和特征向量的精确求法比较复杂在求判断矩阵的特征值和特征向量时,所用的方法和我们多元统计所用的方法是一样的。在二阶、三阶的时候,我们还比较容易处理,但随着指标的增加,阶数也随之增加,在计算上也变得越来越困难。不过幸运的是这个缺点比较好解决,我们有三种比较常用的近似计算方法。第一种就是和法,第二种是幂法,还有一种常用方法是根法。
层次分析法求比较矩阵权值和一致性检验的代码
disp('请输入判断矩阵A')
A=input('A=');
[n,n] = size(A);
% % % % % % % % % % % % %方法1: 算术平均法求权重% % % % % % % % % % % % %
Sum_A = sum(A);
SUM_A = repmat(Sum_A,n,1);
Stand_A = A ./ SUM_A;
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2)./n)
% % % % % % % % % % % % %方法2: 几何平均法求权重% % % % % % % % % % % % %
Prduct_A = prod(A,2);
Prduct_n_A = Prduct_A .^ (1/n);
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
% % % % % % % % % % % % %方法3: 特征值法求权重% % % % % % % % % % % % %
[V,D] = eig(A);
Max_eig = max(max(D));
[r,c]=find(D == Max_eig , 1);
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% % % % % % % % % % % % %下面是计算一致性比例CR的环节% % % % % % % % % % % % %
CI = (Max_eig - n) / (n-1);
RI=[0 0.0001 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
% 这里n=2时,一定是一致矩阵,所以CI = 0,我们为了避免分母为0,将这里的第二个元素改为了很接近0的正数
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR<0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end