一、如何处理数据集?
from sklearn.dataset import load_iris # 加载鸢尾花数据集
使用scikit-learn时,数据通常用大写的 X 表示,而标签用小写的 y 表示。
scikit-learn的model_selection的 train_test_split 函数可以打乱数据集并进行拆分。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
# 在对数据进行拆分之前,train_test_split 函数利用伪随机数生成器将数据集打乱
# random_state 参数指定了随机数生成器的种子。这样函数输出就是固定不变的
检查数据的最佳方法之一就是将其可视化。一种可视化方法是绘制散点图(scatter plot)。pandas 有一个绘制散点图矩阵的函数scatter_matrix()。矩阵的对角线是每个特征的直方图。
# 利用DataFrame创建散点图矩阵,按y_train着色, 现在函数名为pd.plotting.scatter_matrix()
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={
'bins': 20}, s=60, alpha=.8)
散点图矩阵:

二、如何调用算法?
scikit-learn 中所有的机器学习模型都在各自的类中实现,这些类被称为 Estimator 类。我们需要将这个类实例化为一个对象,然后才能使用这个模型。
例如:k 近邻分类算法是在 neighbors 模块的 KNeighborsClassifier 类中实现的。
from sklearn.neighbors import KNeighborsClassifier # 加载实现KNN算法的类
knn = KNeighborsClassifier(n_neighbors=1) # 创建一个实例对象,并初始化
knn.fit(X_train, y_train)
# 调用knn对象的fit方法,fit方法返回的是knn对象本身并做原处修改,得到了分类器的字符串表示。
y_pred = knn.predict(X_test) # 调用knn对象的predict方法,对验证集进行预测。
score = knn.score(X_test, y_test) # 调用knn对象的score方法,计算测试集的精度
np.mean(y_pred == y_test) # 另外一种计算测试集精度的方法
三、监督学习:分类与回归
监督机器学习问题主要有两种,分别叫作分类(classification)与回归(regression)。
在分类问题中,可能的品种被称为类别(class),已知数据的品种被称为它的标签(label)。
分类任务有时可分为
-
二分类 (binary classification,在两个类别之间进行区分的一种特殊情况)
通常将其中一个类别称为正类(positive class),另一个类别称为反类(negative class)。
-
多分类(multiclass classification,在两个以上的类别之间进行区分)
回归任务的目标是预测一个连续值,编程术语叫作浮点数(floating-point number),数学术语叫作实数(real number)。
区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。
构建一 个对现有信息量来说过于复杂的模型,这被称为过拟合(overfitting)。
选择过于简单的模型 被称为欠拟合(underfitting)。
监督学习算法总览:
| 算法 | 总结 |
|---|---|
| 最近邻 | 适用于小型数据集,是很好的基准模型,很容易解释。 |
| 线性模型 | 非常可靠的首选算法,适用于非常大的数据集,也适用于高维数据。 |
| 朴素贝叶斯 | 只适用于分类问题。比线性模型速度还快,适用于非常大的数据集和高维数据。精度通常要低于线性模型。 |
| 决策树 | 速度很快,不需要数据缩放,可以可视化,很容易解释。 |
| 随机森林 | 几乎总是比单棵决策树的表现要好,鲁棒性很好,非常强大。不需要数据缩放。不适用于高维稀疏数据。 |
| 梯度提升决策树 | 精度通常比随机森林略高。与随机森林相比,训练速度更慢,但预测速度更快,需要的内存也更少。比随机森林需要更多的参数调节。 |
| 支持向量机 | 对于特征含义相似的中等大小的数据集很强大。需要数据缩放,对参数敏感。 |
| 神经网络 | 可以构建非常复杂的模型,特别是对于大型数据集而言。对数据缩放敏感,对参数选取。 |
四、主要算法
4.1 使用到的数据集
from sklearn.datasets import load_breast_cancer # 威斯康星州乳腺癌数据集(用于分类数据集)
from sklearn.datasets import load_boston # 波士顿房价数据集(用于回归数据集)
4.2 k近邻
k-NN 算法可以说是最简单的机器学习算法。
from sklearn.neighbors import KNeighborsClassifier # 用于分类的k近邻训练器
clf = KNeighborsClassifier(n_neighbors = 3)
from sklearn.neighbors import KNeighborsRegressor # 用于回归的k近邻训练器
reg = KNeighborsRegressor(n_neighbors=3)
- k近邻算法用于分类
# 进行数据集的导入和拆分
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=66)
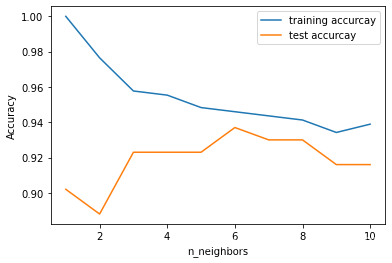
# 使用k近邻分类器训练邻居个数为1-10的模型,并计算准确率accuracy
from sklearn.neighbors import KNeighborsClassifier
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors = n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train))
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="training accurcay")
plt.plot(neighbors_settings, test_accuracy, label="test accurcay")
plt.xlabel("n_neighbors")
plt.ylabel("Accuracy")
plt.legend()
准确率:
- k近邻算法用于回归
利用单一邻居的预测结果就是最近邻的目标值。在使用多个近邻时,预测结果为这些邻居的平均值。具体代码同分类一致。
对于回归问题,评估模型的score方法返回的是 R2 分数。R2 分数也叫作决定系数,是回归模型预测的优度度量,位于 0 到 1 之间。R2 等于 1 对应完美预测,R2 等于 0 对应常数模型。
- 总结
(1)参数:邻居个数和数据点之间距离的度量方法
(2)优点:容易理解,不需过多调节就可以得到不错性能,是一种很好的基准方法。
(3)缺点:预测速度慢,不适用于特征很多的训练集,对稀疏数据集效果尤其不好。
4.3 线性模型
线性模型利用输入特征的线性函数(linear function)进行预测。
from sklearn.linear_model import LinearRegression # 线性回归的训练器
lr = LinearRegression()
from sklearn.linear_model import Ridge # 岭回归的训练器
ridge = Ridge(alpha=1)
# alpha参数指定简单性和训练集性能二者对于模型的重要程度,alpha 的最佳设定值取决于具体数据集。
# 一般来说,alpha值越小模型越复杂,正则化越弱。
from sklearn.linear_model import Lasso # Lasso回归的训练器
ridge = Ridge(alpha=0.01, max_iter=100000)
from sklearn.linear_model import LogisticRegression # Logistic回归的分类器
logreg = LogisticRegression(C=1, penalty="l2")
# 参数C决定正则化强度的权衡参数,越大对应的正则化越弱;参数penalty决定选取正则化项类别
from sklearn.svm import LinearSVC # 线性SVM的分类器,SVC代表支持向量分类器
线性模型算法的区别:
- 系数和截距的特定组合对训练数据拟合好坏的度量方法;
- 是否使用正则化,以及使用哪种正则化方法。
- 用于回归的线性模型
对于用于回归的线性模型,输出 ŷ 是特征的线性函数,是直线、平面或超平面(对于更高维的数据集)。对单一特征的预测结果是一条直线,两个特征时是一个平面,或者在更高维度(即更多特征)时是一个超平面。
如果特征数量大于训练数据点的数量,任何目标 y 都可以(在训练集上)用线性函数完美拟合 。
(我认为可以理解为训练集中的点都在回归曲线上!)
- 线性回归(又名普通最小二乘法(ordinary least squares,OLS))
线性回归,或者普通最小二乘法,是回归问题最简单也最经典的线性方法。
线性回归寻找参数 w 和 b,使得对训练集的预测值与真实的回归目标值 y之间的均方误差最小。
均方误差(mean squared error)是预测值与真实值之差的平方和除以样本数。
# 线性回归过程
from sklearn.linear_model import LinearRegression
X, y = mglearn.datasets.make_wave(n_samples =60)
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=42)
lr = LinearRegression().fit(X_train, y_train) # 创建线性回归分类器实例对象并训练
lr.coef_ # 该属性保存w,即权重或者系数
lr.intercept_ # 该属性保存b,即偏移或截距
lr.score(X_train, y_train) # 计算训练集性能
lr.score(X_test, y_test) # 计算测试集性能
参数 w,被保存在 coef_ 属性中,它是一个NumPy 数组,每个元素对应一个输入特征。
参数 b,被保存在 intercept_ 属性中,它是一个浮点数。
scikit-learn总是将从训练数据中得出的值保存在以下划线结尾的属性中。这是为了将其与用户设置的参数区分开。
- 岭回归
在岭回归中,对系数(w)的选择不仅要在训练数据上得到好的预测结果,而且还要拟合附加约束。我们还希望系数尽量小。换句话说,w 的所有元素都应接近于 0。
岭回归这种约束是谓正则化(regularization)的一个例子。正则化是指对模型做显式约束,以避免过拟合。岭回归用到的这种被称为 L2 正则化。
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1)
岭回归和线性回归性能比较:
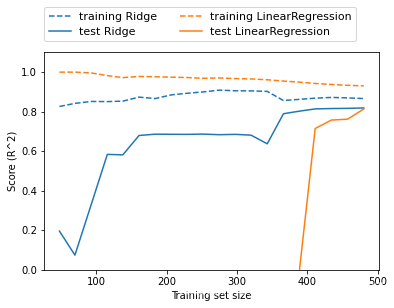
如果有足够多的训练数据,正则化变得不那么重要,并且岭回归和线性回归将具有相同的性能。
- lasso
lasso使用L1正则化。 L1 正则化的结果是,使用 lasso 时某些系数刚好为 0。这说明某些特征被模型完全忽略。这可以看作是一种自动化的特征选择。
from sklearn.linear_model import Lasso
ridge = Ridge(alpha=0.01, max_iter=100000)
岭回归和lasso回归的选用:
在实践中,在两个模型中一般首选岭回归。但如果特征很多,你认为只有其中几个是重要的,那么选择 Lasso 可能更好。同样,如果你想要一个容易解释的模型,Lasso 可以给出更容易理解的模型,因为它只选择了一部分输入特征。
scikit-learn 还提供了 ElasticNet类,结合了 Lasso 和 Ridge 的惩罚项。在实践中,这种结合的效果最好,不过代价是要调节两个参数:一个用于 L1 正则化,一个用于 L2 正则化。
- 用于分类的线性模型
- 用于二分类的线性模型
对于用于分类的线性模型,决策边界是输入的线性函数。换句话说,(二元)线性分类器是利用直线、平面或超平面来分开两个类别的分类器。
最常见的两种线性分类算法是 Logistic 回归(logistic regression)和线性支持向量机(linear support vector machine,线性 SVM)。
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
两个模型都默认使用 L2 正则化,决定正则化强度的权衡参数叫作 C。C 值越大,对应的正则化越弱。较小的 C 值可以让算法尽量适应“大多数”数据点,而较大的 C 值更强调每个数据点都分类正确的重要性。
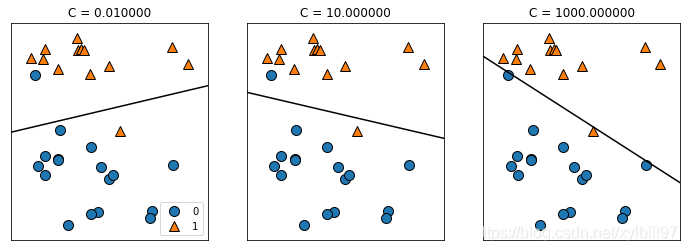
- 用于多分类的线性模型
将二分类算法推广到多分类算法的一种常见方法是“一对其余”(one-vs.-rest)方法。在测试点上运行所有二类分类器来进行预测。在对应类别上分数最高的分类器“胜出”,将这个类别标签返回作为预测结果。
- 总结
(1)线性模型的主要参数是正则化参数,在回归模型中叫作 alpha,在 LinearSVC 和LogisticRegression 中叫作 C。alpha 值较大或 C 值较小,说明模型比较简单。
(2)线性模型的训练速度非常快,预测速度也很快。这种模型可以推广到非常大的数据集,对稀疏数据也很有效。solver=‘sag’ 选项,在处理大型数据时,这一选项比默认值要更快。
(3)推广版本:SGDClassifier 类和 SGDRegressor 类
4.4 朴素贝叶斯分类器
朴素贝叶斯分类器与线性模型相比,训练速度更快,泛化能力稍差。
scikit-learn 中实现了三种朴素贝叶斯分类器:
| 名称 | 使用范围 |
|---|---|
| GaussianNB | 可应用于任意连续数据,会保存每个类别中每个特征的平均值和标准差。 |
| BernoulliNB | 假定输入数据为二分类数据,计算每个类别中每个特征不为 0 的元素个数。 |
| MultinomialNB | 假定输入数据为计数数据,计算每个类别中每个特征的平均值。 |
这三个分类器都只有一个参数alpha,alpha 的工作原理是,算法向数据中添加 alpha 这么多的虚拟数据点,这些点对所有特征都取正值。这可以将统计数据“平滑化”(smoothing)。alpha 越大,平滑化越强,模型复杂度就越低。
- 总结
朴素贝叶斯模型的训练和预测速度都很快,训练过程也很容易理解。
该模型对高维稀疏数据的效果很好,对参数的鲁棒性也相对较好。
朴素贝叶斯模型是很好的基准模型,常用于非常大的数据集。