import re
import os
import os.path
from time import sleep
from urllib.parse import urljoin
from urllib.request import urlopen
from multiprocessing import Pool
def crawlUrl(item):
perUrl,name=item
perUrl=urljoin(url,perUrl) #资源网页绝对路径
name=os.path.join(crawlDir,name) #文件本地绝对路径
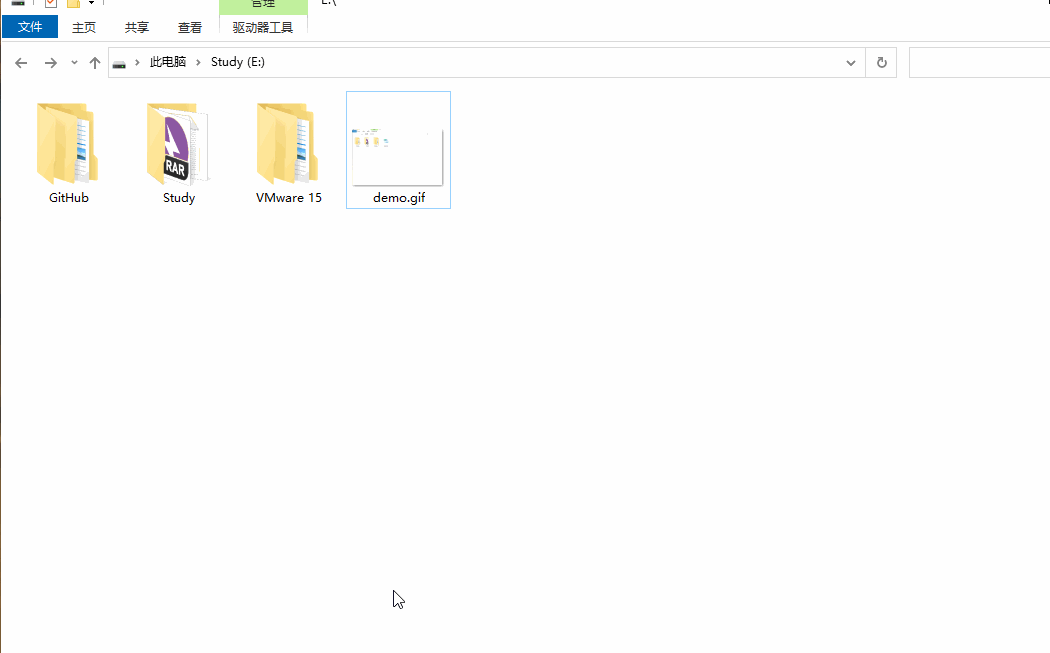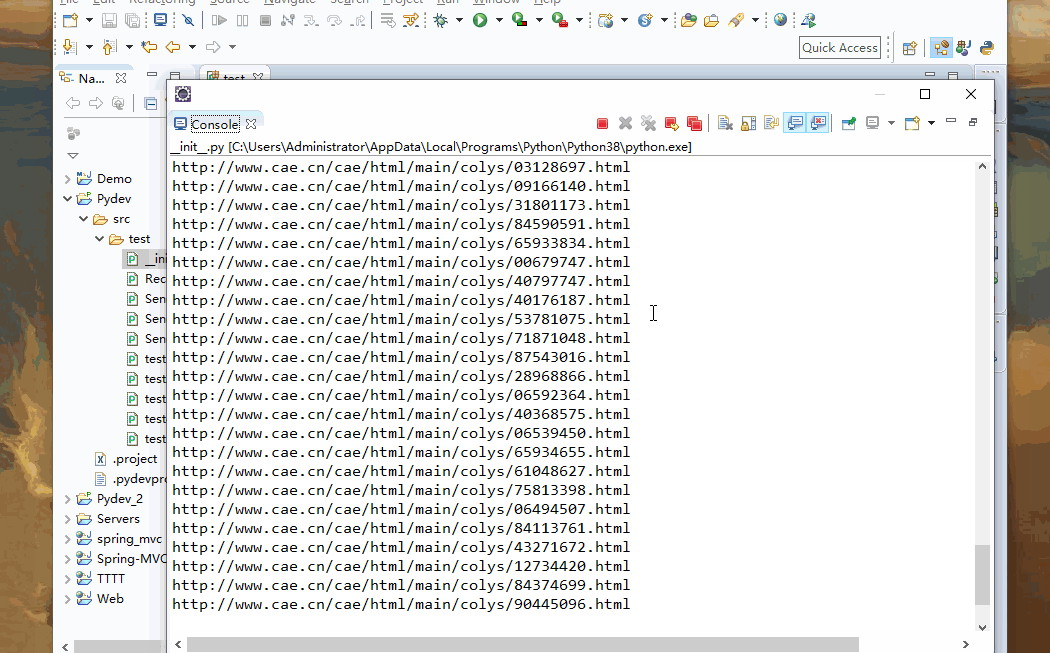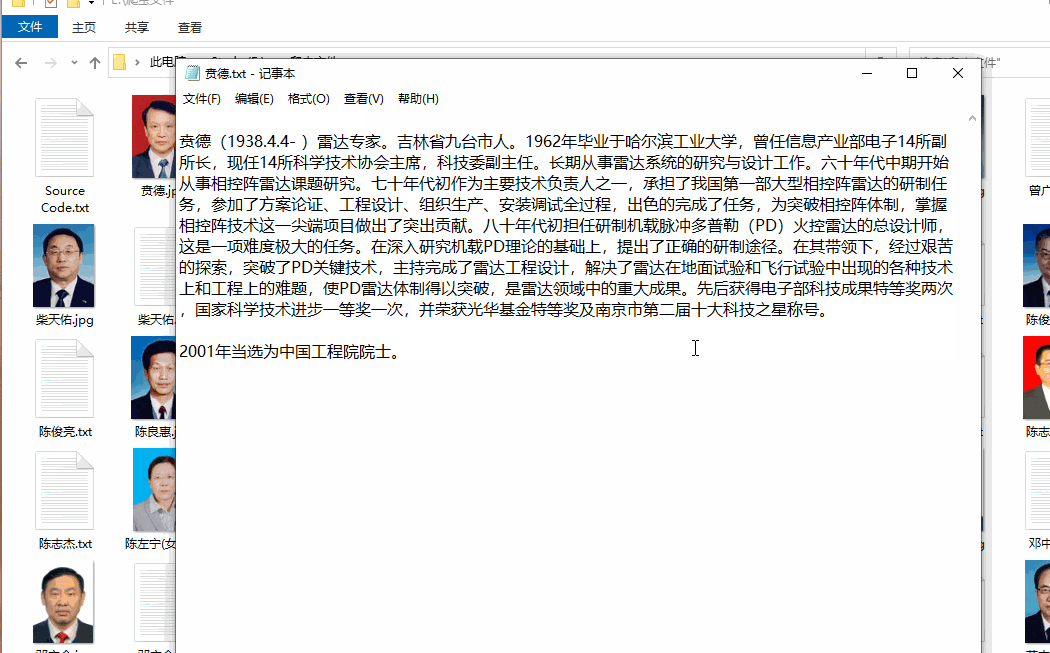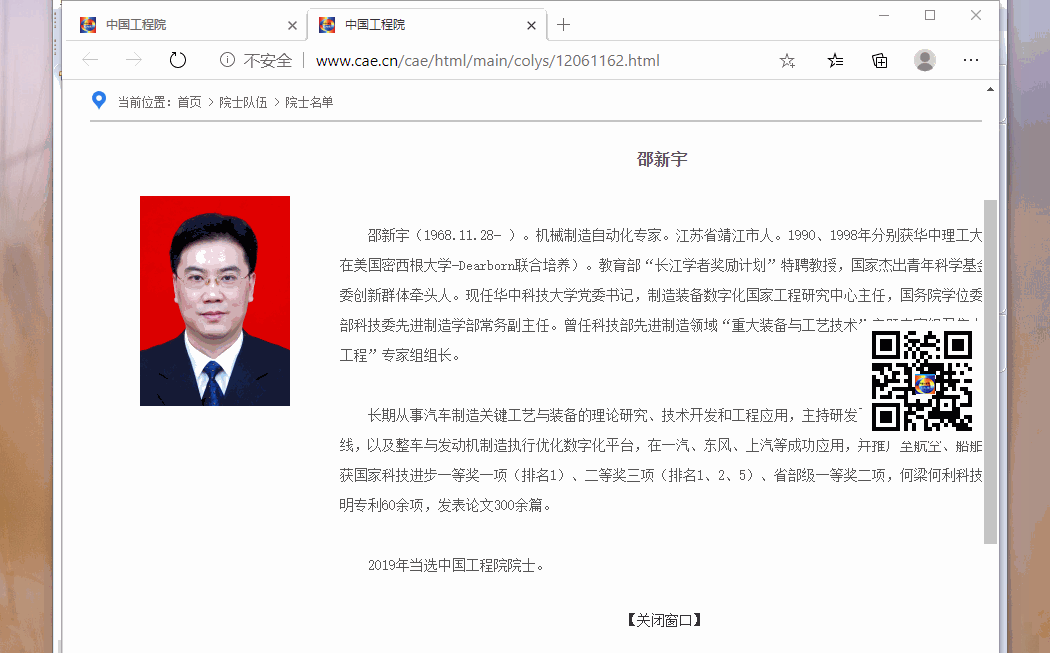
print(perUrl)
try:
with urlopen(perUrl) as fp:
content=fp.read().decode() #获取每条地址的网页源码
except:
print("Crawling {0} Failed,Try again in one seconds ... ".format(perUrl))
sleep(1)
crawlUrl(item)
return
pattern=r'<img src="(.+?)" style=.*?/>' #匹配图片相对路径
imgUrl=re.findall(pattern,content)
if imgUrl:
imgUrl=urljoin(url,imgUrl[0]) #图片绝对路径
try:
with urlopen(imgUrl) as fp1: #写入本地jpg文件
with open(name+".jpg","wb") as fp2:
fp2.write(fp1.read())
except:
pass
pattern=r'<p>(.+?)</p>'
introduction=re.findall(pattern,content) #匹配简介文字
if introduction:
introduction="\n".join(introduction)
introduction=re.sub('( )|( )|(<a href.*?</a>>)',"",introduction) #剔除多余部分
with open(name+".txt","w",encoding="utf8") as fp: #简介写入本地txt文件
fp.write(introduction)
content=str()
crawlDir="E://爬虫文件"
url=r'http://www.cae.cn/cae/html/main/col48/column_48_1.html'
pattern=r'<li class="name_list"><a href="(.+?)" target="_blank">(.+?)</a></li>'
if not os.path.isdir(crawlDir): #创建目录
os.mkdir(crawlDir)
with urlopen(url) as fp: #获取网页源码
content=fp.read().decode()
with open(crawlDir+"/Source Code.txt","w",encoding="utf8") as fp: #下载源码
fp.write(content)
resultArr=re.findall(pattern,content) #匹配资源名
if __name__ == '__main__': #程序被import不执行
with Pool(10) as p: #进程池10个工作进程
p.map(crawlUrl, resultArr) #爬取匹配数组资源
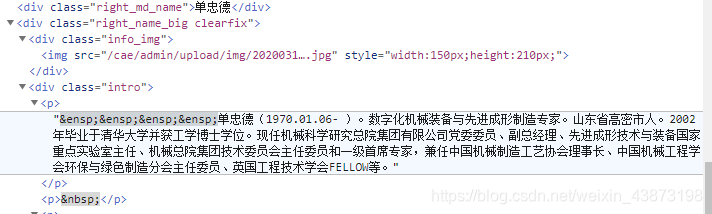
爬虫的关键就在pattern,比如中国工程院的源码中:
<li class="name_list"><a href="/cae/html/main/colys/93671693.html" target="_blank">李焯芬</a></li>
<li class="name_list"><a href="/cae/html/main/colys/83658694.html" target="_blank">林君</a></li>
对应
pattern=r'<li class="name_list"><a href="(.+?)" target="_blank">(.+?)</a></li>'
用re.findall()匹配出的数组类型如下:
[('/cae/html/main/colys/93671693.html', '李焯芬'), ('/cae/html/main/colys/83658694.html', '林君')
再比如
pattern=r'<p>(.+?)</p>'
用
introduction=re.sub('( )|( )|(<a href.*?</a>)',"",introduction)
剔除空格部分和匹配错误部分

这篇博客是学习交流使用,如果图片侵权或其他纠纷请联系本人,一定立刻删除,还请大家不要转载或保存*