cube计算:
当有层次维度时,公式如下:
(hierarchy.size() + 1) * hierarchyDimsList.size() * (1 << jointDimsList.size()) * (1 <<
normalDims.size())
当没有层次维度时,公式如下:
1 << jointDimsList.size()) * (1 << normalDims.size()
hierarchyDimsList.size(): 层次维度的个数。
hierarchy.size(): 每个层次维度包含的维度个数。
jointDimsList.size(): 联合维度的个数。
normalDims.size(): 正常维度的个数,即不是强制维度,层次维度,联合维度的维度数目。
根据cube在build的顺序,进行优化
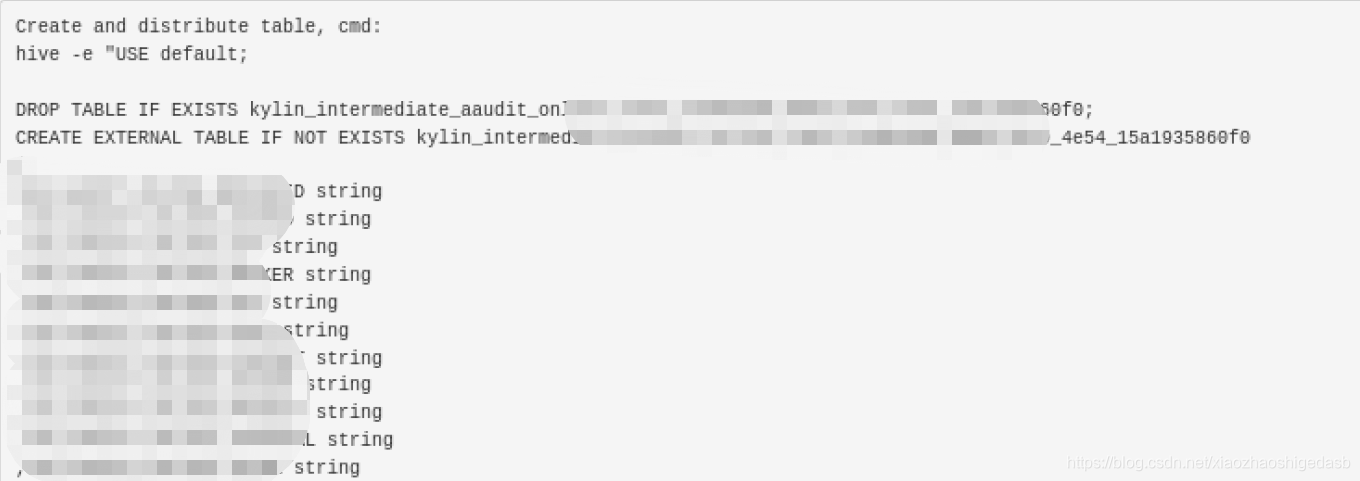
#1 Step Name: Create Intermediate Flat Hive Table
第一步是根据我们自定义的cube模型来生成原始数据,直接使用hive -e执行sql语句,中间设置了大量的hive
的配置项,数据格式默认为SEQUENCEFILE。
#2 Step Name: Redistribute Flat Hive Table
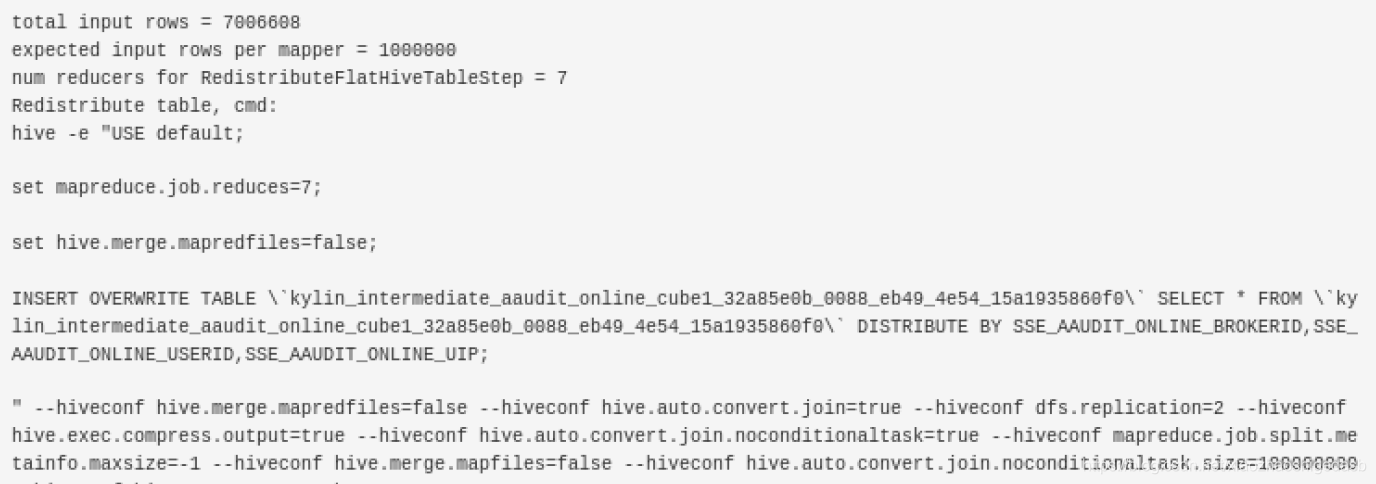
第二步是在第一步的基础之上,计算原始数据的行数,根据rows,估算map、reduce的数量,这一步主要是根据
我们的cube模型做了一次的DISTRIBUTE BY ,同样也有默认的hive的配置项。
作用:防止不均匀
默认是100W一个文件,你可以通过conf/kylin.properties
kylin.job.mapreduce.mapper.input.rows=500000这个进行配置
在构建cube的时候有一个配置叫做shard by这个可以设置,这个用于高基数的维度有很大作用,可以避免数据的重新分布也就是减少了shuffle 这个起码可以减少40%的build时间.

#3 Step Name: Extract Fact Table Distinct Columns
这一步通过使用HyperLogLog计数器预估每个cuboid的行数,依次来收集cube的统计信息。如果你发现mapper任
务执行非常慢,通过就意味着cube设计的太复杂,可以参考:Cube设计优化,对cube进行优化,使cube更加精简
。如果reducer发生了OOM错误,通常意味着cuboid的维度组合数太多或者默认的yarn内存分配不能满足需求。如
果此步骤不能在合理的时间内完成,请重新对cube进行设计,因为真正的build过程会花费更长的时间。
在这个阶段 kylin会使用mr来获取不同的维度的value,以供下一步进行编码 生成字典
如果发现mapper工作的非常慢,这显示是你的cube太复杂了,请进行剪枝
如果发现reducer发生了oom,这显示你的cubiod发生了膨胀(剪枝).或者是你的yarn 内存设置.

#4 Step Name: Build Dimension Dictionary
这一步是根据上一步生成的distinct column文件和维度表计算出所有维度的词典信息,词典是为了节约存储而
设计的,用于将一个成员值编码成一个整数类型并且可以通过整数值获取到原始成员值,每一个cuboid的成员
是一个key-value形式存储在hbase中,key是维度成员的组合,但是一般情况下维度是一些字符串之类的值(例
如商品名),所以可以通过将每一个维度值转换成唯一整数而减少内存占用,在从hbase查找出对应的key之后再
根据词典获取真正的成员值。 是在kylin进程内的一个线程中执行的,它会创建所有维度的dictionary,如果是
事实表上的维度则可以从上一步生成的文件中读取该列的distinct成员值(FileTable),否则则需要从原始的
hive表中读取每一列的信息(HiveTable),根据不同的源(文件或者hive表)获取所有的列去重之后的成员
列表,然后根据这个列表生成dictionary,kylin中针对不同类型的列使用不同的实现方式,对于time之类的
(date、time、dtaetime和timestamp)使用DateStrDictionary,这里目前还存在着一定的问题,因为这种
编码方式会首先将时间转换成‘yyyy-MM-dd’的格式,会导致timestamp之类的精确时间失去天以后的精度。针
对数值型的使用NumberDictionary,其余的都使用一般的TrieDictionary(字典树)。这些dictionary会作
为cube的元数据存储的kylin元数据库里面,执行query的时候进行转换。
这一步之前使用内存进行,现在使用MR任务来完成。
#5 Step Name: Save Cuboid Statistics
#6 Step Name: Create HTable
这两步非常快,建表。
#7 Step Name: Build Base Cuboid
这一步是通过临时表构建基本的cuboid,这是逐层算法的第一轮MR任务。Mapper的数量等于步骤二中reducer
的数量;而Reducer(这里指的是本步骤中启动的reducer)的数量是通过cube的统计信息预估出来的:默认每
500M使用一个reducer。如果你发现reducer的数目很少,可以通过在kylin.properties中对配置项
“kylin.job.mapreduce.default.reduce.input.mb”设置更小的值,来获取更多的集群资源,如下所示:
kylin.job.mapreduce.default.reduce.input.mb=200
这个阶段需要很多的内存 默认是3G 这个你可以通过配置文件conf/kylin_job_conf_inmem.xml进行配置<property>
<name>mapreduce.map.memory.mb</name>
<value>6144</value>
<description></description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx5632m</value>
<description></description>
</property>
#8 Step Name: Build N-Dimension Cuboid : level 1~N
这些步骤是逐层算法的处理过程,每一步都使用前一步的输出作为输入,然后去除某个维度进行聚合,生成一个
子cuboid。例如,对于cuboid ABCD,去除维度A可以获得cuboid BCD,去除维度B可以获得cuboid ACD等。
有些cuboid可以通过一个以上的父cuboid聚合而成,在这种情况下,Kylin将会选择最小的父cuboid。例如,
AB能够通过ABC(id:1110)和ABD(id:1101)聚合生成,因此ABD会被作为父cuboid使用,因为它的id比
ABC要小。基于以上处理,如果D的基数很小,那么此次聚合操作就会花费很小的代价。因此,当设计cube的
rowkey顺序的时候,请记住,将低基数的维度列放在尾部。这不仅对cube的构建过程有好处,而且对cube查询
也有好处,因为后聚合(应该是指在HBase查找对应cuboid的过程)也遵循这个规则。
通常从N-D到(N/2)-D的构建过程很慢,因为这是一个cuboid爆炸增长的过程:N-D有1个cuboid,(N-1)-D有
N个cuboid,(N-1)-D有N*(N-1)个cuboid等等。在(N/2)-D步骤之后,构建过程会越来越快。
#15 Step Name: Build Cube In-Mem
构建cube,使用逐块算法。
逐块算法(也称作“in-mem”算法)。该算法只使用一轮MR任务来构建所有的cuboid,但它比逐层算法需要更多
占用更多的内存。该步骤在执行的时候会使用“conf/kylin_job_conf_inmem.xml”中的相关配置项。默认情况
下,每个mapper需要3G的内存。如果集群有足够大的内存,可以在“conf/kylin_job_conf_inmem.xml”中通过
修改配置来获取更大的内存,这样就可以处理更多的数据,并且性能也会更好。配置项如下:
mapreduce.map.memory.mb
mapreduce.map.java.opts
#16 Step Name: Convert Cuboid Data to HFile
这一步会启动一个MR任务用来将cuboid文件(顺序文件格式)转换为Hbase的HFile文件。Kylin通过cube的统
计信息来计算HBase的region个数,默认每个region大小是5G。Region数越多,就会使用更多的reducer。如果
发现reducer的数目很少,并且性能很差,就可以在“conf/kylin.properties”中增加如下配置项:
kylin.hbase.region.cut=2 kylin.hbase.hfile.size.gb=1
如果不能确定一个HBase的region该设置为多大,请联系HBase管理员。
#17 Step Name: Load HFile to HBase Table
这一步使用了HBase API将HFile导入到HBase的region中,这一步很简单,也很快。
#18 Step Name: Update Cube Info
将数据导入Hbase中之后,Kylin会将新生成的segment在元数据中的状态修改为ready。这一步也非常快。
#19 Step Name: Hive Cleanup
这一步主要就是从Hive中删除临时表。由于在上一步中,已经将segment的状态修改为ready,所以这一步的操作
不会对segment产生任何影响。即使这一步执行发生了错误,也不需要担心,因为所有的垃圾都会在Kylin执行
StorageCleanupJob的时候进行回收。
清理命令
# 查看需要清理的数据
./bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
# 清理
./bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
#20 Step Name: Garbage Collection on HBase

参考:https://kylin.apache.org/cn/docs/howto/howto_optimize_build.html