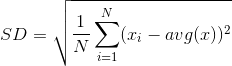1. 模型融合的概念:先产生一组个体学习器,然后利用某种策略将它们结合起来,加强模型效果。周志华和李航老师的书中都证明随着个体学习器数目的增大,集成的错误率将呈指数级下降,最终趋向于零。因此,模型融合被广泛应用。
2. 模型融合的策略:
1.简单加权融合:
回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
分类:投票(Voting)
综合:排序融合(Rank averaging),log融合
2.stacking/blending:
构建多层模型,并利用预测结果再拟合预测。
3.boosting/bagging(在xgboost,Adaboost,GBDT中已经用到):
多树的提升方法
下面介绍回归\分类概率-融合:
1)简单加权平均,模型之间融合
#回归/分类概率-融合
# 1.简单加权平均,结果直接融合
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6]
import numpy as np
import pandas as pd
## 定义结果的加权平均函数
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
from sklearn.metrics import mean_absolute_error as MAE
# 各模型的预测结果计算MAE
print('Pred1 MAE:',MAE(y_test_true, test_pre1))
print('Pred2 MAE:',MAE(y_test_true, test_pre2))
print('Pred3 MAE:',MAE(y_test_true, test_pre3))
Pred1 MAE: 0.1750000000000001
Pred2 MAE: 0.07499999999999993
Pred3 MAE: 0.10000000000000009
## 根据加权计算MAE
w = [0.3,0.4,0.3] # 定义比重权值
Weighted_pre = Weighted_method(test_pre1,test_pre2,test_pre3,w)
print('Weighted_pre MAE:',MAE(y_test_true, Weighted_pre))
Weighted_pre MAE: 0.05750000000000027
可以发现加权结果相对于之前的结果是有提升的,这种我们称其为简单的加权平均。另外,还有一些特殊的形式,比如mean平均,median平均。
2)Stacking融合(回归):
from sklearn import linear_model
def Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,test_pre1,test_pre2,test_pre3,model_L2= linear_model.LinearRegression()):
model_L2.fit(pd.concat([pd.Series(train_reg1),pd.Series(train_reg2),pd.Series(train_reg3)],axis=1).values,y_train_true)
Stacking_result = model_L2.predict(pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).values)
return Stacking_result
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
train_reg1 = [3.2, 8.2, 9.1, 5.2]
train_reg2 = [2.9, 8.1, 9.0, 4.9]
train_reg3 = [3.1, 7.9, 9.2, 5.0]
# y_test_true 代表第模型的真实值
y_train_true = [3, 8, 9, 5]
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6]
model_L2= linear_model.LinearRegression()
Stacking_pre = Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,
test_pre1,test_pre2,test_pre3,model_L2)
print('Stacking_pre MAE:',metrics.mean_absolute_error(y_test_true, Stacking_pre))
Stacking_pre MAE: 0.0421348314607
可以发现模型结果相对于之前有进一步的提升,这是我们需要注意的一点是,对于第二层Stacking的模型不宜选取的过于复杂,这样会导致模型在训练集上过拟合,从而使得在测试集上并不能达到很好的效果。
最后再介绍一下RMSE、MSE、MAE、SD的概念。
- RMSE(root mean square error)均方根误差
衡量观测值与真实值之间的偏差,常用来作为机器学习模型预测结果衡量的标准。
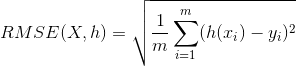
- MSE(mean square error)均方误差
MSE是真实值与预测值的差值的平方和再求平均,通过平方的形式便于求导,所以常被用作线性回归的损失函数。
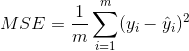
- MAE(mean absolute error)平均绝对误差
是绝对误差的平均值,可以更好地反映预测值误差的实际情况。
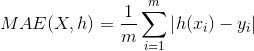
- SD(standard deviation)标准差
方差的算术平均根,用于衡量一组数据的离散程度。