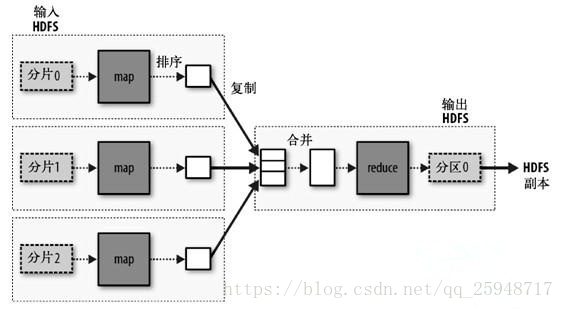
MapReduce编程模型
MapReduce采用“分而治之”的思想。将HDFS上海量数据切分成为若干块,将每块的数据分给集群上的节点进行计算。然后通过整合各节点的中间结果,得到最终的结果。
HDFS上默认块的大小要比磁盘默认的大小大的多。其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间明显大于定位这个块开始位置所需时间。这样,传输一个由多个块组成的文件时间取决于磁盘传输速率。HDFS默认块的大小为128MB。随着磁盘驱动器的进一步发展块的默认大小可以设置的更大。
MapReduce的处理过程
一个复杂的MapReduce任务可以分为若干个Job。每个Job又可以分为Mapper和Reducer两个阶段。这两个阶段对应到代码内就是继承Mapper的内部类和继承Reducer的内部类。继承Mapper的内部类需要实现map函数,继承Reducer的内部类需要实现Reduce函数。Map函数接收一个<key,value>的键值对同时也会输出一个 <key,value> 的键值对。Reduce函数接收一个<key,list of values>(值为所有键为key的value集合,例如: map的输出为<1,1>,<1,2>,<1,3>,<1,4>则reduce的输入为<1,[1,2,3,4]>)同时经过处理后同样会输出<key,value>键值对。MapReduce运行过程的数据流。