文章目录
什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
爬取网页图片实现步骤
第一步:打开所操作的网站(任意一个网站)
第二步:通过python访问这个网站
headers = {
'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
response = requests.get('http://github.com/',headers=headers)
print(response.request.headers)
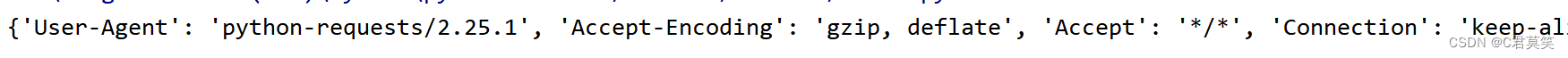
{
'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
第三步:点击F12查询相关信息
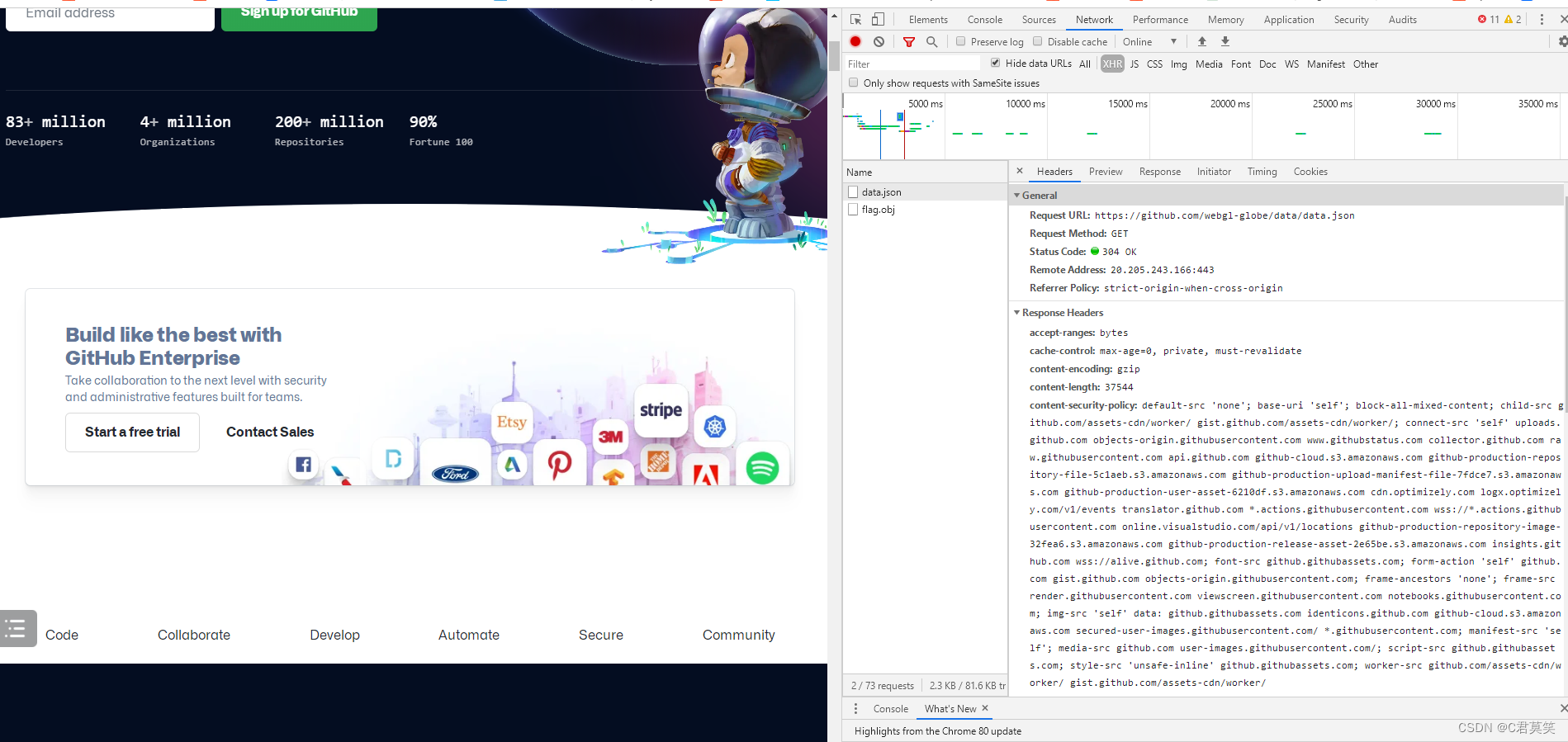
查找到图片信息
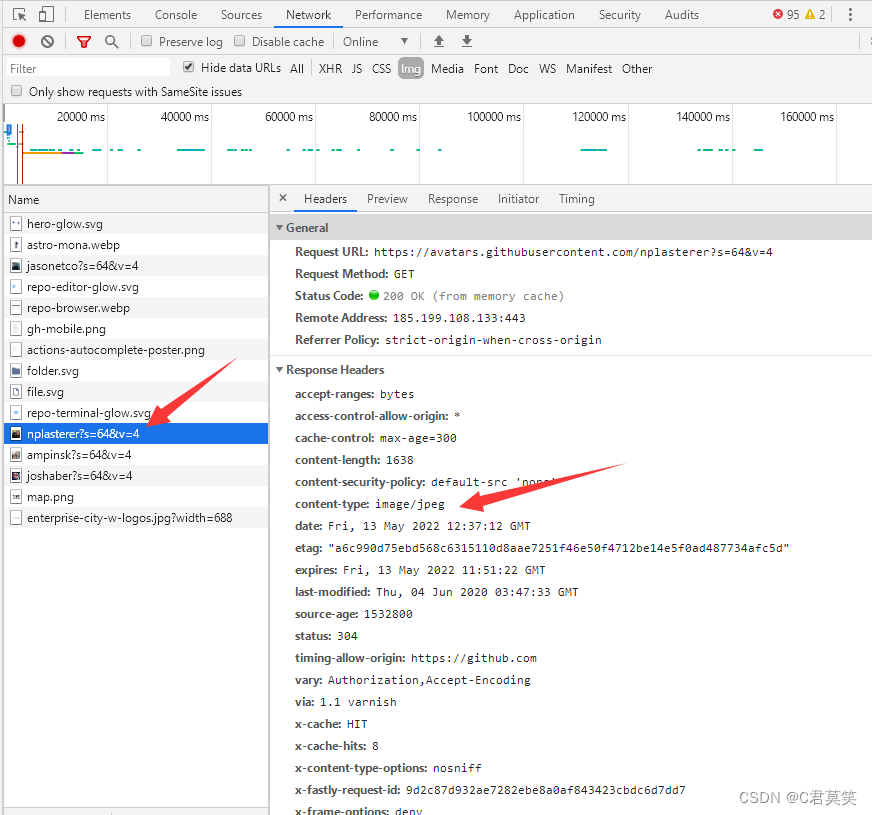
获取headers:
第四步:爬取图片,下载到本地
headers = {
'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
response = requests.get('https://avatars.githubusercontent.com/nplasterer?s=64&v=4',headers=headers)
print(response.request.headers)
with open('icon.ico', 'wb') as f:
f.write(response.content)
print("爬取图片成功")
第五步:显示测试
img = cv2.imread("icon.ico")
cv2.imshow('icon',img)
cv2.waitKey(0)
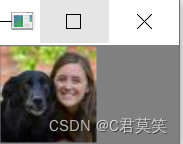
核心代码
import requests
import cv2
headers = {
'User-Agent': 'python-requests/2.25.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
response = requests.get('https://avatars.githubusercontent.com/nplasterer?s=64&v=4',headers=headers)
print(response.request.headers)
with open('icon.ico', 'wb') as f:
f.write(response.content)
print("爬取图片成功")
img = cv2.imread("icon.ico")
cv2.imshow('icon',img)
cv2.waitKey(0)