第一步:标注数据集
使用到的工具是labelimg,可以直接下载exe文件,我这边就不做演示了
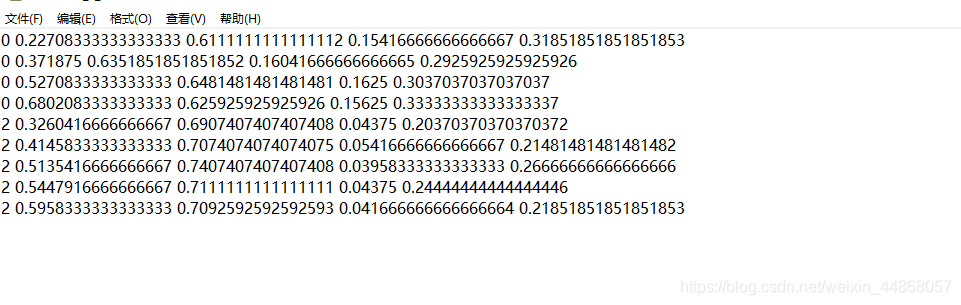
因为博主之前做过TensorFlow objection detection 识别,就用了原来的标注的数据集,这样可以省下很多时间,而我们只需要将xml文件改为txt格式
格式如下
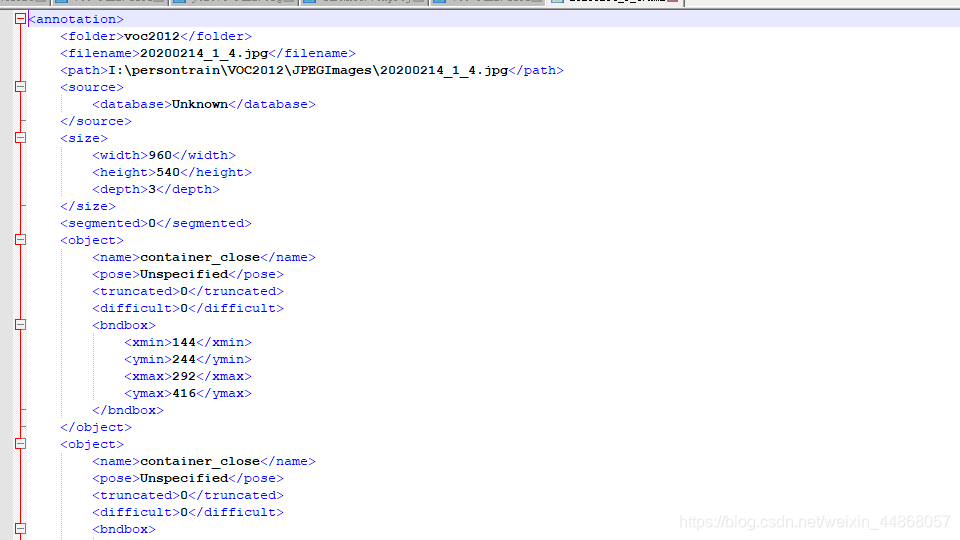
因为xml文件里面的格式是下面的
这里我会提供py代码(将网上的代码进行了更改)
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2012', 'train'), ('2012', 'val')]
classes = ["container_close", "container_open", "person"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id): # 转换这一张图片的坐标表示方式(格式),即读取xml文件的内容,计算后存放在txt文件中。
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year)) # 新建一个 label 文件夹,用于存放yolo格式的标签文件:000001.txt
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() # 读取txt文件中 存放的图片的 id:000001
list_file = open('%s_%s.txt'%(year, image_set), 'w') # 新建一个 txt文件,用于存放 图片的绝对路径:/media/common/yzn_file/DataSetsH/VOC/VOCdevkit/VOC2007/JPEGImages/000001.jpg
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id)) # 向 txt 文件中写入 一张图片的绝对路径
convert_annotation(year, image_id) # 转换这一张图片的坐标表示方式(格式)
list_file.close()
这个代码执行完会生成2个文件和一个文件夹(这也是后期训练所要用到的东西)

第二步:修改配置文件
因为博客用的cmake编译,所以会有Release文件夹,我这边全程在x64/Release文件夹下面,如果你们没有用cmkae编译,你们只需要在x64进行(后期全程在x64文件夹下面)
首先进入data文件夹
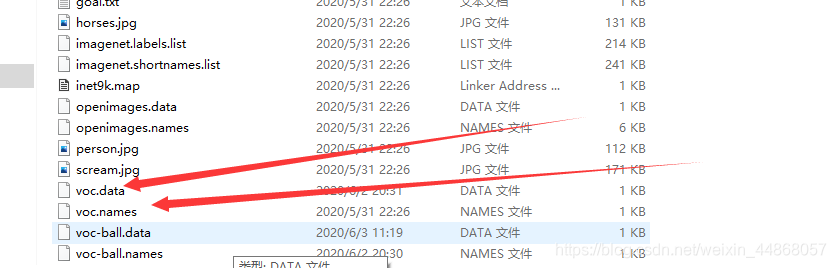
复制这2个文件,然后把名字分别改成voc-ball.data和voc-ball.names
然后打开voc-ball.names,本来里面是20个类的名字,这边需要改成你训练类的名字(我这边训练3个类)
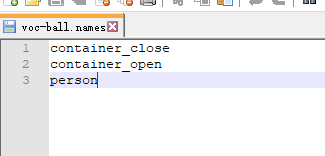
改完后保存退出,
然后打开voc-ball.data(按照我的对照改就行了)
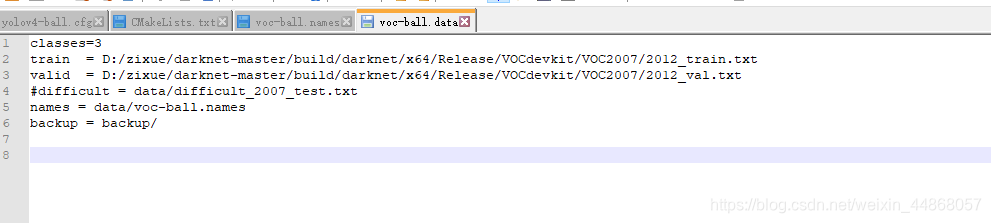
接着进入cfg文件夹,复制yolov4-voc.cfg并重新命名为yolov4-ball.cfg,打开此文件,下面介绍如何改参数
batch不宜过大,过大显存会爆,导致不能训练
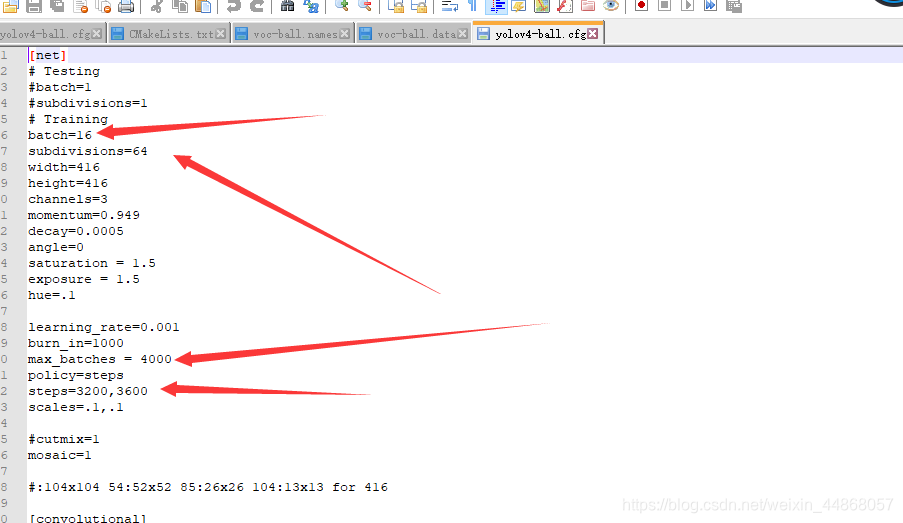
我们还需要改3个地方的classes(我用的是notepad++打开)搜索classes,然后classes前面都有对应的filters,这两个都要改,filters与classes的关系是filters = (classes +5) *3
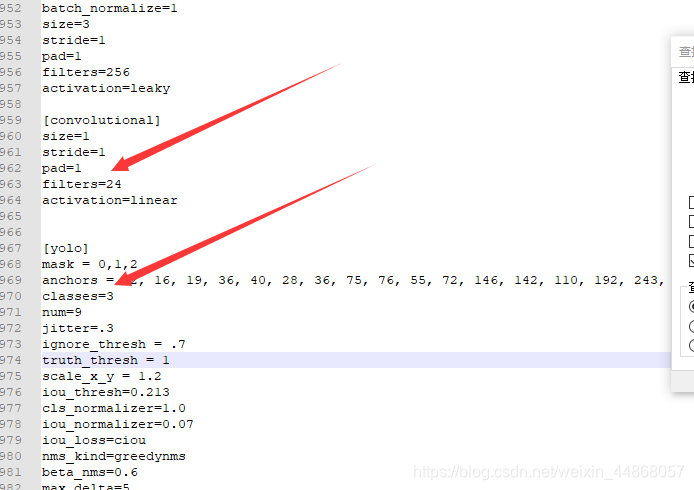
改完之后保存
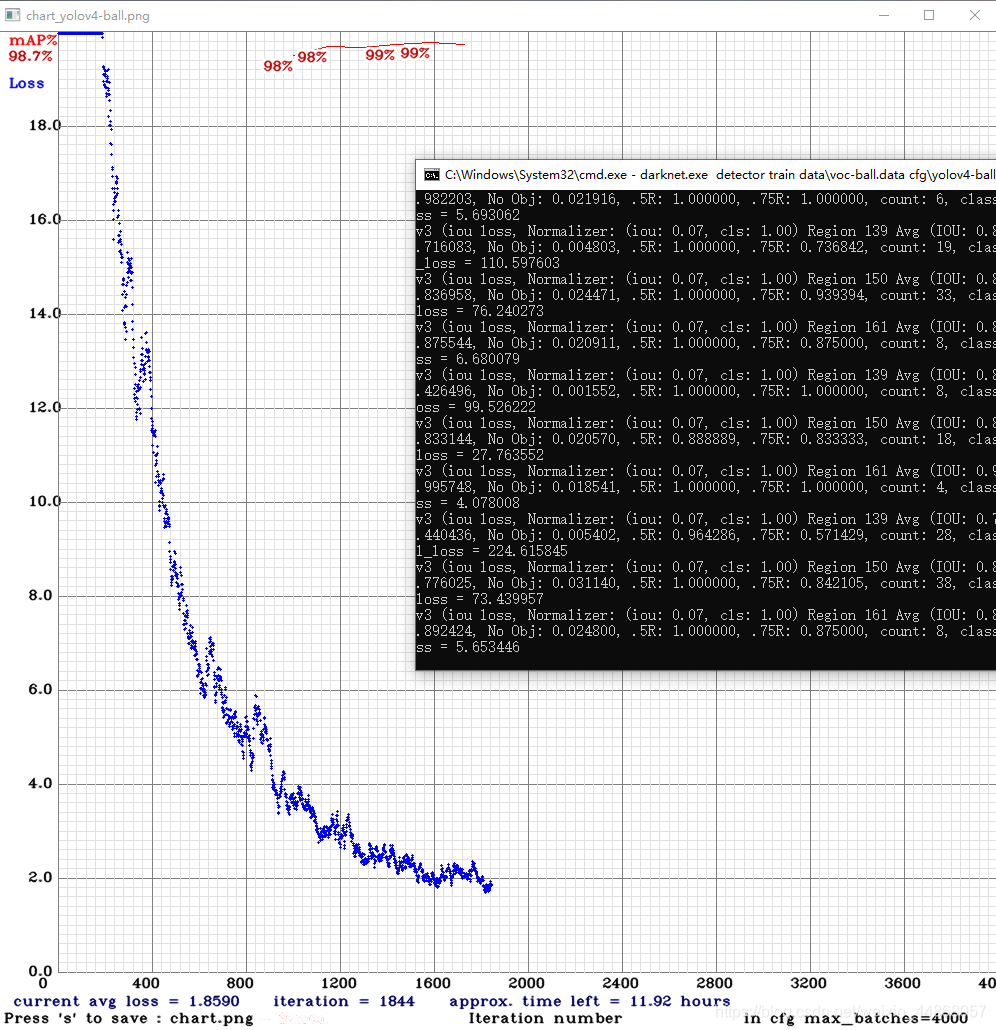
第三步开始训练
首先下载预训练yolov4.conv.137
(链接:https://pan.baidu.com/s/1GG-gwaU0DXC3pfA-kmtX0w
提取码:pqxr)
放到刚刚的目录下,
然后输入下方的命令,就可以训练了
darknet.exe detector train data\voc-ball.data cfg\yolov4-ball.cfg yolov4.conv.137 -map