床头屋漏无干处,雨脚如麻未断绝。自经丧乱少睡眠,长夜沾湿何由彻。安得广厦千万间,大庇天下寒士俱欢颜。
这是杜甫的苦恼和远景。而现在的我们,身处在这个看脸的世界,多得不仅仅是物质的烦忧,更增添了各种与生俱来的伤痛。某一天发现自己上班丑的连人脸识别的系统都不愿意给你签到,那么真的痛!那么我们就来研究一下当前人脸识别到底是怎么回事。
人脸识别通俗的来说分为两部分:人脸检测和人脸识别,下面就来分步研究。
人脸检测
具体来说人脸检测就是找出一份图像上有没有人脸,如果有则反馈位置和大小。一般来说给定一个图像作为输入,要完成人脸检测需要经历一下三步:
- 选择图像上的某个矩形区域当做观察的窗口
- 在选定的图像上提取出来一些特征来描述本区域
- 根据提取出来的特征描述来判断是否正好框住了一个人脸
以上步骤是不断循环的,直到遍历完了所有窗口。对于图像来说,就是一个个的矩阵,黑白图像有一个矩阵,彩色图像有三个矩阵。如下图:
原图:
R分量:
G分量:

B分量:

灰度图:

为了方便说明下面以灰度图为准作为说明。

由上图可以可以看出,我们每次拿出来一张图片,都是按照像素点从左上角一行行的移动并且检测,直到结束于最后一行最后一列。
那么与此同时也产生出来了一个问题:如何选择我们的窗口呢,多大才算是合适的呢?
有一种方法就是选用不同的窗口对同一个图像做扫描,但是这样的做法并不高效。换一种角度,我们把图像进行不同程度的缩放,然后用同一个窗口去扫描,那么岂不是高效的多。这种做法就是构造图像金字塔的方式,如下图所示:
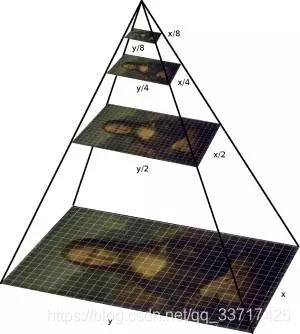
通过合适的窗口针对不同缩放程度的图像进行每行每列的扫描,这样就可以得到不同大小不同位置上的人脸了。因为人脸的特殊型,通常选择大小适宜的矩形框就可以。
在上一步,选好了窗口就对图像进行逐一的扫描,即对窗口框出来的图像进行分析和收集证据,我们管这个一个过程叫做特征提取。特征就是我们对图像的描述,因为对于机器而言,这些都是一堆堆的数据,因此提取出来的特征对于我们来说变现为一个向量,称之为特征向量,其每一维就是一个数值,这个数值是根据输入(框出来的图像)做一系列的运算得到的,例如:加减乘除卷积或者比较大小等。换言之就是把原始的图像经过一系列的变换得到特征向量,最后我们拿着这个特征向量进行分析。
拿到特征向量之后就到了决断的时候了,怎么样判断这个特征向量或者这个被框出来的图像正好是一张人脸呢?我们可以把这所有的窗口分为两类,一类是恰好包含人脸的窗口,一类是非人脸的窗口。而最终判别的过程就是一个对当前观察窗口进行分类的过程。因为我们的证据是由数值组成的特征向量,所以我们是通过可计算的数学模型来寻找真相的,用来处理分类问题的数学模型我们通常称之为分类器,分类器以特征向量作为输入,通过一系列数学计算,以类别作为输出——每个类别会对应到一个数值编码,称之为这个类别对应的标签,如将人脸窗口这一类编码为1,而非人脸窗口这一类编码为-1;分类器就是一个将特征向量变换到类别标签的函数。
考虑一个最简单的分类器:将特征向量每一维上的数值相加,如果得到的和超过某个数值,就输出人脸窗口的类别标签1,否则输出非人脸窗口的类别标签-1。记特征向量为
x = { x 1 , x 2 , x 3 , . . . , x n } x=\lbrace x1,x2,x3,...,x_n\rbrace x={
x1,x2,x3,...,xn}
那么分类器函数f(x)可以表示为:
f ( x ) = { − 1 ∑ i = 1 n x i ≤ m 1 ∑ i = 1 n x i ≥ m f(x)=\lbrace^{1 \sum^{n}_{i=1}x_i\geq m}_{-1 \sum^{n}_{i=1}x_i\leq m} f(x)={
−1 ∑i=1nxi≤m1 ∑i=1nxi≥m
这里面的m就是上面所说的某个数值。那么当我们找到这个m的时候就可以愉快的进行人脸检测了。
那么m怎么来确定呢?有一个目标就是判断被框出来那部分是不是个人脸,我们的愿景就是尽可能正确的把框有人脸的图像分到1的那个分类里面。但是即使是这样还是不能具体的给出这个数值是多少。于是转换思路,就是让机器去学习,最终让机器自己得到这个参数。那么我们所要提供的就是两个集合,一个是包含人脸的各种图片,一个是未包含人脸的。
由于采用滑窗的思想需要在不同大小的图像上进行每个位置上的运算提取特征再判断,我们假设一个256*256的图片那么它将产生的窗口总数就已经数万个了,那么如果是一个三通道的彩色图片并且图片大小为几兆的,那么产生的窗口已经大到把机器卡死的地步。面对这么大的数据,显然这种方法只能处于理论了。
随着时间的推移,人脸检测这部分出现了很多方法,大致分为两类:基于知识的方法和基于统计的方法
基于知识的方法:主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸。主要包括模板匹配、人脸特征、形状与边缘、纹理特性、颜色特征等方法。
基于统计的方法:将人脸看作一个整体的模式——二维像素矩阵,从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量来判断人脸是否存在。主要包括主成分分析与特征脸、神经网络方法、支持向量机、隐马尔可夫模型、Adaboost算法等。
下面就来分别介绍它们之中其中的一种Haar和SVM支持向量机

Haar
Haar里面包含了Adaboost的算法,它的要点为:
- 使用Haar-like特征做检测。
- 使用积分图(Integral Image)对Haar-like特征求值进行加速。
- 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
- 使用筛选式级联把强分类器级联到一起,提高准确率
Haar特征
Haar特征分为四类:边缘特征、线性特征、中心特征和对角线特征,将这些特征组合成特征模板。如下:
边缘特征、线性特征
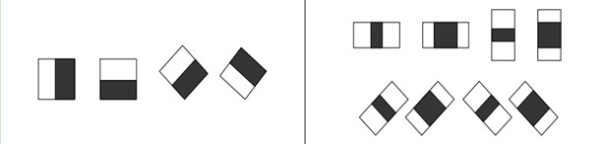
中心特征和对角特征
特征模板内有白色和黑色两种矩形,定义:该模板的特征值为白色矩形像素和‘减’去黑色矩形像素和。 我们希望当把矩形放到人脸区域计算出来的特征值和放到非人脸区域计算出来的特征值差别越大越好,这样就可以用来区分人脸和非人脸。


观察人脸我们可以得出一些简单的描述,例如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。所以Haar就是通过不断改变模板的大小、位置、类型,来用白色矩形框的像素和减黑色矩形框的像素和,依次来得到每种模型的大量子特征。
即使现在这样它的计算也不够快,因为每次的改变模板都要重新计算个个矩形的像素之和。针对这种情况Haar引入了积分图来简化特征提取的计算量。
积分图
积分图是一张和输入图像一样大的图,但其每个点上不再是存放这个点的灰度值,而是存放从图像左上角到该点所确定的矩形区域内全部点的灰度值之和。如下图:
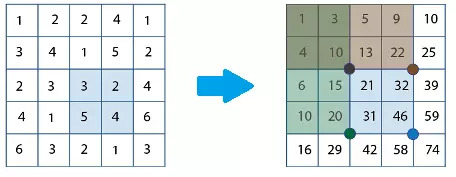
由上图我们可以发现,积分图上的每一点的值就是其所在位置的所有行和列的像素点之和。那么怎么样用积分图来算出上图左边蓝色选中框的像素和呢?如下图:
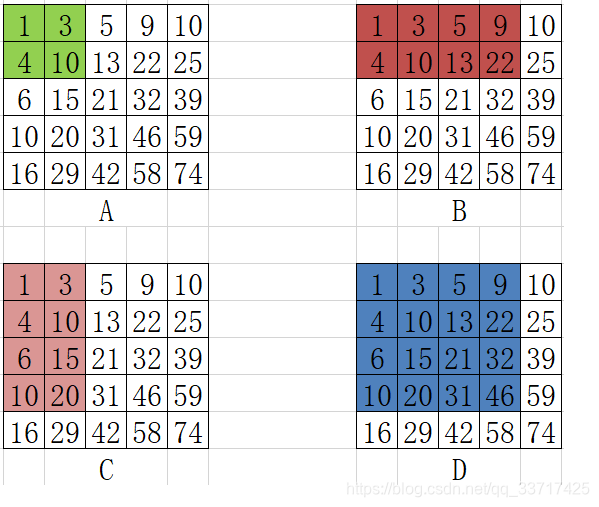
矩 形 的 面 积 = S D − ( S C + S B − S A ) 矩形的面积=S_D-(S_C+S_B-S_A) 矩形的面积=SD−(SC+SB−SA)
所以运用积分图就可以很快的算出想要矩形的像素点之和,而且只需初次的时候算一遍个个小矩形的像素和,后面就直接可以各种复用了。
级联分类器
除了上面特征提取的速度之外,分类的速度也是至关重要。由此分类的速度取决于分类器的复杂程度,也同样是由特征向量变换到类别标签计算的复杂程度。复杂的分类器具有很强的分类能力,但是换来的是计算代价更高。计算小的分类能力却很弱,准确率也很低。此时这两者有机的结合方法出现了,就是Adaboost方法和级联分类器结构。
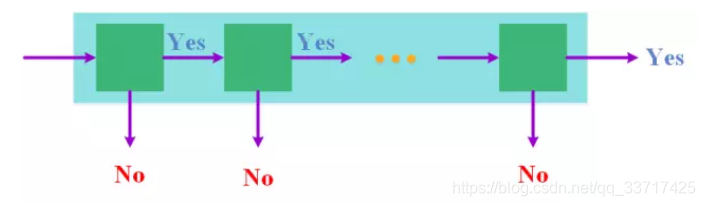
级联分类器其实就是许多个弱分类器一级一级的串联起来,最终变成了一个强的分类器,即:聚弱变强。而每一个弱的分类器又是由Adaboost方法简化计算,这样能极大效率的提升分类的总体效能。具体说来,Haar的级联分类器将多个分类器级联在一起,从前往后,分类器的复杂程度和计算代价逐渐增大,对于给定的一个窗口,先由排在最前面也最简单的分类器对其进行分类,如果这个窗口被分为非人脸窗口,那么就不再送到后面的分类器进行分类,直接排除,否则就送到下一级分类器继续进行判别,直到其被排除,或者被所有的分类器都分为人脸窗口。这样设计的好处是显而易见的,每经过一级分类器,下一级分类器所需要判别的窗口就会减少,使得只需要付出非常少的计算代价就能够排除大部分非人脸窗口。从另一个角度来看,这实际上也是根据一个窗口分类的难度动态地调整了分类器的复杂程度,这显然比所有的窗口都用一样的分类器要更加高效。
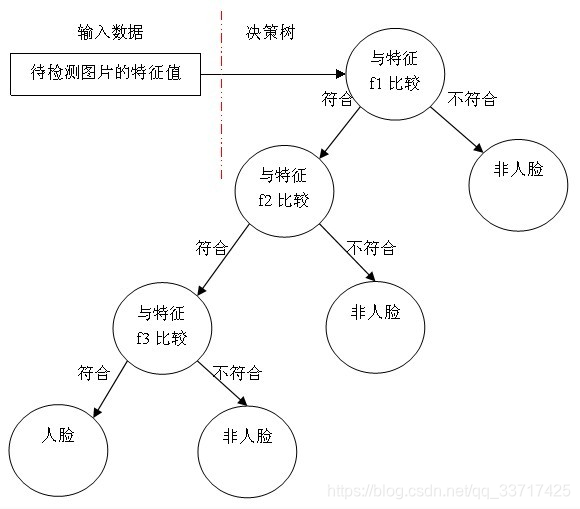
一个弱分类器就是一个基本和上图类似的决策树,最基本的弱分类器只包含一个Haar-like特征,也就是它的决策树只有一层,被称为树桩。
以20*20图像为例,78,460个特征,如果直接利用AdaBoost训练,那么工作量是极其极其巨大的。所以必须有个筛选的过程,筛选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost进行训练。最后,组合所有的弱分类器形成强分类器,通过比较这些弱分类器投票的加权和与平均投票结果来检测图像。
SVM 支持向量机
https://baijiahao.baidu.com/s?id=1607469282626953830&wfr=spider&for=pc
人脸识别
CNN卷积神经网络介绍
人脸对齐
人脸对齐
人脸对齐
PCA
PCA总结:
在二维的坐标空间内,找到一个单位向量U,使得所有数据在U上的投影之和最大。这样就能把数据分的尽可能的开。然后把训练样本投影到这个向量U上,把测试图片也投影上去,计算这个投影与各个样本人脸投影的欧式距离,得出最小的欧式距离的的那个样本编号,就是最大概率的人脸。
未完待续。。。