Android Parcel浅析
简介

都说Parcel高效,android framework层大量使用Parcel,尤其是涉及Binder通信模块,大量的跨进程(IPC)通信,使用到Parcel进行数据传递,而且官方建议Bundle使用更换为Parcel,序列化方面也建议使用Parcelable替代,那为什么Parcel高效呢,今天我就试试从底层的角度来分析分析,如有不对的还望指正
为什么Bundle和Serializble差那么点意思?
简单说下下,Bundle内部采用的map键值对存储,大家都知道map去get时都是要取hash计算,移动链表找到值,有一定的时间复杂度;
而Serializble呢,功能确实很强大,但是序列化时容易产生很多临时变量,这对于GC的话又是一定的负担;
那为什么Parcel就高效呢?
简单来说,Parcel是在native层实现的,直接对内存操作,读取数据时都是在一个大的int8_t*指针下进行的,根据这个指针以及偏移值读取和写入数据,从读取效率来说是很高的,根据指针和偏移来读取,而没有经过算法去读取,也不会对虚拟机造成GC负担
Parcel原理剖析
Pacel复用池Pool
从java层入手,可以看到Parcel很多读写read/write操作都是native方法,里面重点关注他的Parcel Pool复用池,也就是提前分配好很多Parcel对象,直接从Pool里面拿,用完后归还给Pool池,提高了分配效率,对于一些频繁使用的场景,也解决了内存碎片和抖动的问题
public static Parcel obtain() {
final Parcel[] pool = sOwnedPool;
synchronized (pool) {
Parcel p;
for (int i=0; i<POOL_SIZE; i++) {
//从池子中拿出Parcel,并对pool数组i置为null
p = pool[i];
if (p != null) {
pool[i] = null;
if (DEBUG_RECYCLE) {
p.mStack = new RuntimeException();
}
p.mReadWriteHelper = ReadWriteHelper.DEFAULT;
return p;
}
}
}
return new Parcel(0);
}
public final void recycle() {
if (DEBUG_RECYCLE) mStack = null;
freeBuffer();
final Parcel[] pool;
if (mOwnsNativeParcelObject) {
pool = sOwnedPool;
} else {
mNativePtr = 0;
pool = sHolderPool;
}
synchronized (pool) {
for (int i=0; i<POOL_SIZE; i++) {
//使用完后,归还给pool
if (pool[i] == null) {
pool[i] = this;
return;
}
}
}
}
android中很多场景都用到了复用池这一技术,如Handler里面的Message
Parcel Native层剖析
基于android8.0源码环境,Parcel位于:
/frameworks/native/libs/binder/include/binder/Parcel.h
/frameworks/native/libs/binder/Parcel.cpp
首先,Parcel类重点关注这几个变量属性:
uint8_t* mData; //数据都是装到这个指针指向的内存
size_t mDataSize; //当前存储的数据大小
size_t mDataCapacity; //mData目前总的容量大小(可能有部分空闲的)
mutable size_t mDataPos; //mData的有效数据长度,后续写入数据都从这里开始写入
binder_size_t* mObjects; //记录写入对象Object偏移数组,写入对象时有用
size_t mObjectsSize; //当前mObjects数组中有数据的长度,写入对象时有用
size_t mObjectsCapacity; //mObjects的总长度,写入对象时有用
我们大致浏览下Parcel的方法,如下图:
追踪这些方法,最终都会走到如下这个方法里面去:
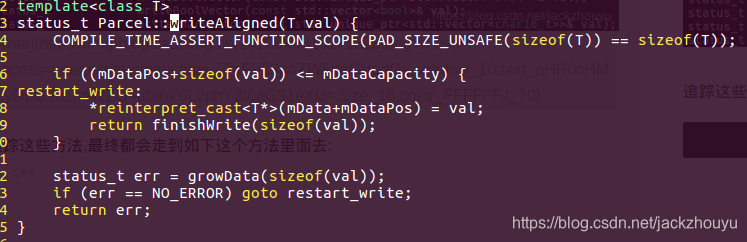
字节对齐写入方法:
a. 宏定义COMPILE_TIME_ASSERT_FUNCTION_SCOPE主要是确定要字节对齐,是4或者4的整数倍
b. if条件这块,判断有效数据长度加上当前写入值value有没有超过总容量,没有超过的话就直接给mData+mDataPos位置处写入val;超过的话就要增加mData数据长度,然后重走restart_write代码快
reinterpret_cast<T>(mData+mDataPos) = val;等式左边是先偏移mDataPos指针,然后将该指针解释为T*指针,然后在解指针,将val值拷贝到mData中去,拷贝的方式按照val的数据类型长度写入,而不是按照mData类型写入
mData数据扩张,看growData函数
status_t Parcel::growData(size_t len)
{
if (len > INT32_MAX) {
// don't accept size_t values which may have come from an
// inadvertent conversion from a negative int.
return BAD_VALUE;
}
//扩展为之前的1.5倍
size_t newSize = ((mDataSize+len)*3)/2;
return (newSize <= mDataSize)
? (status_t) NO_MEMORY
: continueWrite(newSize);
}
按照逻辑走,会进入continueWrite这个函数中去,该函数代码较长,只抽取关键部分代码
status_t Parcel::continueWrite(size_t desired)
{
//省略部分逻辑
//重新分配内存,desired是扩容后的长度
uint8_t* data = (uint8_t*)malloc(desired);
if (!data) {
mError = NO_MEMORY;
return NO_MEMORY;
}
if (mData) {
//数据拷贝
memcpy(data, mData, mDataSize < desired ? mDataSize : desired);
}
//重新赋值,更新长度size和容量capcity等
mData = data;
mObjects = objects;
mDataSize = (mDataSize < desired) ? mDataSize : desired;
ALOGV("continueWrite Setting data size of %p to %zu", this, mDataSize);
mDataCapacity = desired;
mObjectsSize = mObjectsCapacity = objectsSize;
mNextObjectHint = 0;
//省略部分逻辑
}
这里走完后,就会返回到writeAligned函数里面的restart_write里面去,写入val;另外,在read读取时也是根据偏移mDataPos和mData确定读取值的位置,在用reprinter_cast进行二进制拷贝出去,完成读取;以上就是Parcel浅析过程,如有不对望指正
除以上基本的数据类型外,有时还会往Parcel里面写入Object或者struct数据结构体,当只写入一个对象时还好,如果在一个Parcel对象里面写入多个对象时,在读取时,我们如何确定每个读取每个对象从哪里开始读,从哪里开些读取完成呢?This is a problem!
解决版本就是文章前面的几个对象mObjects/mObjectsSize/mObjectsCapacity,其核心思路就是没写入一个Object时,记录写入前的mDataPos偏移,将他存放在mObjects[mObjectsSize]处,mObjectsSize在自增1,依次写入的每个Object都是按照这么处理,当读取时倒序读取,从mObjects[mObjectsSize]最后的一个开始读,拿到偏移offset,从当前位置向后读完mData即可,依次读取
看看写入对象的源码就知道了:
status_t Parcel::writeObject(const flat_binder_object& val, bool nullMetaData)
{
判断mData加当前参数数据长度有否超过容量
const bool enoughData = (mDataPos+sizeof(val)) <= mDataCapacity;
判断mObjectsSize是否小于总的Objects容量
const bool enoughObjects = mObjectsSize < mObjectsCapacity;
内存充足
if (enoughData && enoughObjects) {
restart_write:
二进制拷贝到mData+mDataPos偏移处
*reinterpret_cast<flat_binder_object*>(mData+mDataPos) = val;
。。。。。。
同事记录偏移
if (nullMetaData || val.binder != 0) {
mObjects数组记录这个写入对象的mDataPos偏移
mObjects[mObjectsSize] = mDataPos;
acquire_object(ProcessState::self(), val, this, &mOpenAshmemSize);
同时size自增
mObjectsSize++;
}
return finishWrite(sizeof(flat_binder_object));
}
如果mData也就是存放数据的数组长度不够,就重新分配内存在拷贝过来
if (!enoughData) {
const status_t err = growData(sizeof(val));
if (err != NO_ERROR) return err;
}
如果存放偏移的数组mObjects长度不够也要重新为他分配内存
if (!enoughObjects) {
重新计算长度
size_t newSize = ((mObjectsSize+2)*3)/2;
if (newSize < mObjectsSize) return NO_MEMORY; // overflow
重新分配内存
binder_size_t* objects = (binder_size_t*)realloc(mObjects, newSize*sizeof(binder_size_t));
if (objects == NULL) return NO_MEMORY;
重新设置mObject相关变量
mObjects = objects;
mObjectsCapacity = newSize;
}
goto restart_write;
}
以上代码主要的任务就是,写入数据到mData中,同时记录写入的偏移mDataPos到mObjects数组中去;读取时,根据这个偏移去读取即可
java层的Parcel和Native层的Parcel有什么关系?
实质结论是,他们是一一对应的,Parcel.java有一个long型变量,保存了natvie层Parcel.cpp的指针,java层写入/读取数据都是通过这个指针,将数据写入到Native层去的,看看java层的部分代码:
保存了native层的指针
private long mNativePtr;
public final void writeInterfaceToken(String interfaceName) {
写入数据就通过这指针写入到native层对象
nativeWriteInterfaceToken(mNativePtr, interfaceName);
}
总结
从Parcel逻辑大致可以获取两个点:
- 对于频繁使用某些实例,追求一定的效率(包括内存),可以采用对象复用池技术
- 对于一些需要高效的存储和读取数据场景,可以使用这种对内存直接操作,指针加偏移快速搞定