前言
Kafka最初是由LinkedIn公司采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分式消息系统,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
Apache Kafka是一个分布式的发布-订阅消息系统,能够支撑海量数据的数据传递。在离线和实时信息处理业务系统中,Kafka都有广泛的应用。Kafka将消息持久化到磁盘中,并对消息创建了备份保证数据的安全。Kafka在保证了较高的处理速度的同时,又能保证数据处理的低延迟和数据的零丢失。
Kafka技术优势
可伸缩性:Kafka 的两个重要特性造就了它的可伸缩性。
1、Kafka 集群在运行期间可以轻松地扩展或收缩(可以添加或删除代理),而不会宕机。
2、可以扩展一个 Kafka 主题来包含更多的分区。由于一个分区无法扩展到多个代理,所以它的容量受到代理磁盘空间的限制。能够增加分区和代理的数量意味着单个主体可以存储的数据量是没有限制的。
容错性和可靠性:Kafka 的设计方式使某个代理的故障能够被集群中的其他代理检测到。由于每个主题都可以在多个代理上复制,所以集群可以在不中断服务的情况下从此类故障中恢复并继续运行。
吞吐量:代理能够以超快的速度有效地存储和检索数据。
摊牌了,以上内容全都出自某位架构大牛的Kafka笔记中,看完之后实在是受益匪浅,看得出笔记的作者是非常用心编写,每一处都是细节,一字一图都是大牛的心血,所以今天分享给大家一起学习下大牛是多么的优秀,由于篇幅原因文中就只展示目录和内容截图,有需要Kafka笔记完整文档可在文末获取免费领取方式!
笔记适应人群
此笔记为专注于使用Apache Kafka消息传递系统或者大数据分析领域发展事业的专业人士做好准备,它将给你足够的理解如何使用Kafka集群。
笔记亮点
- l 知识覆盖度广泛;
- l 知识覆盖度深入;
- l 由浅入深讲解思路;
- l 案例分析全面;
- l 适应于想学习Kafka技术的不同人群;
由于篇幅原因,有需要Kafka笔记完整文档获取方式放在文末了有需要的自取!!
第一天:1—4章
- 知识体系学习导图:
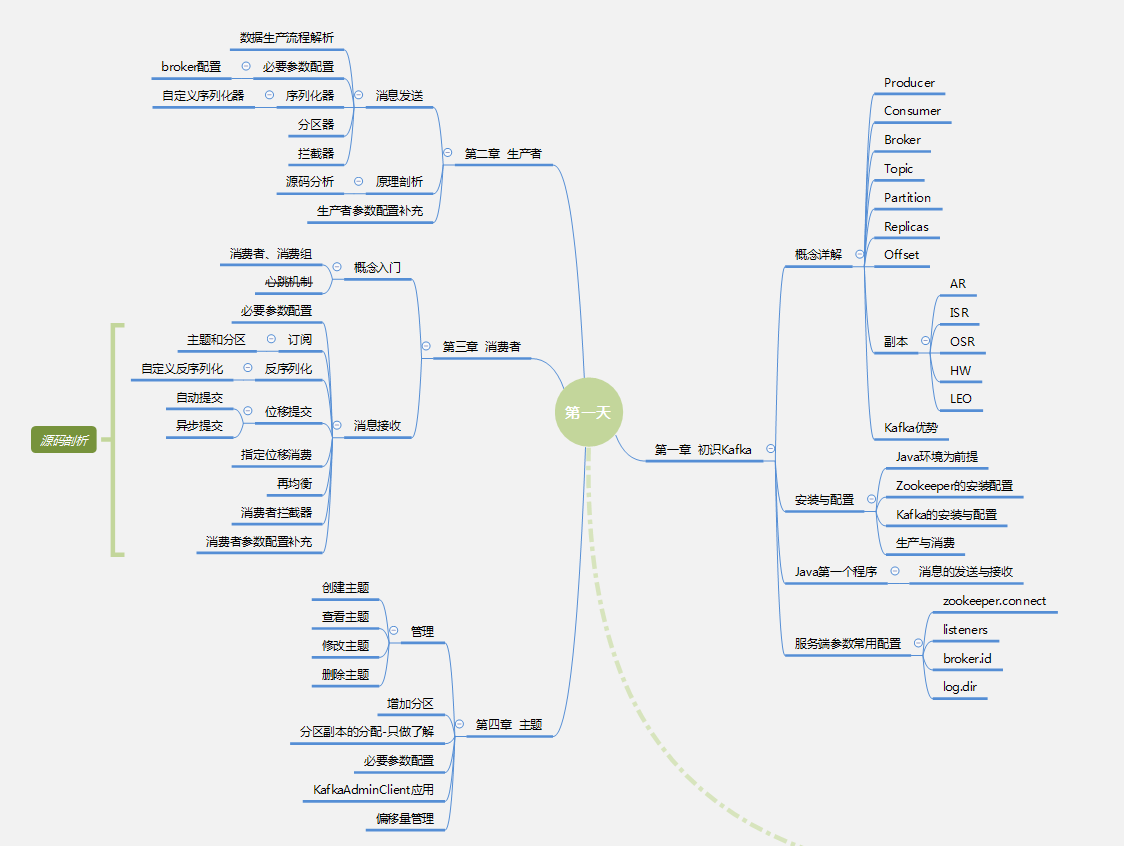

- 目录:

1,初识Kafka
tips 学完这一章你可以 知道Kafka基本原理,了解关键术语概念 可以使用Kafka进行消息系统开发 通过Java语言来使用Kafka进行消息收发

2,生产者详解
tips 学完这一章你可以 深入学习Kafka数据生产大致流程 如何创建并使用Kafka生产者 Kafka生产者常用配置

3,消费者详解
tips 学完这一章你可以、深入学习Kafka数据消费大致流程 如何创建并使用Kafka消费者 Kafka消费者常用配置
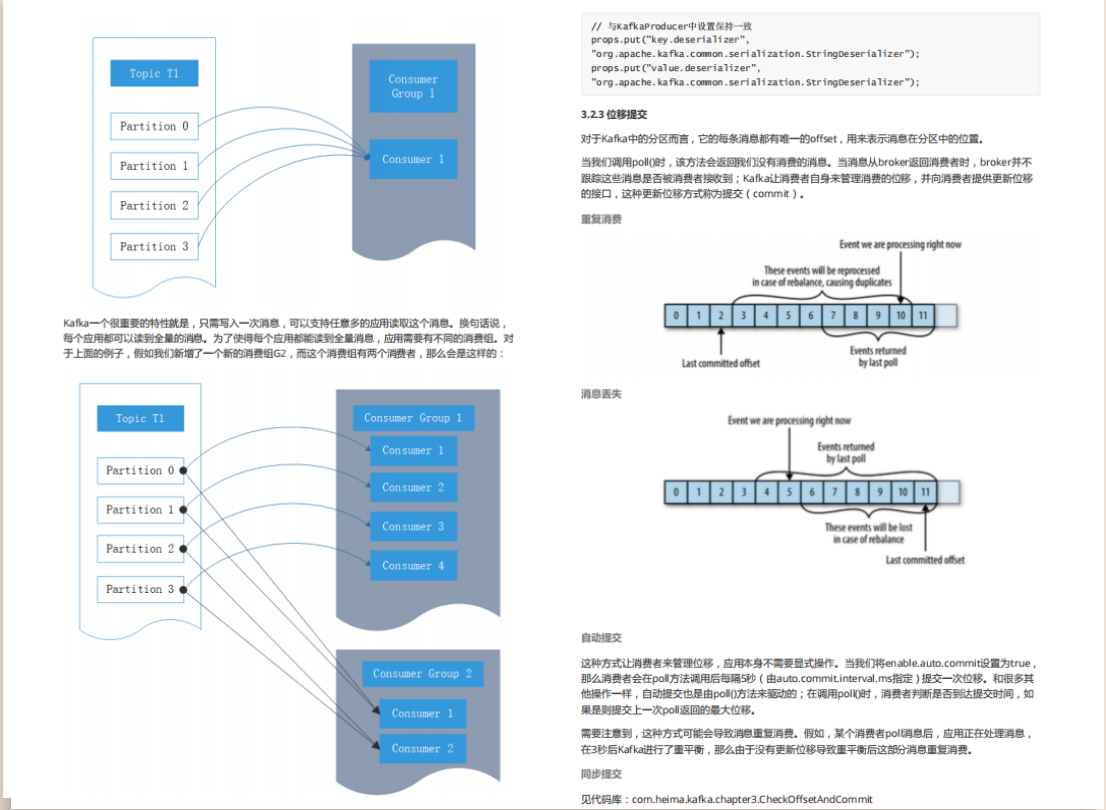
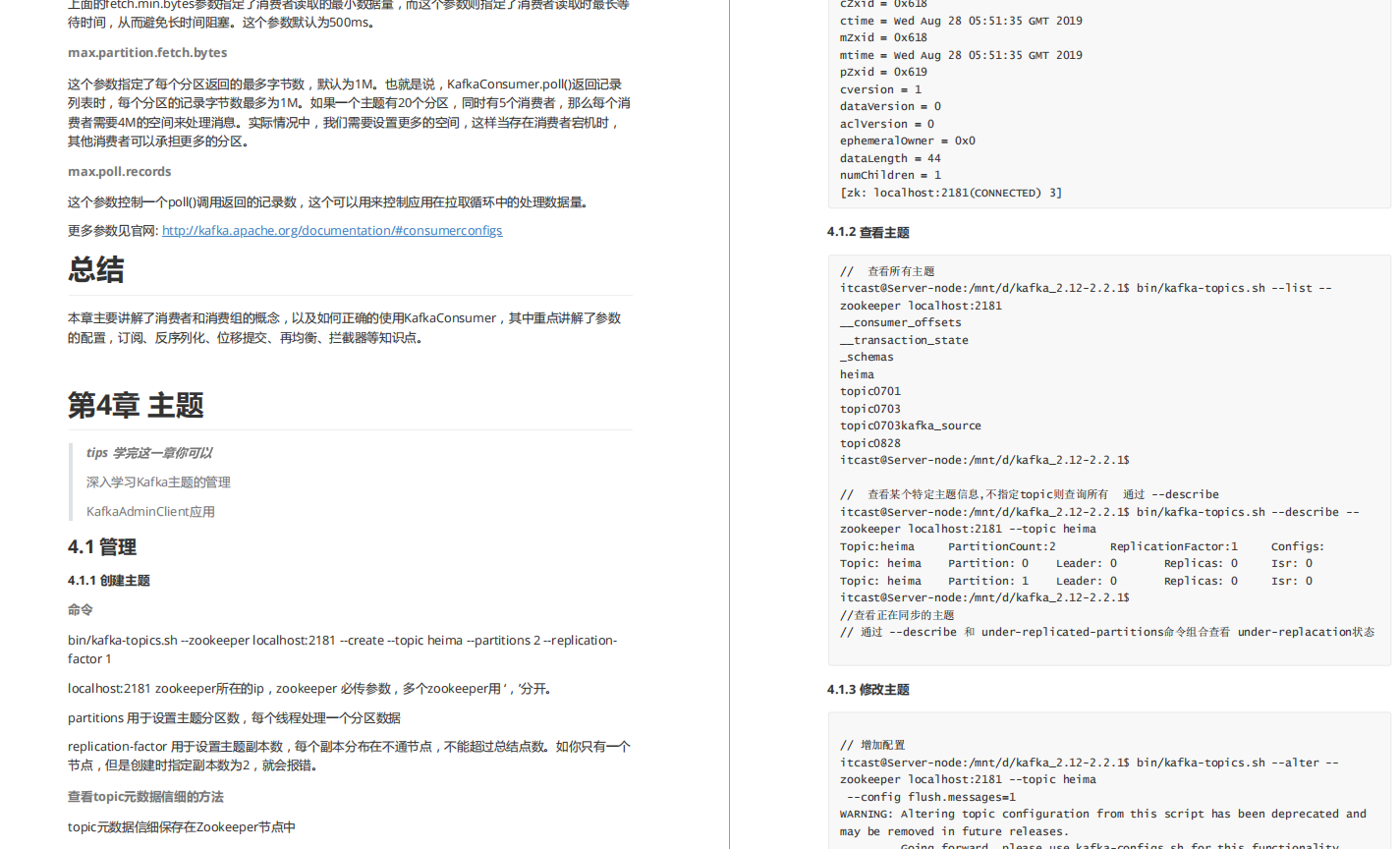
4,主题
tips 学完这一章你可以 深入学习Kafka主题的管理 KafkaAdminClient应用
第二天:5—7章
- 知识体系学习导图:
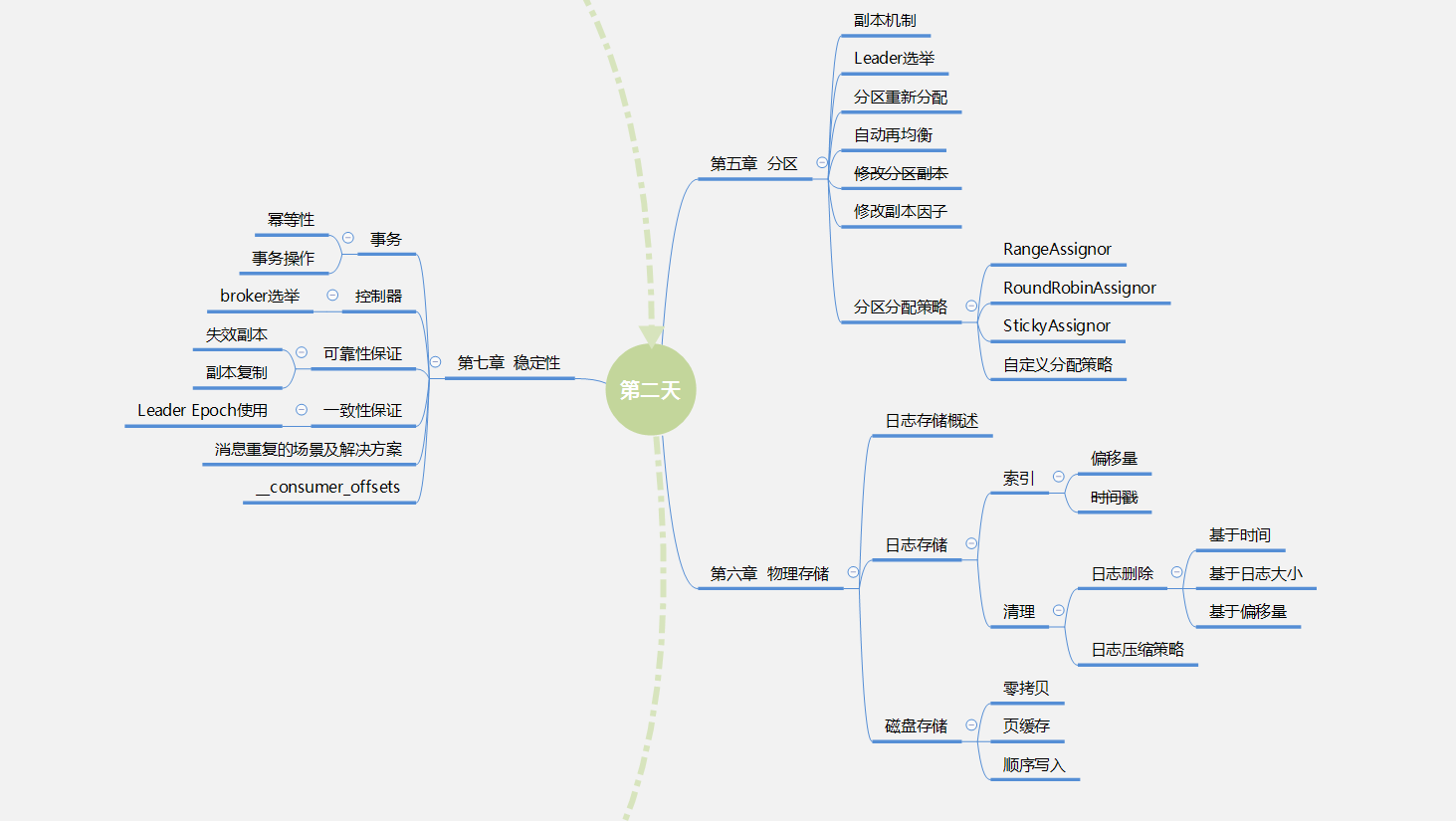
- 目录:

5,分区
tips 学完这一章你可以*** 深入学习Kafka分区的管理 包括:优先副本的选举、分区重新分配等

6,Kafka存储
tips 学完这一章你可以*** 在完成Kafka应用开发的基础上,知道文件存储机制 Kafka为什么使用磁盘作为存储介质 分析文件存储格式 快速检索消息

7,稳定性
tips 学完这一章你可以 深入学习Kafka在保证高性能、高吞吐的同时通过各种机制来保证高可用性

第三天:8—10章
- 知识体系学习导图:
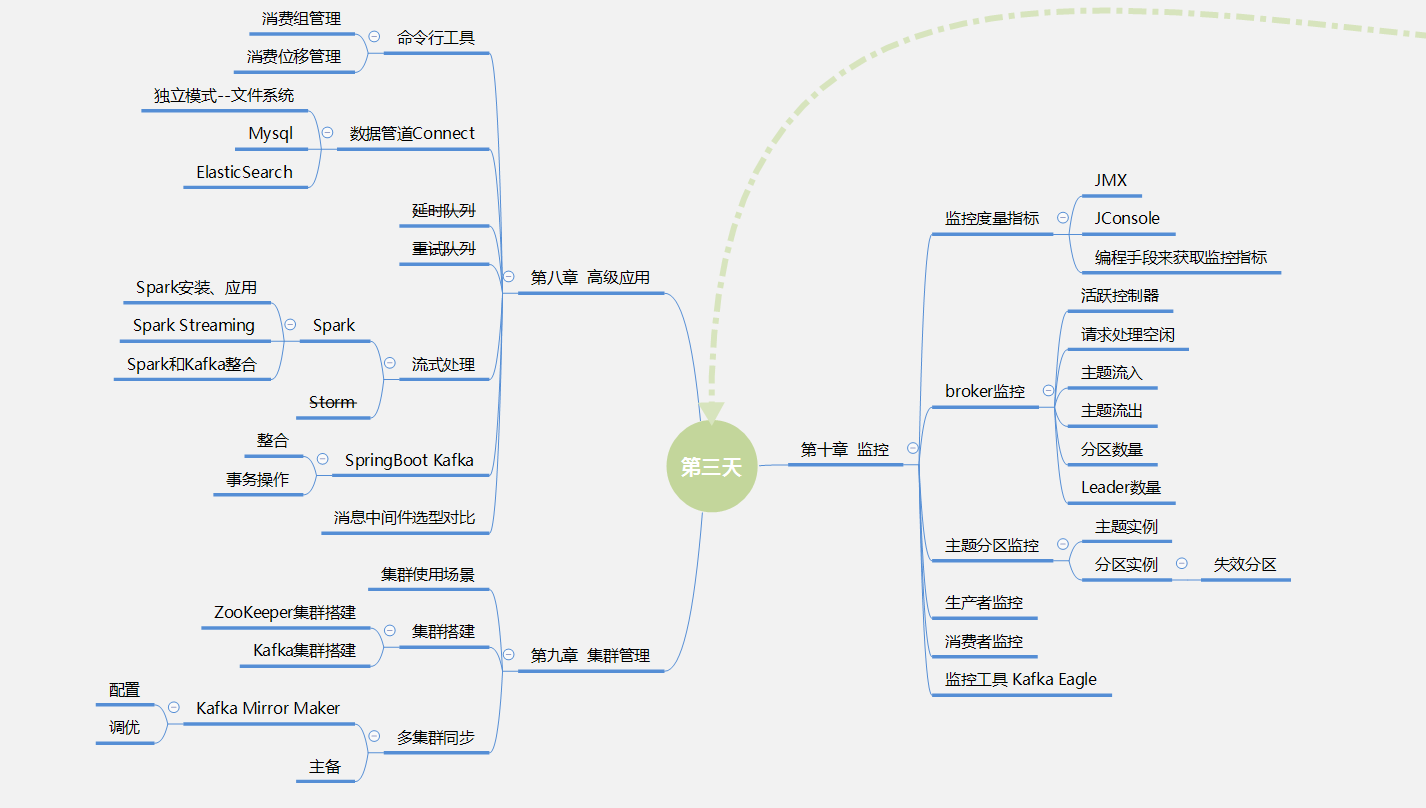
- 目录:

8,高级应用
tips 学完这一章你可以 作为运维人员掌握命令行工具 使用Connect进行流信息处理 掌握延迟消息等 Kafka和SpringBoot整合

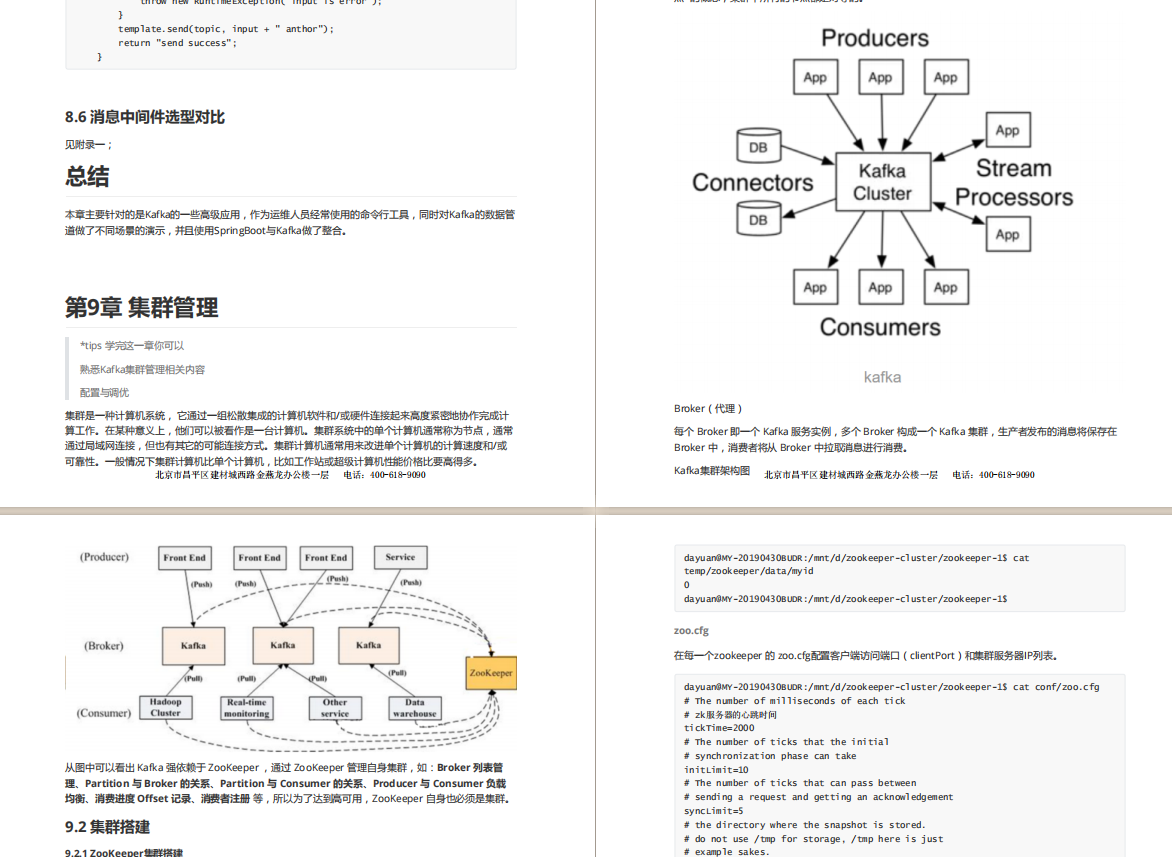
9,集群管理
tips 学完这一章你可以 熟悉Kafka集群管理相关配置与调优
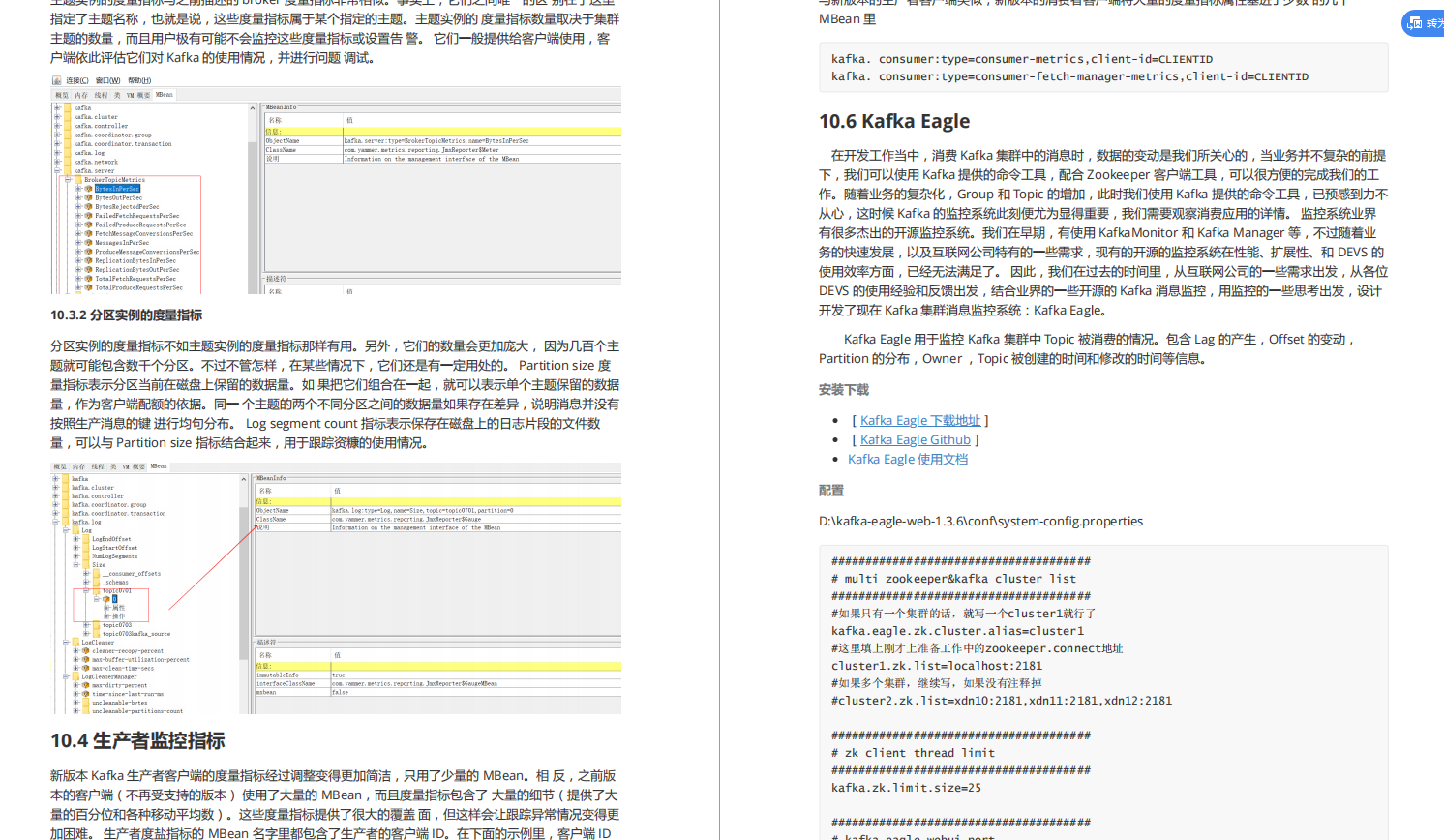
10,监控
*tips 学完这一章你可以 知道Kafka的监控体系 掌握JMX监控指标 数据异动实时提醒
由于篇幅原因,为了不影响阅读在这就展示了整个目录和内容截图 ,已经整理成文档的Kafka笔记有需要的朋友麻烦转发后关注下方公众号即可获取资料免费领取方式!