#####前提:使用的python是python3版本,2和3还是有很大的区别的。
1、先找一个有图片的网页(这里找到的是新浪:http://photo.sina.com.cn)。右键,选择最后一个检查,就可以看到网页的源代码。然后是图片的都是在标签()中。
urllib.request是爬取网页时需要用到的一个库,re是正则匹配的一个库。
具体可以参考一下这篇文章:
https://blog.csdn.net/duxu24/article/details/77414298
import urllib.request,re
f=urllib.request.urlopen("http://photo.sina.com.cn")
source = f.read()
source = source.decode('utf-8')
#先将截取的目标代码取下来
print(re.search(r'(<img src=\")(.*)(\")',source))
可以看到是这样的输出,但是我们的目的是只选取蓝色的部分
改进

import urllib.request,re
f=urllib.request.urlopen("http://photo.sina.com.cn")
source = f.read()
source = source.decode('utf-8')
# print(source)
res = re.search(r'(<img src=\")(.*)(\")',source)
#加入这一部分
print(res.groups()[1])
但是输出结果是这样,说明上面分组的时候最后一个”被当成了最后面的”,所以加个alt即可
http://n.sinaimg.cn/news/transform/700/w1000h500/20180921/ebN_-hiixpup3269628.jpg" alt="2018年喜剧野生动物摄影大赛入围作品" usemap="#Map01
最终
import urllib.request,re
url=urllib.request.urlopen("http://photo.sina.com.cn")
source = url.read()
#将中文字符解码成utf-8的形式
source = source.decode('utf-8')
res = re.search(r'(<img src=\")(.*)(\" alt)',source)
link=res.groups()[1]
link_jpg=urllib.request.urlopen(link)
f=open("test.jpg",'wb')
f.write(link_jpg.read())
f.close()
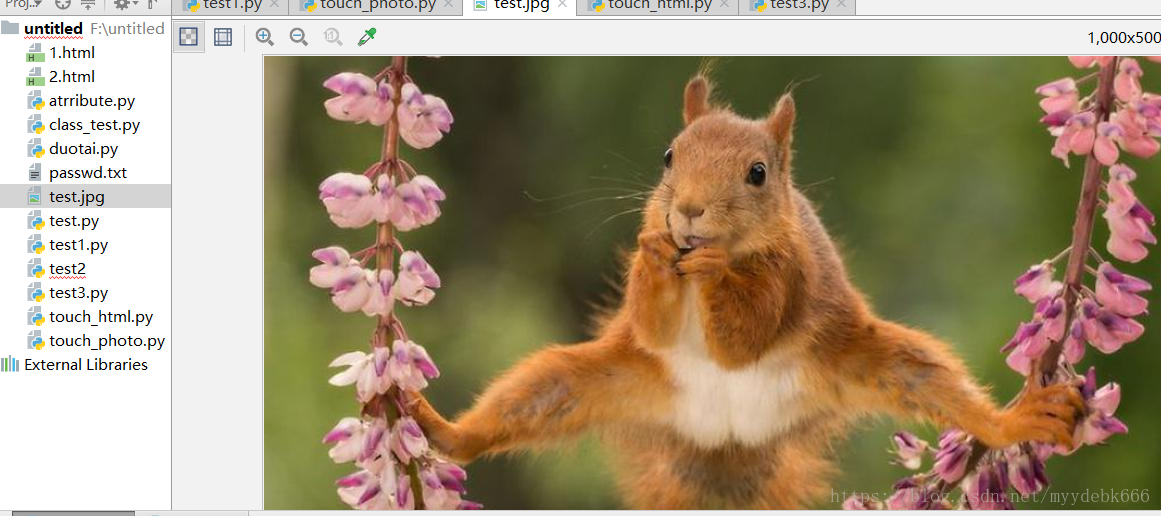
爬取的图片