网页:http://dict.cnki.net/dict_result.aspx
需要用到的库:
import requests
from lxml import etree
import time
import re
from requests.adapters import HTTPAdapter
- 第一部首先获取网页源代码。可以看到数据是放在网页源代码的,并不是通过放在
json文件中异步记载的。那么我们直接找到放有源代码的报文中构造我们的请求头:
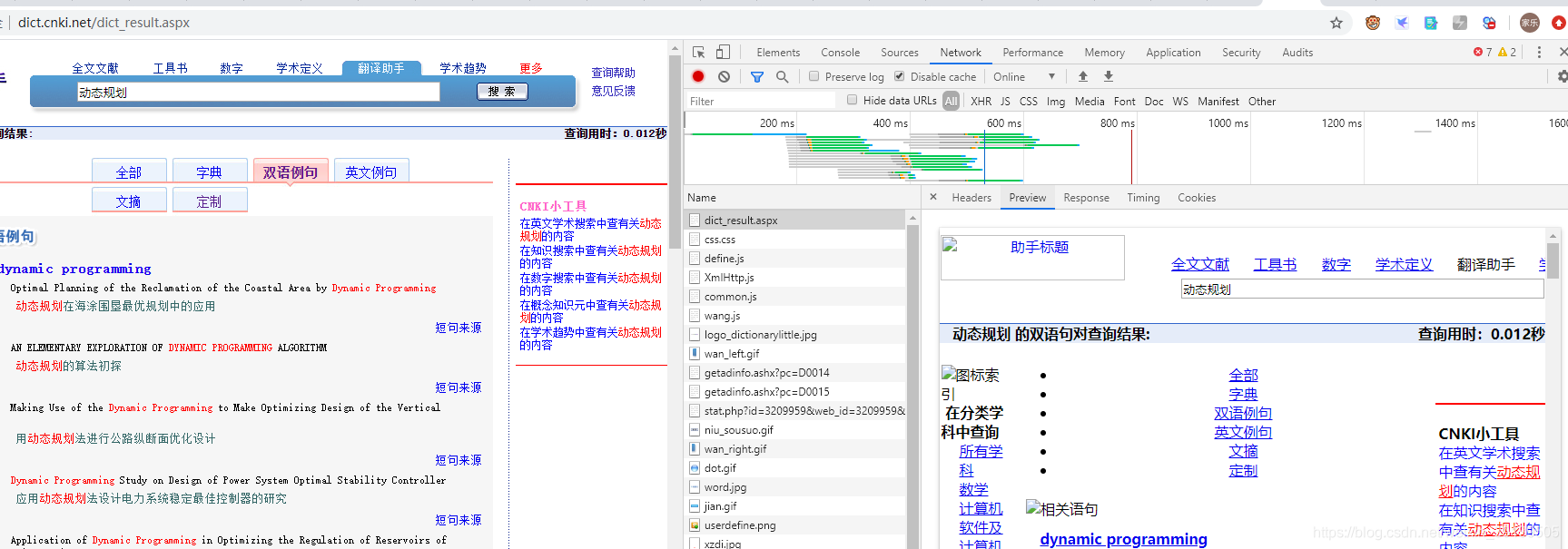
通过查看 Preview 可以看到网页源代码是放在:dict_result.aspx 中,那么我们直接根据它的 headers 构造请求头:

def crawl(url):
header = {
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'accept-encoding': "gzip,deflate",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
'cache-control': "no-cache",
'connection': "keep-alive",
'cookie': "Ecp_ClientId=1190617212402883927; cnkiUserKey=41b7ffaf-85e4-417d-376e-9d896e89b5fc; OUTFOX_SEARCH_USER_ID_NCOO=202854832.3388026; UM_distinctid=17096417d21285-090cc6aba1c552-6701b35-144000-17096417d223dc; ASP.NET_SessionId=etpdn15sj14efvr2ymak15hg; SID=203006; amid=fc0a8fe8-c8fe-42d5-a63f-9d0e7f494dc8; hw=wordList=%u52a8%u6001%u89c4%u5212%5e%u8ba1%u7b97%u673a%5e%u8ba1%u7b97%5e%u4e8c%u53c9%u6811%5e%u7a7f%u7ebf%u4e8c%u53c9%u6811%5e%u6811%5e%u4e8c%u5206%u7b97%u6cd5; CNZZDATA3209959=cnzz_eid%3D231822529-1583409734-null%26ntime%3D1586737892",
'host': "dict.cnki.net",
'upgrade-insecure-requests': "1",
# 'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
'user-agent': "Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
}
try:
s = requests.Session()
s.mount('http://',HTTPAdapter(max_retries=3))#设置重试次数为3次
s.mount('https://',HTTPAdapter(max_retries=3))
response = s.get(headers=header,url=url,timeout=5)
response.close()
response.encoding = response.apparent_encoding
except Exception as e:
print(e)
return ""
return response.text
跟着网页有什么填什么就完事了。
- 第二步解析网页源代码,以关键字
动态规划为例子。我们要获取全部的双语例句首先要知道有多少页的数据。
页面信息所在位置点击检查可以看到:
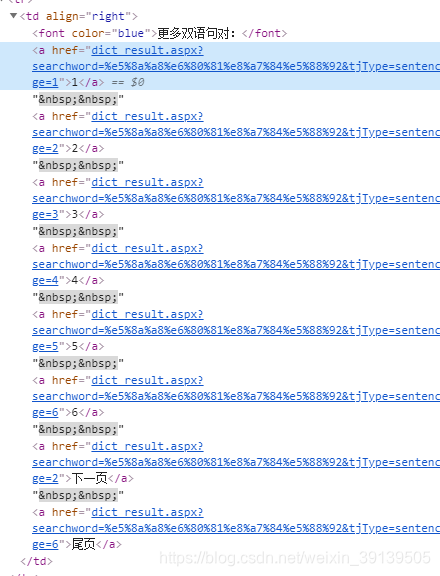
这里我的做法是将这部分的数据先正则表达式匹配下来,再进一步解析,先看代码:
# 获取页面数,最小为1
def page_num(html):
if html==None:
return 1
# 获取有关页面信息的字符串规则
pattern1 = re.compile(r'更多双语句对:(.*?)<\/a>[ ]*<\/tr>',re.I)
if len(re.findall(pattern1,str(html)))==0:
return 1
else: page_info = re.findall(pattern1,str(html))[0]
pattern2 = re.compile(r'<a.*?>(\d)<\/a>',re.I)
max_page = int(re.findall(pattern2,str(page_info))[-1])
return max_page
上面为什么这么写主要要分析不同的情况,当只有一页数据时:界面是这样的:

这个时候由于 pattern1 匹配不到所以返回 1.。
由于 pattern2:<a.*?>(\d)<\/a> 只会匹配到

中间是数字的情况,所以若有多页的话,那么最后一个数据就是它的总页数。
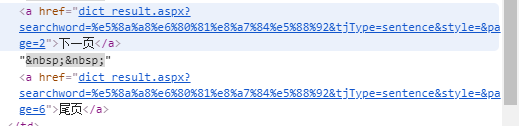
下一页和尾页由于不是整数所以不会匹配到。
- 下一步分析双语例句的结构,解析并提取,这里解析的方式用
xpath:
首先我们先看例句所在的 xpath 表达式是怎么样的:
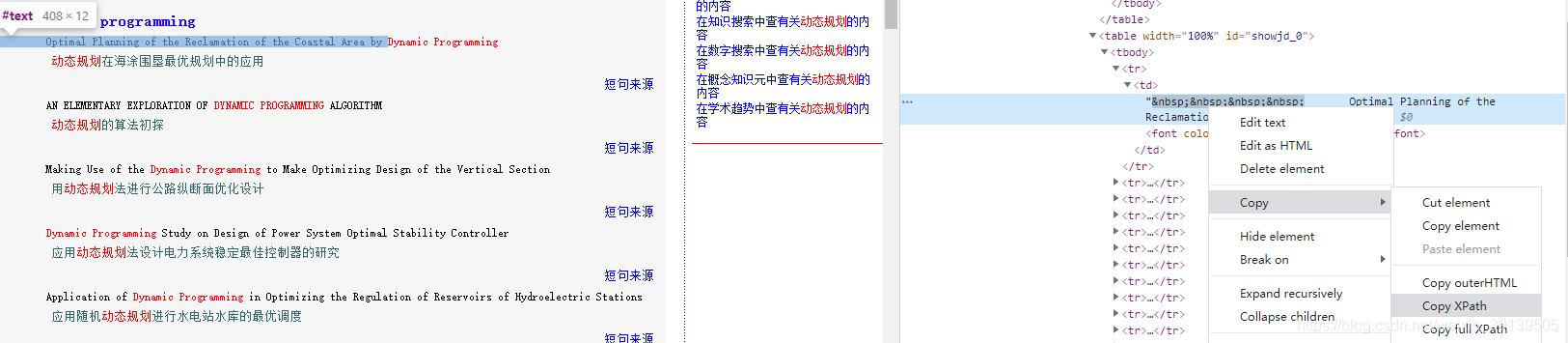
在例句所在位置点击检查,再到elements中右键点击复制 xpath 表达式:
//*[@id="showjd_0"]/tbody/tr[1]/td/text()
//*[@id="showjd_1"]/tbody/tr[1]/td/text()
通过对比可以发现每一个短语对应的例句对应不同的 id,并且是逐一增加的。这样的话,我们在解析页面时还得先知道这个页面有多少个短语,所以先解析页面存在的短语,同理点击短语查看xpath表达式:
//*[@id="lblresult"]/table[1]/tbody/tr[2]/td/table/tbody/tr[1]/td/table[1]/tbody/tr/td/font/b/a
//*[@id="lblresult"]/table[1]/tbody/tr[2]/td/table/tbody/tr[1]/td/table[3]/tbody/tr/td/font/b/a
可以看到每一个短语之间的间隔是 table+2。
这样我们可以构造我们的xpath表达式为 ://*[@id="lblresult"]/table[1]/tr[2]/td/table/tr[1]/td/table['+str(i)+']/tr/td/font/b/a。
# //*[@id="lblresult"]/table[1]/tr[2]/td/table/tbody/tr[1]/td/table[15]/tr/td/font/b/a
# 获取页面中存在的短语,返回一个短语列表
def parse_phrase(html):
if html == None:
return []
try:
phrase_list = []
tree = etree.HTML(html)
# 先计算table节点有多少个,才能知道循环的上限
num = int(tree.xpath('count(//*[@id="lblresult"]/table[1]/tr[2]/td/table/tr[1]/td/table)'))
for i in range(1,num,2):
phrase_xpath = '//*[@id="lblresult"]/table[1]/tr[2]/td/table/tr[1]/td/table['+str(i)+']/tr/td/font/b/a'
phrase = tree.xpath(phrase_xpath+'//text()')[0].strip()
phrase_list.append(phrase)
except Exception as e:
print(e)
return phrase_list
有了短语列表了以后,我们就可以知道例句中的 id 的范围。
# //*[@id="showjd_0"]/tbody/tr[1]/td
# start 是 id 的起点
# end 是 id 的终点
def parse_original_sentence(html,start,end):
if html == None:
return "",""
tree = etree.HTML(html)
e_string = ""
c_string = ""
for i in range(start,end+1):
id = '//*[@id="showjd_' + str(i) + "\"]"
num = int(tree.xpath('count('+id+'/tr)'))
for index in range(1,num,3):
e_sentence_xpath = id + "/tr[" + str(index) + "]/td//text()"
en_list = tree.xpath(e_sentence_xpath)
en_list = [ii.strip() for ii in en_list]
en = " ".join(en_list)
e_string = e_string + en.lower().strip()
e_string = e_string + '\n'
# print(en)
c_sentence_xpath = id + "/tr[" + str(index+1) + "]/td//text()"
ch_list = tree.xpath(c_sentence_xpath)
ch_list = [ii.strip() for ii in ch_list]
ch = "".join(ch_list)
c_string = c_string + ch.strip()
c_string = c_string + '\n'
# print(ch)
return e_string,c_string
同样的分析方法用来爬取 更多界面的中的未完全匹配句对
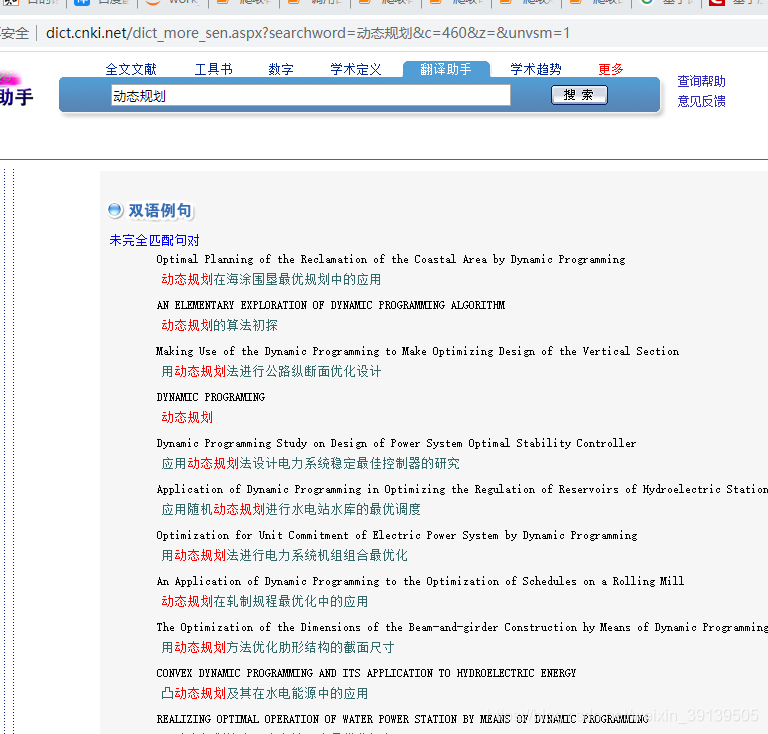
# http://dict.cnki.net/dict_more_sen.aspx?searchword=%E7%A9%BA%E9%97%B4&unvsm=1&t=&s=0&c=506&z=I138&page=2
# //*[@id="lblresult"]/table/tbody/tr/td/table/tbody/tr[3]/td/table/tbody/tr[2]/td
def crawl_and_parse_more_html(data,style):
prefix_url = "http://dict.cnki.net/dict_more_sen.aspx?searchword=" + data +"&unvsm=1&t=&s=0&c=100&z=" + style +"&page="
en_string = ""
ch_string = ""
for i in range(1,6):
try:
url = prefix_url + str(i)
html = crawl(url)
time.sleep(0.1)
tree = etree.HTML(html)
num = int(tree.xpath('count(//*[@id="lblresult"]/table/tr/td/table/tr[3]/td/table/tr)'))
if num == 4:
break
else:
for index in range(2,num,3):
en_xpath = '//*[@id="lblresult"]/table/tr/td/table/tr[3]/td/table/tr[' + str(index) + ']/td//text()'
en_list = tree.xpath(en_xpath)
en_list = [ii.strip() for ii in en_list]
en = " ".join(en_list)
en_string = en_string + en.lower().strip()
en_string = en_string + '\n'
ch_xpath = '//*[@id="lblresult"]/table/tr/td/table/tr[3]/td/table/tr[' + str(index+1) + ']/td//text()'
ch_list = tree.xpath(ch_xpath)
ch_list = [ii.strip() for ii in ch_list]
ch = "".join(ch_list)
ch_string = ch_string + ch.strip()
ch_string = ch_string + '\n'
# print(ch)
except Exception as e:
print(e)
return en_string,ch_string
下面来解析一下网页连接:
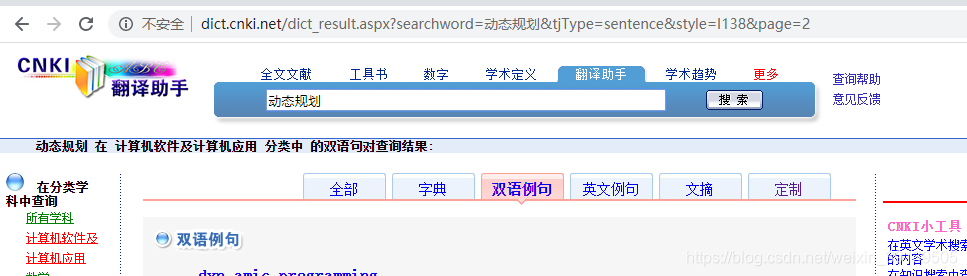
可以看到 style 指的是 查询分类,page 指的是当前所在的页面,searchword 是检索的关键词。
其中分类中 I138 为 计算机软件及计算机应用,A002 为数学,I139 为互联网技术。知道这些就可以构造 url 爬取网页了。
主函数:
# http://dict.cnki.net/dict_result.aspx?searchword=%e7%ae%97%e6%b3%95&tjType=sentence&style=I138&page=2
if __name__ == "__main__":
# 用来获取检索关键字的文本
data_file = r"E:/大四下/数据/例句/知网例句/关键词2.txt"
# 英语例句存放的文件
en_save_file = r"E:/大四下/数据/例句/知网例句/cnki_liju.en"
# 中文例句存放的文件
ch_save_file = r"E:/大四下/数据/例句/知网例句/cnki_liju.ch"
# 这个是短语存放的文件
# phrase_save_file = r'E:/大四下/数据/例句/知网例句/关键词2.txt'
# 以追加的方式打开
en_fw = open(en_save_file,'a+',encoding='utf8')
ch_fw = open(ch_save_file,'a+',encoding='utf8')
# phrase_fw = open(phrase_save_file,'a+',encoding='utf8')
# 定义查询类别列表
style = ['A002','I139','I138']
with open(data_file,'r',encoding='utf8') as fr:
# 获取检索关键词
line = fr.readline()
while line:
if line!='\n':
data = line.strip()
# 构造公共前缀 url
prefix_url = "http://dict.cnki.net/dict_result.aspx?searchword=" + data
# 迭代类别分别爬取
for s in style:
print("data;{},s:{}".format(data,s))
prefix_url_tmp = prefix_url + "&tjType=sentence&style="+ s + "&page="
# 获取页数
url_for_get_page_size = "http://dict.cnki.net/dict_result.aspx?searchword=" + data + "&style="+s+"&tjType=sentence"
html_for_get_page_size = crawl(url_for_get_page_size)
if html_for_get_page_size == "":
continue
time.sleep(0.1)
page = page_num(html_for_get_page_size)
# print(page)
# 记录例句 id 的起始
start = 0
end = 0
for i in range(1,page+1):
url = prefix_url_tmp + str(i)
# print(url)
original_html = crawl(url)
if original_html == "":
continue
time.sleep(0.1)
#获取短语列表并写入文件
phrase_list = parse_phrase(original_html)
# for phrase in phrase_list:
# if phrase[0].encode('UTF-8').isalpha():
# print(phrase)
# phrase_fw.write(phrase)
# phrase_fw.write('\n')
# print(phrase_list)
# 根据短语列表计算 id 的起始
end = end + len(phrase_list)
print("start:{} and end:{}".format(start,end))
e_string,c_string = parse_original_sentence(original_html,start,end)
start = end
en_fw.write(e_string)
ch_fw.write(c_string)
# 爬取更多页面中的例句
e_string,c_string = crawl_and_parse_more_html(data,s)
en_fw.write(e_string)
ch_fw.write(c_string)
en_fw.flush()
ch_fw.flush()
line = fr.readline()
en_fw.close()
ch_fw.close()
phrase_fw.close()
print('ok')