Contents:
OCR基础原理及应用场景介绍
开源OCR引擎Tesseract介绍及使用示例
基于腾讯云OCR服务开发Web应用
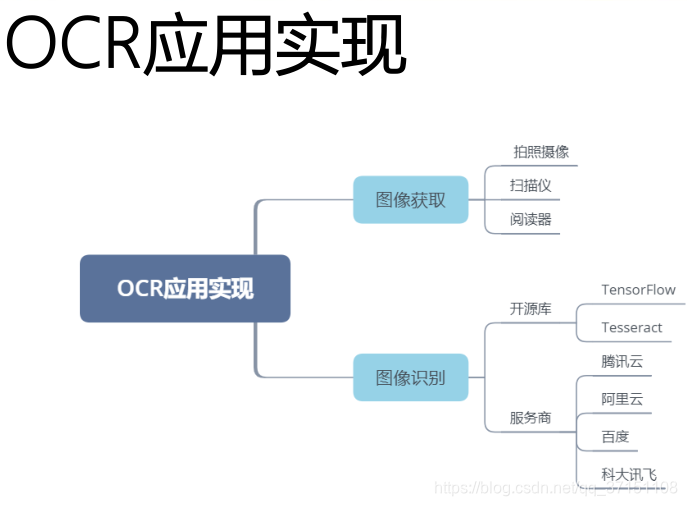
Part I
OCR(OpticalCharacter Recognition)光学字符识别
对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。利用深度学习技术将图片中的文字内容智能的识别出来
传统OCR
基于图像处理和统计模型
场景适应能力差,准确率不高
适用于图片文字单一,质量较高
实现流程:
image->预处理(几何校正、去模糊、图像增强、灰度二值化)->文本检测(版面布局、文本位置、文本范围)->文字识别(特征提取、文本分类、文本后处理)->结果
深度学习OCR
基于深度学习
抗干扰能力强,识别准确率高
适用于各类场景
OCR分类
通用OCR

结构OCR
 OCR应用场景
OCR应用场景
证件识别(身份证、驾驶证、名片、护照等)
办公自动化(发票、火车票、机票报销)
汽车相关(车牌、驾驶证、行驶证、Vin码)
教育(数学算式、公式、试题)