是什么
Flink的前身是以构建下一代大数据分析平台为目标的大学科研项目Stratosphere。其于2014年4月被捐赠给Apache软件基金会作为孵化项目,并于同年年底升级为Apache的顶级项目。
Flink是基于实时流处理的一个组件。数据流可以分为无界流和有界流。无界流(DataStream)只有开始而没有结束,比如,外汇市场的不间断交易、服务器日志的持续生成等是无界流;而统计电商网站某个注册用户一周的交易量、生成某个用户每月的话费清单等是有界流(DataSet),它定义了开始节点和结束节点,并且这中间的数据是有序的。处理有界流也被称为批处理(Batch Processing)。
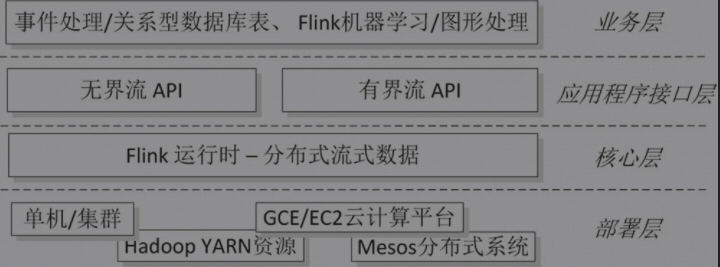
Flink系统架构图:
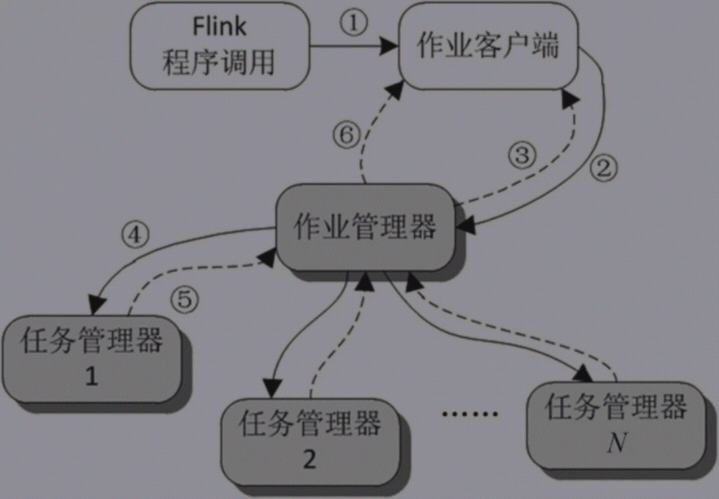
Flink核心层执行过程层
Spark是基于内存运算的分布式处理框架,也可以处理流式数据,而且Spark比Flink出名得早。Spark操作流式数据时是把无界流划分成多个固定时间窗的有界流来处理的;而Flink则正相反,它把有界流作为无界流的特例来处理。因此,Flink是一个更加“彻底”的流处理组件。
安装
一、单节点安装:所谓单节点指的是作业管理器和任务管理器运行在同一台机器上
- 官网下载最新版本的安装包http://flink.apache.org/
- 把tgz文件下载并解压缩到master机器中的/home/hadoop/bigdata/flink/
- 配置环境变量
export FLINK_HOME=/home/hadoop/bigdata/flink
export PATH=$FLINK_HOME/bin:$PATH
- 同时需要配置HADOOP和YARN_CONF_DIR的配置如下
export HADOOP_CONF_DIR=/home/hadoop/bigdata/hadoop/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/bigdata/hadoop/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
-
查看并修改配置文件$FLINK_HOME/conf/flink-conf.yaml,这里要注意我测试下来如果heap.size设置的太小,那么下一步就会启动不起来。我设置了jobmanager.memory.process.size: 1024m,taskmanager.memory.process.size: 1024m,是可以启动的。另外我修改了rest.port: 8082,因为服务器8081端口被mvn仓库占用了。
-
启动Flink服务
[hadoop@VM_0_6_centos ~]$ start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host VM_0_6_centos.
Starting taskexecutor daemon on host VM_0_6_centos.
- 查看JVM进程
[hadoop@VM_0_6_centos ~]$ jps -m
2297 StandaloneSessionClusterEntrypoint --configDir /home/hadoop/bigdata/flink/conf --executionMode cluster
2586 TaskManagerRunner --configDir /home/hadoop/bigdata/flink/conf -D taskmanager.memory.framework.off-heap.size=134217728b -D taskmanager.memory.network.max=67108864b -D taskmanager.memory.network.min=67108864b -D taskmanager.memory.framework.heap.size=134217728b -D taskmanager.memory.managed.size=241591914b -D taskmanager.cpu.cores=1.0 -D taskmanager.memory.task.heap.size=26843542b -D taskmanager.memory.task.off-heap.size=0b
2719 Jps -m
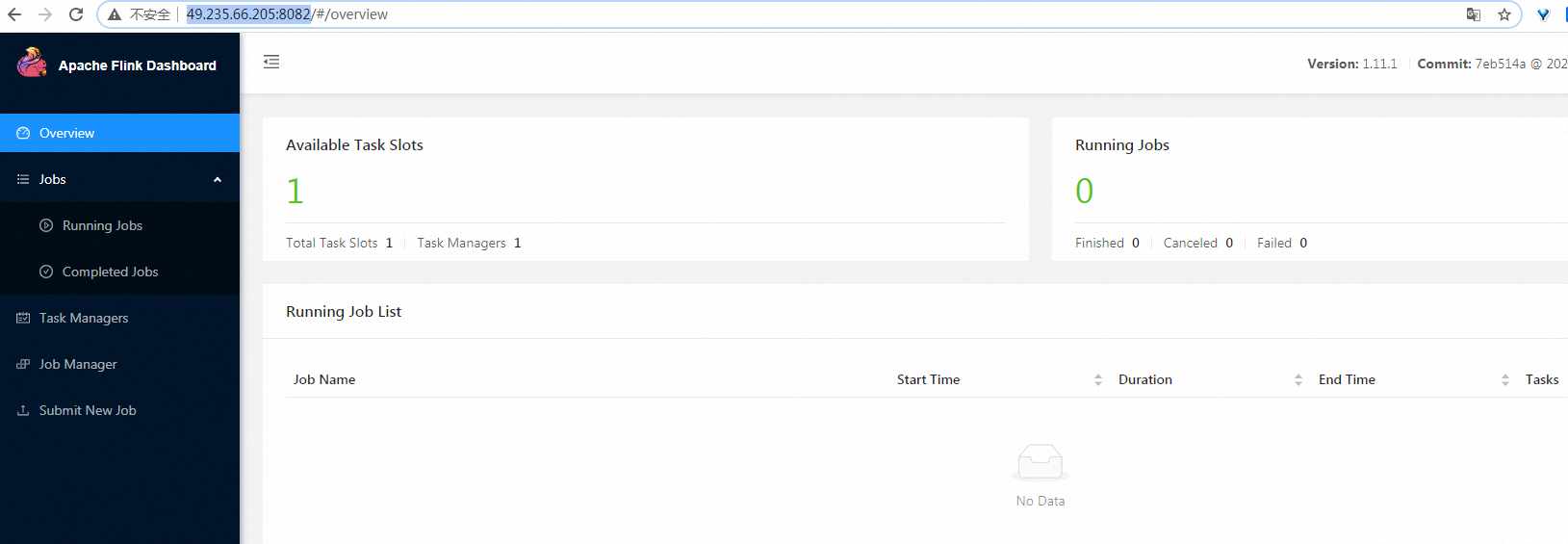
- 查看web端
URL:http://49.235.66.205:8082/
二、集群的安装:请参考官方文档
- master节点运行作业管理器
- 两个slave节点运行任务管理器
三、利用ZooKeeper实现Flink的高可用性:请参考官方文档
- 在上面的两种运行方式中,作业管理器服务只有一个,故存在单点故障的问题。Flink支持使用ZooKeeper作为实现高可用性的方式,即在Flink集群上运行多个作业管理器实例,由ZooKeeper选出其中一个作为首领,而其他服务处于待命状态。一旦这个服务宕机或出现故障,ZooKeeper就会从其他待命的作业管理器实例中选择一个来取而代之。
怎么用
场景一:后台提交一个java任务
比如示例examples/streaming/SocketWindowWordCount.jar
- 启动tcp服务,并输入字符
[root@VM_0_6_centos ~]# netcat -l -p 9090
- flink命令运行SocketWindowWordCount
[hadoop@VM_0_6_centos flink]$ flink run examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9090
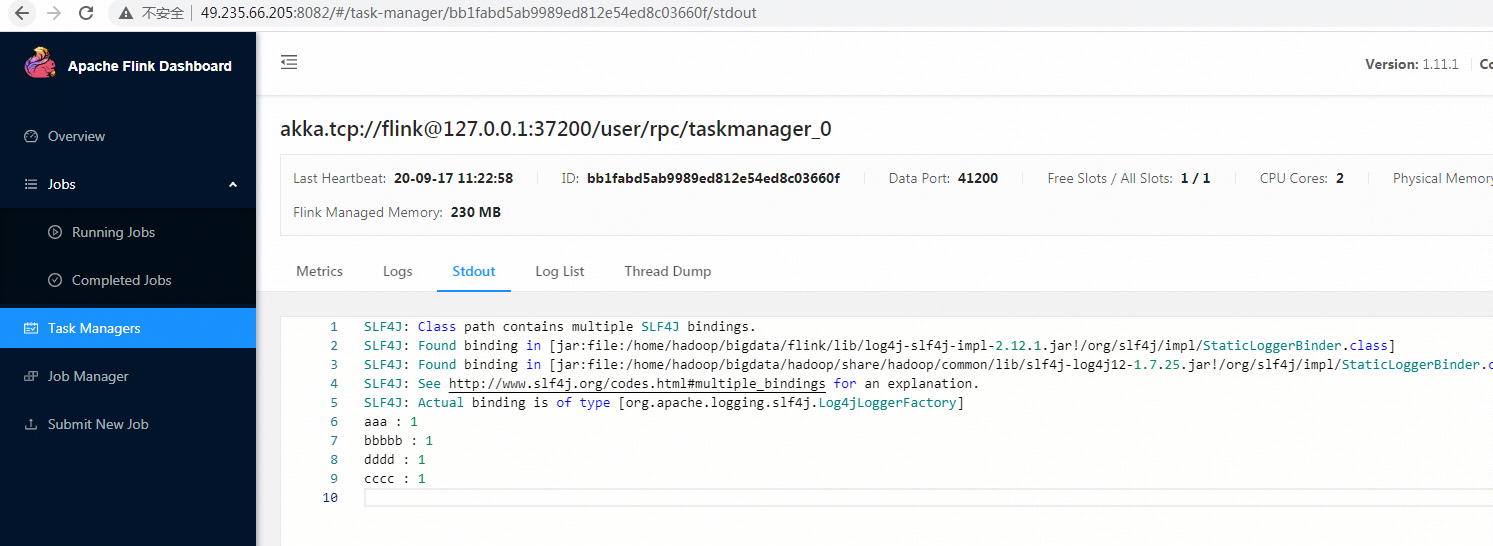
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/bigdata/flink/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/bigdata/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Job has been submitted with JobID 7a6b5708ed06c7c301caa3a28e46d349
- tcp服务输入一些字符来测试
[root@VM_0_6_centos ~]# netcat -l -p 9090
aaa
bbbbb cccc dddd
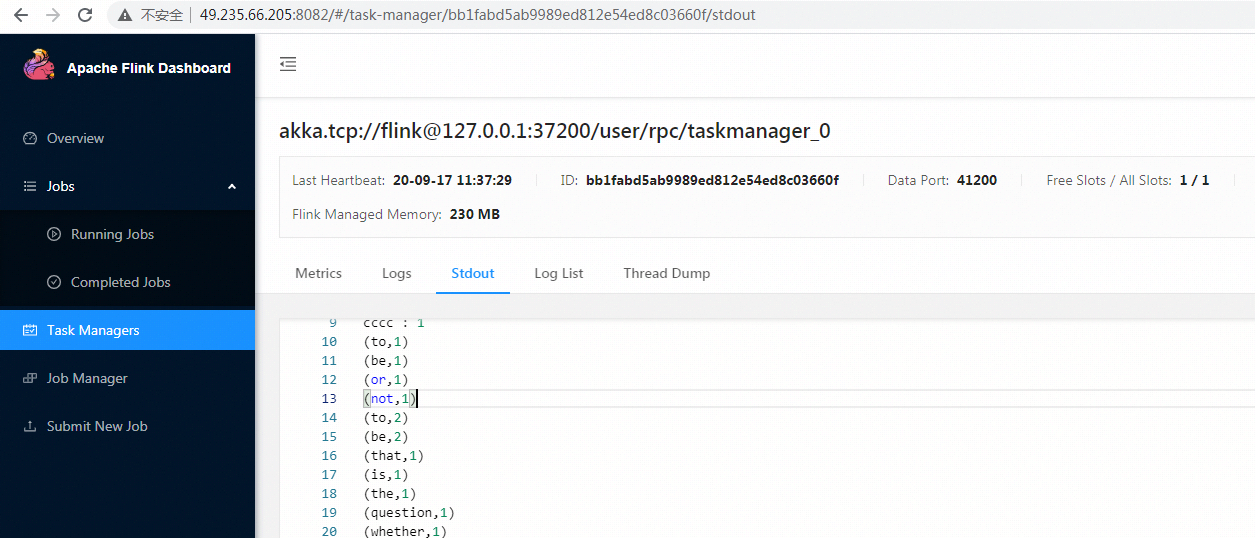
- 停止tcp服务,查看任务日志

场景二:后台提交一个python任务
- 提交python任务有一个先决条件是服务器安装python3.5+,我这里是3.6.8
[root@VM_0_6_centos ~]# python --version
Python 3.6.8
- 按照官方文档https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/ops/cli.html来执行如下命令
[hadoop@VM_0_6_centos flink]$ flink run -py examples/python/table/batch/word_count.py
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/bigdata/flink/lib/log4j-slf4j-impl-2.12.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/bigdata/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Results directory: /tmp/result
- 查看结果

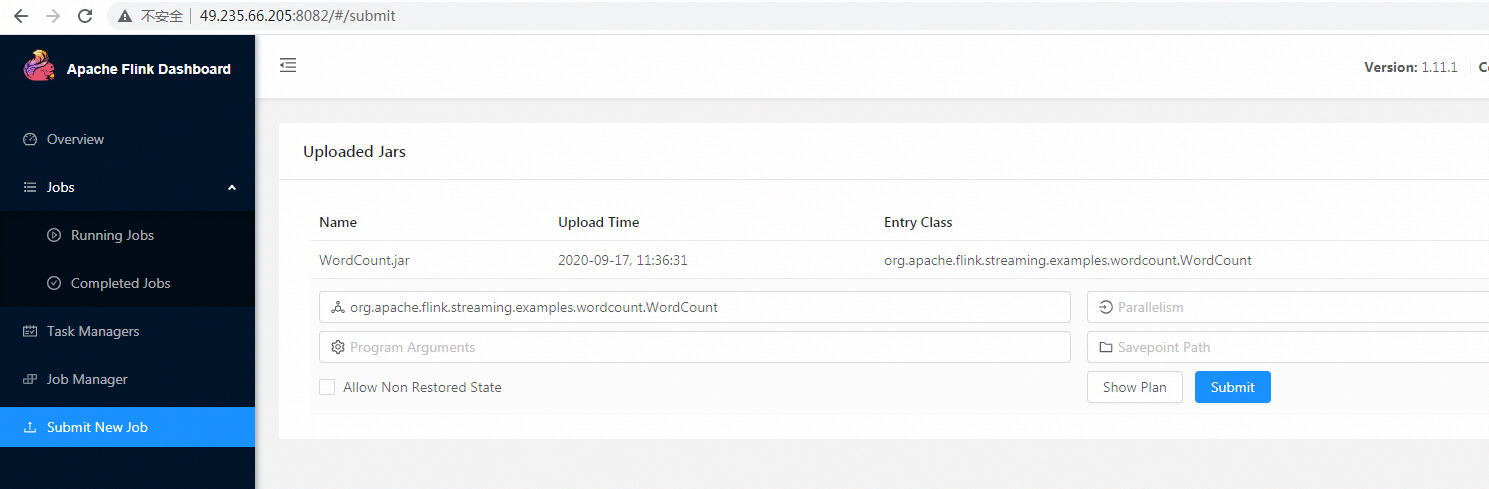
场景三:web前台提交一个java任务
- 创建一个项目,并导出为jar包(记得这里是完整的jar包,fat jar)
- 上传到flink的web控制台
- 指定MainClass,执行