模型融合

一 内容介绍
模型融合是比赛后期一个重要的环节,大体来说有如下的类型方式。
简单加权融合:
回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
分类:投票(Voting)
综合:排序融合(Rank averaging),log融合
stacking/blending:
构建多层模型,并利用预测结果再拟合预测。
boosting/bagging(在xgboost,Adaboost,GBDT中已经用到):
多树的提升方法
这里推荐自己大概看过的两篇文章:
模型融合:kaggle比赛胜出的杀手锏
模型融合:bagging、Boosting、Blending、Stacking
二 Stacking相关理论介绍
1.什么是 stacking
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
简单来说 stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。

2) 如何进行 stacking

过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
三 代码示例
1 回归\分类概率-融合:

1)简单加权平均,结果直接融合
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6]
import numpy as np
import pandas as pd
## 定义结果的加权平均函数
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
from sklearn import metrics
# 各模型的预测结果计算MAE
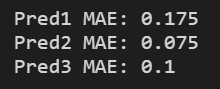
print('Pred1 MAE:',metrics.mean_absolute_error(y_test_true, test_pre1))
print('Pred2 MAE:',metrics.mean_absolute_error(y_test_true, test_pre2))
print('Pred3 MAE:',metrics.mean_absolute_error(y_test_true, test_pre3))
## 根据加权计算MAE
w = [0.3,0.4,0.3] # 定义比重权值
Weighted_pre = Weighted_method(test_pre1,test_pre2,test_pre3,w)
print('Weighted_pre MAE:',metrics.mean_absolute_error(y_test_true, Weighted_pre))

可以发现加权结果相对于之前的结果是有提升的,这种我们称其为简单的加权平均。
还有一些特殊的形式,比如mean平均,median平均
## 定义结果的加权平均函数
def Mean_method(test_pre1,test_pre2,test_pre3):
Mean_result = pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).mean(axis=1)
return Mean_result
Mean_pre = Mean_method(test_pre1,test_pre2,test_pre3)
print('Mean_pre MAE:',metrics.mean_absolute_error(y_test_true, Mean_pre))

## 定义结果的加权平均函数
def Median_method(test_pre1,test_pre2,test_pre3):
Median_result = pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).median(axis=1)
return Median_result
Median_pre = Median_method(test_pre1,test_pre2,test_pre3)
print('Median_pre MAE:',metrics.mean_absolute_error(y_test_true, Median_pre))

2) Stacking融合(回归):
from sklearn import linear_model
def Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,test_pre1,test_pre2,test_pre3,model_L2= linear_model.LinearRegression()):
model_L2.fit(pd.concat([pd.Series(train_reg1),pd.Series(train_reg2),pd.Series(train_reg3)],axis=1).values,y_train_true)
Stacking_result = model_L2.predict(pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).values)
return Stacking_result
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
train_reg1 = [3.2, 8.2, 9.1, 5.2]
train_reg2 = [2.9, 8.1, 9.0, 4.9]
train_reg3 = [3.1, 7.9, 9.2, 5.0]
# y_test_true 代表第模型的真实值
y_train_true = [3, 8, 9, 5]
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6]
model_L2= linear_model.LinearRegression()
Stacking_pre = Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,
test_pre1,test_pre2,test_pre3,model_L2)
print('Stacking_pre MAE:',metrics.mean_absolute_error(y_test_true, Stacking_pre))

2 分类模型融合:
from sklearn.datasets import make_blobs
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
from sklearn.metrics import accuracy_score,roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
1)Voting投票机制:
'''
硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
'''
iris = datasets.load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.7,
colsample_bytree=0.6, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=50, max_depth=1, min_samples_split=4,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1)
# 硬投票
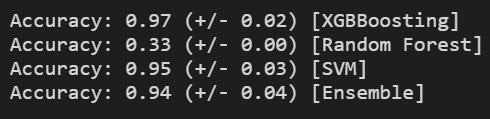
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('svc', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
'''
软投票:和硬投票原理相同,增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
'''
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.8,
colsample_bytree=0.8, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=50, max_depth=1, min_samples_split=4,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1, probability=True)
# 软投票
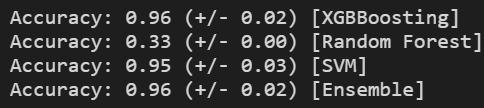
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('svc', clf3)], voting='soft', weights=[2, 1, 1])
clf1.fit(x_train, y_train)
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
2)分类的Stacking\Blending融合:
stacking是一种分层模型集成框架。
以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型, stacking两层模型都使用了全部的训练数据。
'''
5-Fold Stacking
'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier,GradientBoostingClassifier
import pandas as pd
#创建训练的数据集
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(solver='lbfgs'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
#5折stacking
n_splits = 5
skf = StratifiedKFold(n_splits)
skf = skf.split(X, y)
for j, clf in enumerate(clfs):
#依次训练各个单模型
dataset_blend_test_j = np.zeros((X_predict.shape[0], 5))
for i, (train, test) in enumerate(skf):
#5-Fold交叉训练,使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
#对于测试集,直接用这k个模型的预测值均值作为新的特征。
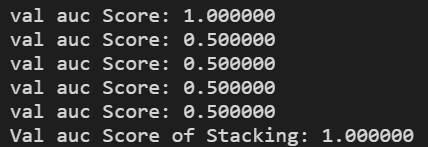
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j]))
clf = LogisticRegression(solver='lbfgs')
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print("Val auc Score of Stacking: %f" % (roc_auc_score(y_predict, y_submission)))
3)分类的Stacking融合(利用mlxtend):
!pip install mlxtend
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(label)
plt.show()
可以发现 基模型 用 ‘KNN’, ‘Random Forest’, ‘Naive Bayes’ 然后再这基础上 次级模型加一个 ‘LogisticRegression’,模型测试效果有着很好的提升。
3 一些其它方法:
将特征放进模型中预测,并将预测结果变换并作为新的特征加入原有特征中再经过模型预测结果 (Stacking变化)
(可以反复预测多次将结果加入最后的特征中)
def Ensemble_add_feature(train,test,target,clfs):
# n_flods = 5
# skf = list(StratifiedKFold(y, n_folds=n_flods))
train_ = np.zeros((train.shape[0],len(clfs*2)))
test_ = np.zeros((test.shape[0],len(clfs*2)))
for j,clf in enumerate(clfs):
'''依次训练各个单模型'''
# print(j, clf)
'''使用第1个部分作为预测,第2部分来训练模型,获得其预测的输出作为第2部分的新特征。'''
# X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(train,target)
y_train = clf.predict(train)
y_test = clf.predict(test)
## 新特征生成
train_[:,j*2] = y_train**2
test_[:,j*2] = y_test**2
train_[:, j+1] = np.exp(y_train)
test_[:, j+1] = np.exp(y_test)
# print("val auc Score: %f" % r2_score(y_predict, dataset_d2[:, j]))
print('Method ',j)
train_ = pd.DataFrame(train_)
test_ = pd.DataFrame(test_)
return train_,test_
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.3)
x_train = pd.DataFrame(x_train) ; x_test = pd.DataFrame(x_test)
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
New_train,New_test = Ensemble_add_feature(x_train,x_test,y_train,clfs)
clf = LogisticRegression()
# clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(New_train, y_train)
y_emb = clf.predict_proba(New_test)[:, 1]
print("Val auc Score of stacking: %f" % (roc_auc_score(y_test, y_emb)))
关于这次赛题的具体代码示例就不再展示了。
嗯…这次数据挖掘零基础入门实验就这样结束了,通过这次结对学习,让我感觉到只有自己是真正的零基础,感谢datawhale的不踢之恩。让我知道了数据挖掘不只是调库,还要理解各种操作背后的原理,不然没有办法正确的使用,甚至没有办法读懂(比如我,从汲取型搬砖->纯搬砖)。
下来可能需要系统的学习一下,还是挺难的(主要是自己没有认真对待,检讨。。。)
再次感谢下组织!
关于Datawhale:
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
