前言
受到近年来对隐私数据的安全性重视,各国颁布的相关的法律法规维护个人数据的安全性以及隐私性,企业与企业之间,甚至于部门与部门之间形成数据孤岛的现象,一定程度地降低社会效率,在以上各种因素的影响下,联邦学习应运而生,尤其是在2020年年初,国内乘着AI基础设施算法组件在社会各业纷纷落地的契机,联邦学习框架也伴随着进入了我们的视线。
接下主要对国内的联邦学习框架从各个方向进行研究,为后面应用落地提供技术方案选择。
微众银行FATE
FATE (Federated AI Technology Enabler) 是微众银行AI部门发起的开源项目,为联邦学习生态系统提供了可靠的安全计算框架。FATE项目使用多方安全计算 (MPC) 以及同态加密 (HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。
开源地址:https://github.com/FederatedAI/
算法支持
FATE目前支持三种类型联邦学习算法:横向联邦学习、纵向联邦学习以及迁移学习。
Federatedml模块包括许多常见机器学习算法联邦化实现。所有模块均采用去耦的模块化方法开发,以增强模块的可扩展性。具体来说,主要提供:
-
联邦统计: 包括隐私交集计算,并集计算,皮尔逊系数等。
-
联邦特征工程:包括联邦采样,联邦特征分箱,联邦特征选择等。
-
联邦机器学习算法:包括横向和纵向的联邦LR, GBDT, DNN,迁移学习等。
-
模型评估:提供对二分类,多分类,回归评估,联邦和单边对比评估。
-
安全协议:提供了多种安全协议,以进行更安全的多方交互计算。
详细算法清单: https://github.com/FederatedAI/DOC-CHN/tree/master/Federatedml
Fate整体架构
Fate主要分成以FateFlow以及FederatedML为主体的离线训练平台,以及以FateServing为主体的在线预测平台。
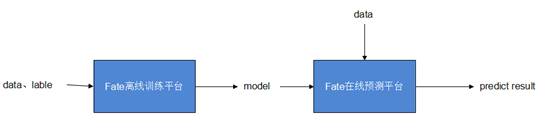
离线训练平台
架构
其中离线平台的整体架构如下:
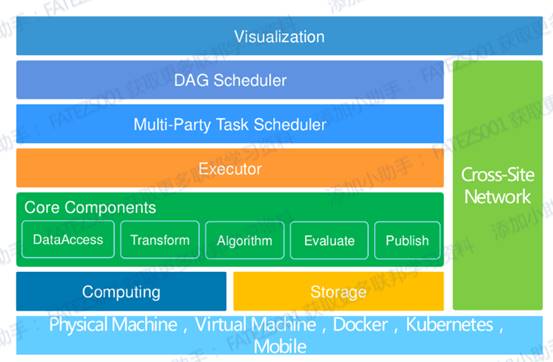
离线训练平台的架构通过上图来看已经很明晰了,主要分成基础设施层、计算存储层、核心组件层、任务执行层、任务调度层、可视化面板层以及跨网络交互层。
-
在基础设施层的话,Fate主要支持Docker形式的部署,虽然也支持二进制,但是用Docker还是能降低物理环境的差异性,便于落地,而且Fate友好地提供KubeFATE模式,如果是开发或者测试场景, 推荐使用docker-compose部署方式. 这种模式仅仅需要 Docker 环境。 如果生产环境或者大规模部署, 推荐使用Kubernetes方式来管理FATE系统。
-
在计算存储层,主要以EggRoll以及Spark作为分布式计算引擎,据我了解Spark应该是v1.4版本的新特性之一,而EggRoll跟Spark的比较下,Spark是相对成熟而且资料比较多,Spark跟EggRoll的主要差别就是Spark的存储使用HDFS,EggRoll是把存储和计算绑定在一起的,就是不传输数据,而是把计算逻辑传输到数据所在的地方去执行。由于计算逻辑较小,所以不需要进行大规模的数据移动。
-
核心组件层主要提供数据权限、数据交互、算法相关、模型训练评估发布相关的实现。
-
上面的任务执行层以及调度层,主要是FateFlow这个模块去实现这部分功能,笼统的说明就是联邦学习建模Pipeline 调度和生命周期管理工具,为用户构建端到端的联邦学习pipeline生产服务。实现了pipeline的状态管理及运行的协同调度,同时自动追踪任务中产生的数据、模型、指标、日志等便于建模人员分析。
使用流程
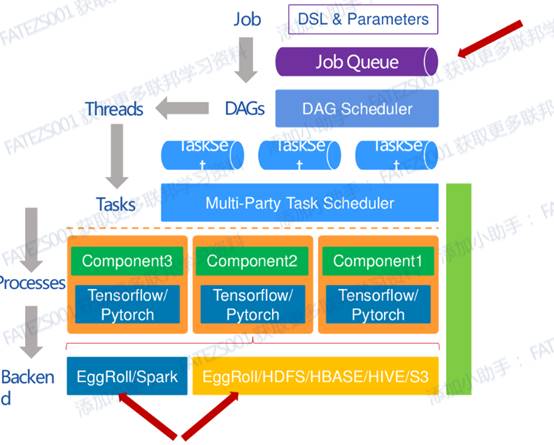
开发者通过编写DSL构建自己模型训练的pipeline,提交Job到任务队列,然后任务调度器从队列拉取任务,调度不同的计算节点执行pipeline。
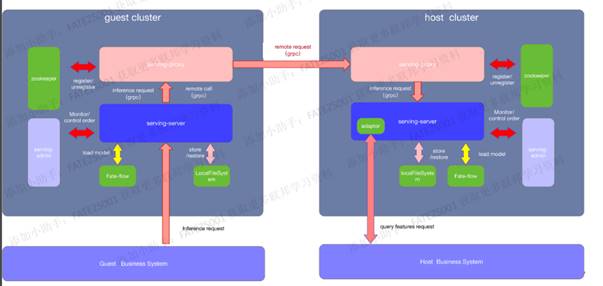
部署架构
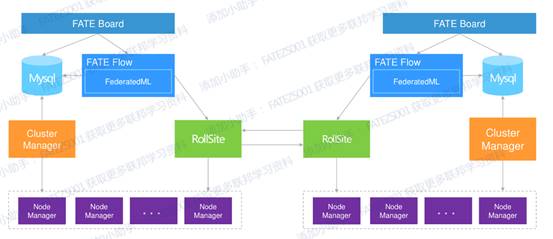
下面是v1.4的多节点部署架构图,可以看到对于多节点(主要是guest跟host两种角色)的部署组件主要有:
| 软件产品 | 组件 | 说明 |
|---|---|---|
| fate | fate_flow | 联合学习任务流水线管理模块,每个party只能有一个此服务 |
| fate | fateboard | 联合学习过程可视化模块,每个party只能有一个此服务 |
| eggroll | clustermanager | cluster manager管理集群,每个party只能有一个此服务 |
| eggroll | nodemanager | node manager管理每台机器资源,每个party可有多个此服务,但一台服务器置只能有一个 |
| eggroll | rollsite | 跨站点或者说跨party通讯组件,相当于proxy+federation,每个party只能有一个此服务 |
| mysql | mysql | 数据存储,clustermanager和fateflow依赖,每个party只需要一个此服务 |
在线预测平台
架构
在线预测平台主要通过加载离线训练平台训练模型实现在线预测功能。
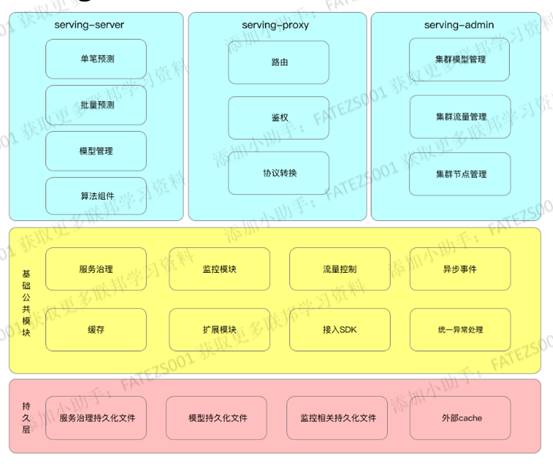
在线预测平台主要由以下三个组件构成:
-
Serving-server:预测功能的核心模块,提供算法组件,实现基于模型的预测功能。
-
Serving-proxy:在多方交互的时候提供路由功能,协议转换你功能,一般guest与host之间都是通过Serving-proxy进行通信。
-
Serving-admin:提供集群管理功能,实现可视化管理。
具体架构如下:
使用流程

-
打包部署:从Fate仓库下载Fate-Serving的相关模块编译打包运行在本地,目前主要基于java开发,需要java环境。
-
推送模型:从Fate-Flow里面获取模型,加载到Fate-Serving。
-
模型初始化:Fate-Serving将模型load到本地并初始化到内存。
-
注册模型接口:Serving-Server将模型的信息转换成接口信息注册到注册中心,主要基于GRPC协议。
-
提供服务:调用方从注册中心拉取该模型的接口地址并发起调用。
部署架构
效率分析
以下材料来自于:https://blog.csdn.net/hellompc/article/details/105705745
LR算法测试
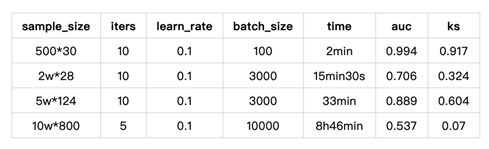
FATE在训练10W*800样本时(做过归一化后)发现loss值虽在小范围内波动,但最终结果亦没有达到收敛。
树类算法测试
[外链图片转存失败,源站可能有防盗img]!链机制,建(https://img-WIQlog.csdnimg.cn/img_convert/213faedbc259861c614b34106a6265cc.png#pic_centerhtps://img-log.csdnimg.cn/img_convert/23d13faedbc259861c14b3646a6264cc.png)]
相关界面
任务总体概况:
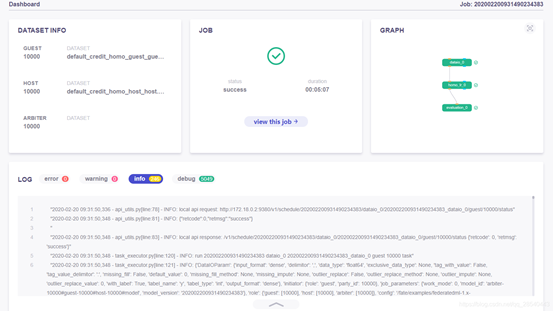
任务详细信息:
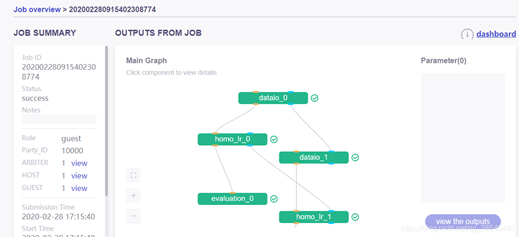
任务步骤输出模型/数据查看:

模型训练结果查看:
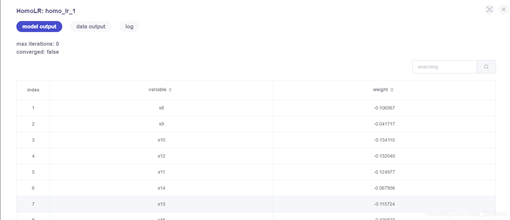
具体操作
参考:https://blog.csdn.net/qq_28540443/article/details/104562797
富数FMPC
富数多方安全计算平台(FMPC )是上海富数科技旗下产品,目前未开源,主要通过体验或者服务购买方式使用。
产品官网地址:https://www.fudata.cn/
富数科技是安全计算的领跑者。公司立足于领先的安全计算与人工智能技术,帮助合规数据源搭建大数据安全建模的桥梁,落地金融、政务、医疗、营销等业务场景,释放大数据的商业价值;聚合海量数据源和应用场景,形成安全的数据价值流通平台。通过连接、交互、结网, 建设安全的数据互联网生态。
相较于上面提到的Fate,FMPC是一匹黑马,下面简单说明一下他的四大产品模块:
1)联邦学习FMPC:
原始数据不出门,参与各方本地建模;没有敏感数据流通,交互中间计算结果;参与方只有自己模型参数,
整个模型被保护;私有化部署;开放API快速开发;支持主流机器学习算法;LR, DT, RF, Xgboost…;建模速度快3倍;密文训练精度误差<1%
2)多方安全计算:
落地应用计算量1.1万+次/天;支持多方数据安全求交;支持一次多项式;支持多方归因统计分析;支持多方多维数据钻取分析;私有化部署
3)匿踪查询:
支持100亿+条记录;秒级响应时间;查询授权存证;甲方查询信息不泄露;加密隧道避免中间留存;私有化部署。
4)联盟区块链:
联盟节点30+;高性能扩展1万TPS;合约调用20万次/天;电子存证和智能合约;隐私保护协议;快捷部署场景应用;开源开发社区。
访问地址:https://www.unitedata.link/
经过查看,目前开放的链是有故障状态。
下面材料主要参考于:https://blog.csdn.net/hellompc/article/details/104822723
整体架构
FMPC目前公开的技术架构如下:

技术原理:
在确定共有用户群体后,就可以利用这些数据训练机器学习模型。以线性回归模型为例,训练过程可分为以下 5 步:
第①步:A和B把各自公钥分发给对方,用以对训练过程中需要交换的数据进行加密;
第②步:A和B分别进行本地的训练,产生不含敏感信息的中间结果。
第③步:A和B之间以加密形式交互用于计算梯度的中间结果;
第④步:A和B分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并汇总计算总梯度;
第⑤步:A和B根据新计算的梯度更新各自模型的参数。

使用流程
虽然目前需要申请体验才能看到相关的使用流程,但根据目前网上查到的相关资料,主要分成以下几个步骤:

部署架构
未公开
算法支持
未公开
效率分析
为了模拟真实业务场景,本次测试准备了如下两份样本:
样本A:两万行数据,1列索引列字段,26个特征字段
样本B:两万行数据,1列索引列字段,1列目标值字典,2个特征字段
在同等环境下同时部署FATE1.2/FMPC两套产品,每次运行任务只独立运行其中一款,得到指标如下:

结果分析
根据以上两款产品使用流程可以看出,两款产品均实现并完成安全建模的闭环流程,但在某些方面还存在一定差异。
1)产品角度:FATE更偏向于面向技术人员,使用者需要具有一定开发能力及算法功底;FMPC更偏向于面向业务人员,使之能在清晰的界面可视化操作。
2)功能健全程度:FATE具有基本建模功能,包括数据上传,模型训练,模型评估,模型预测;FMPC在此基础上添加了特征分析及特征筛选功能,更贴近实际业务场景需求。
3)性能角度:FATE的secureBoost较lr相比训练速度更快,模型精度更高,运行时间在业内属于可接受范围;FMPC与之相比,开创性地采用“松弛迭代法“,在保持精度和准确性的同时,速度提升了3倍左右,在实际业务的多次的迭代和调参中会有较明显的优势。
相关界面
数据集上传:FMPC上传文件有四种方式,分别为本地csv、url、DB数据库、接口方式,以csv文件为例,通过页面点选欲上传的本地文件路径,并填入文件相关信息,配置权限:

数据虚拟融合(利用不经意传输机制进行的加密数据对齐):

数据分析及特征筛选:

建模管理:

预测接口调用:

百度PaddleFL
PaddleFL是一个基于PaddlePaddle的开源联邦学习框架。研究人员可以很轻松地用PaddleFL复制和比较不同的联邦学习算法。开发人员也可以从paddleFL中获益,因为用PaddleFL在大规模分布式集群中部署联邦学习系统很容易。PaddleFL提供很多联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,PaddleFL还将提供传统机器学习训练策略的应用,例如多任务学习、联邦学习环境下的迁移学习。依靠着PaddlePaddle的大规模分布式训练和Kubernetes对训练任务的弹性调度能力,PaddleFL可以基于全栈开源软件轻松地部署。
开源地址:https://github.com/PaddlePaddle/PaddleFL
笔者对PaddlePaddle这个深度学习框架也是挺熟悉的,也使用过一二,从易用性以及算法效率来看,都不逊色,尤其背靠百度的信息库,PaddlePaddle提供的预训练模型的准确率也很高,基本可以开箱即用。
整体架构

PaddleFL算法支持:
A. 联邦学习策略
纵向联邦学习: 带privc的逻辑回归,带ABY3的神经网络
横向联邦学习: 联邦平均 ,差分隐私,安全聚合
B. 训练策略
多任务学习
迁移学习
主动学习
PaddleFL 中主要提供两种解决方案:Data Parallel 以及 Federated Learning with MPC (PFM)。
通过Data Parallel,各数据方可以基于经典的横向联邦学习策略(如 FedAvg,DPSGD等)完成模型训练。
此外,PFM是基于多方安全计算(MPC)实现的联邦学习方案。作为PaddleFL的一个重要组成部分,PFM可以很好地支持联邦学习,包括横向、纵向及联邦迁移学习等多个场景。既提供了可靠的安全性,也拥有可观的性能。
使用流程
Paddle FL MPC 中的安全训练和推理任务是基于高效的多方计算协议实现的,如ABY3

在ABY3中,参与方可分为:输入方、计算方和结果方。输入方为训练数据及模型的持有方,负责加密数据和模型,并将其发送到计算方。计算方为训练的执行方,基于特定的多方安全计算协议完成训练任务。计算方只能得到加密后的数据 及模型,以保证数据隐私。计算结束后,结果方会拿到计算结果并恢复出明文数据。每个参与方可充当多个角色,如一个数据拥有方也可以作为计算方参与训练。
PFM的整个训练及推理过程主要由三个部分组成:数据准备,训练/推理,结果解析。
A. 数据准备
私有数据对齐: PFM允许数据拥有方(数据方)在不泄露自己数据的情况下,找出多方共有的样本集合。此功能在纵向联邦学习中非常必要,因为其要求多个数据方在训练前进行数据对齐,并且保护用户的数据隐私。
数据加密及分发:在PFM中,数据方将数据和模型用秘密共享[10]的方法加密,然后用直接传输或者数据库存储的方式传到计算方。每个计算方只会拿到数据的一部分,因此计算方无法还原真实数据。
B. 训练/推理
PFM 拥有与PaddlePaddle相同的运行模式。在训练前,用户需要定义MPC协议,训练模型以及训练策略。paddle_fl.mpc中提供了可以操作加密数据的算子,在运行时算子的实例会被创建并被执行器依次运行。
C. 结果重构
安全训练和推理工作完成后,模型(或预测结果)将由计算方以加密形式输出。结果方可以收集加密的结果,使用PFM中的工具对其进行解密,并将明文结果传递给用户。
部署架构
Paddle FL的部署基于docker或者k8s
整体部署架构如下:

在PaddeFL中,用于定义联邦学习任务和联邦学习训练工作的组件如下:
A. 编译时
FL-Strategy: 用户可以使用FL-Strategy定义联邦学习策略,例如Fed-Avg。
User-Defined-Program: PaddlePaddle的程序定义了机器学习模型结构和训练策略,如多任务学习。
Distributed-Config: 在联邦学习中,系统会部署在分布式环境中。分布式训练配置定义分布式训练节点信息。
FL-Job-Generator: 给定FL-Strategy, User-Defined Program 和 Distributed Training Config,联邦参数的Server端和Worker端的FL-Job将通过FL Job Generator生成。FL-Jobs 被发送到组织和联邦参数服务器以进行联合训练。
B. 运行时
FL-Server: 在云或第三方集群中运行的联邦参数服务器。
FL-Worker: 参与联合学习的每个组织都将有一个或多个与联合参数服务器通信的Worker。
FL-Scheduler: 训练过程中起到调度Worker的作用,在每个更新周期前,决定哪些Worker可以参与训练。
算法支持
纵向联邦学习: 带privc的逻辑回归,带ABY3的神经网络
横向联邦学习: 联邦平均 ,差分隐私,安全聚合
效率分析
数据集:
https://paddle-zwh.bj.bcebos.com/gru4rec_paddlefl_benchmark/gru4rec_benchmark.tar
| Dataset | training methods | FL Strategy | recall@20 |
|---|---|---|---|
| the whole dataset | private training | 0.504 | |
| the whole dataset | federated learning | FedAvg | 0.504 |
| 1/4 of the whole dataset | private training | 0.286 | |
| 1/4 of the whole dataset | private training | 0.277 | |
| 1/4 of the whole dataset | private training | 0.269 | |
| 1/4 of the whole dataset | private training | 0.282 |
相关界面
无提供界面
京东九数联邦学习9NFL
基于业务需要,京东自研的联邦学习平台:九数联邦学习平台(9NFL)于2020年初正式上线。九数联邦学习平台(9NFL)基于京东商业提升事业部9N机器学习平台进行开发,在9N平台离线训练,离线预估,线上inference、模型的发版等功能的基础上,增加了多任务跨域调度、跨域高性能网络、大规模样本匹配、大规模跨域联合训练、模型分层级加密等功能。整个平台可以支持百亿级/百T级超大规模的样本匹配、联合训练,并且针对跨域与跨公网的复杂环境,对可用性与容灾设计了一系列的机制与策略,保障整个系统的高吞吐、高可用、高性能。
开源地址:https://github.com/jd-9n/9nfl
整体架构
整个系统分为四个大模块:
-
整体调度与转发模块
整体控制数据求交与训练的调度 训练器的配对工作 高效的流量转发 -
资源管理与调度模块
使用k8s屏蔽底层资源差异 使用k8s进行资源的动态调度 -
数据求交模块
大规模多模态跨域数据整合 异步分布式框架提升拼接效率 -
训练器模块
分布式框架训练支持,提升系统的吞吐性能 异常恢复、failover机制 高效的网络传输协议设计

使用流程
9NFL主要的使用流程为:
1.数据准备
2.数据求交
3.模型训练
部署架构
目前根据开源的程度,9NFL并未完全开源,从文档来看也是基于Docker模式的部署。
算法支持
主要基于tensorflow。
效率分析
暂无
相关界面
无界面
总结
按照框架的成熟度来说,目前开源的框架里面Fate是相对较为成熟的,而且在算法以及架构方向不断优化,开源社区成熟。而FMPC就目前研究来说,他较之Fate在业务操作易用性上面领先一个身位,Fate、PaddleFL、9NFL目前操作界面都是没有的,虽然Fate有完善的监控界面,因此FMPC对于业务场景落地还是稍有优势。现在联邦学习正在不断发展,虽然目前落地的案例并不多,但是相信在不久的将来,在各方的共同学习努力下,必能共同进步,推动联邦学习真正落地,保障个人数据隐私,解决数据孤岛问题。
参考资料
https://github.com/FederatedAI/
https://blog.csdn.net/hellompc/article/details/105705745
https://blog.csdn.net/qq_28540443/article/details/104562797
https://blog.csdn.net/hellompc/article/details/104822723