衍生维度
概念
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
注意:
虽然衍生维度具有非常大的吸引力,但这也并不是说所有维度表上的维度都得变成衍生维度,如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,则不建议使用衍生维度。
如图

原本三个维度构建时,cuboid= 2^3 -1 = 7 个
维度表中 A是主键,不重复,那么E 就可以认为是A 的衍生维度,在构建时就可以用A 来代替E 这个维度,所以最后构建时,Cuboid = 2^2 -1 = 3 个
这样构建cube时效率就会很高,而查询时如果设计到E这个维度,就会用E 来 替换 A ,从而得出结果。
具体操作
在选维度时,选定维度表中的衍生维度
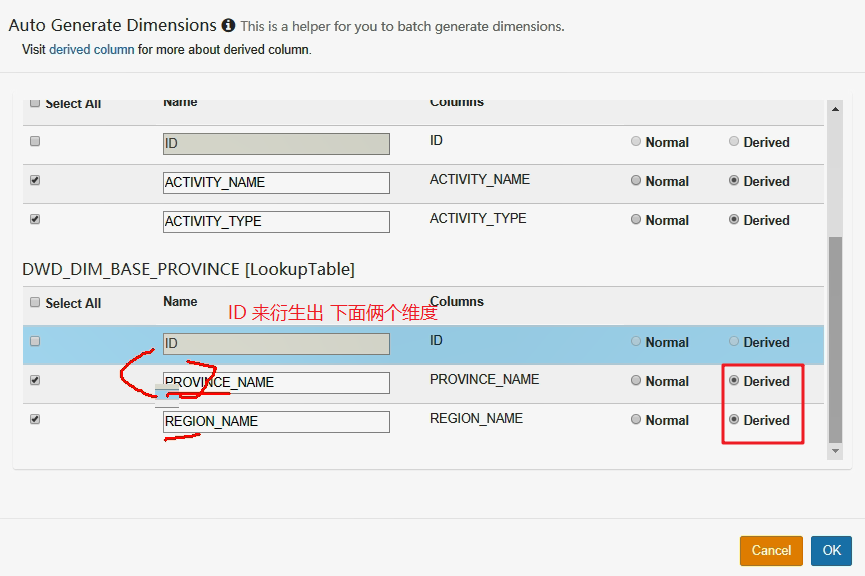
然后再聚合组中选定这俩个维度表的主键
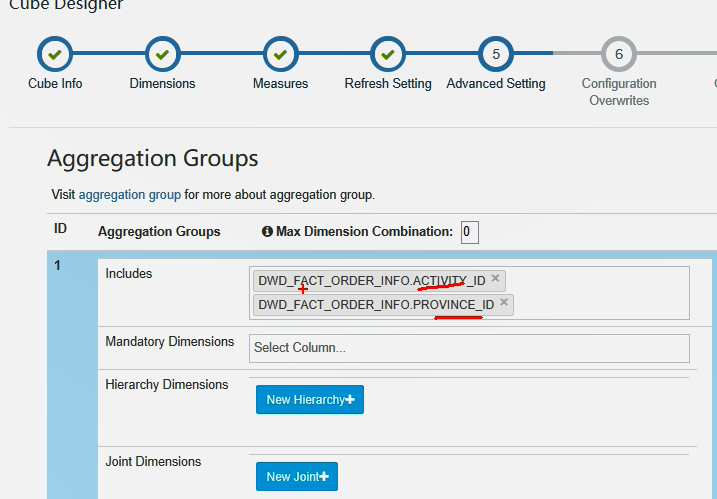
设定完成后,可以看到Cuboid = 3个
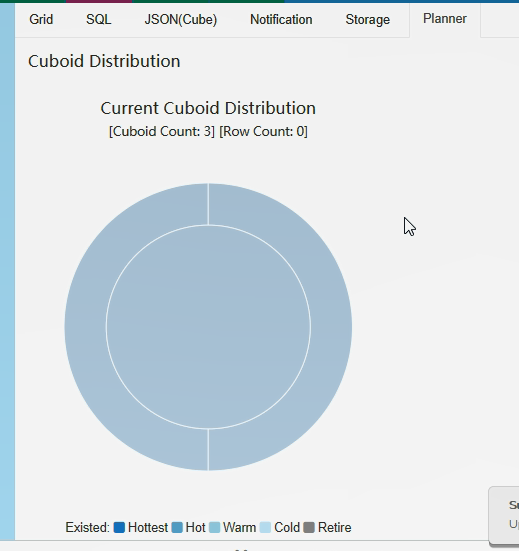
聚合组中维度的设置
强制维度
如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度,不包含该维度的Cuboid则不会计算(一维维度不会计算在内)
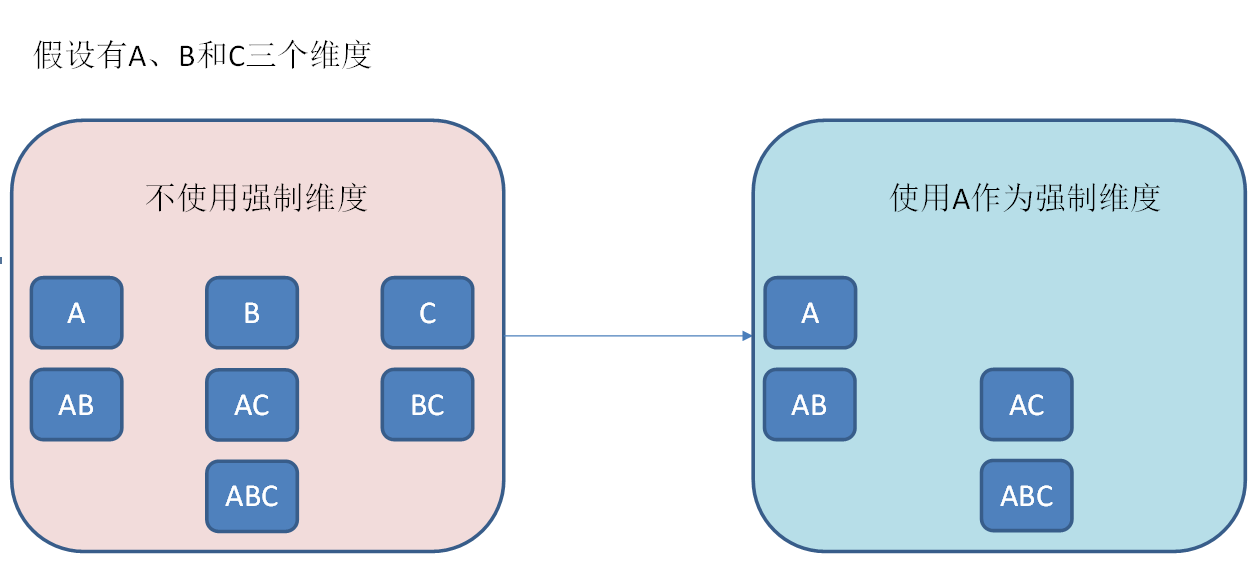
操作如下

层级维度
简单来说,B这个维度依赖于A这个维度,如果只有B没有A 则不会计算

操作如下

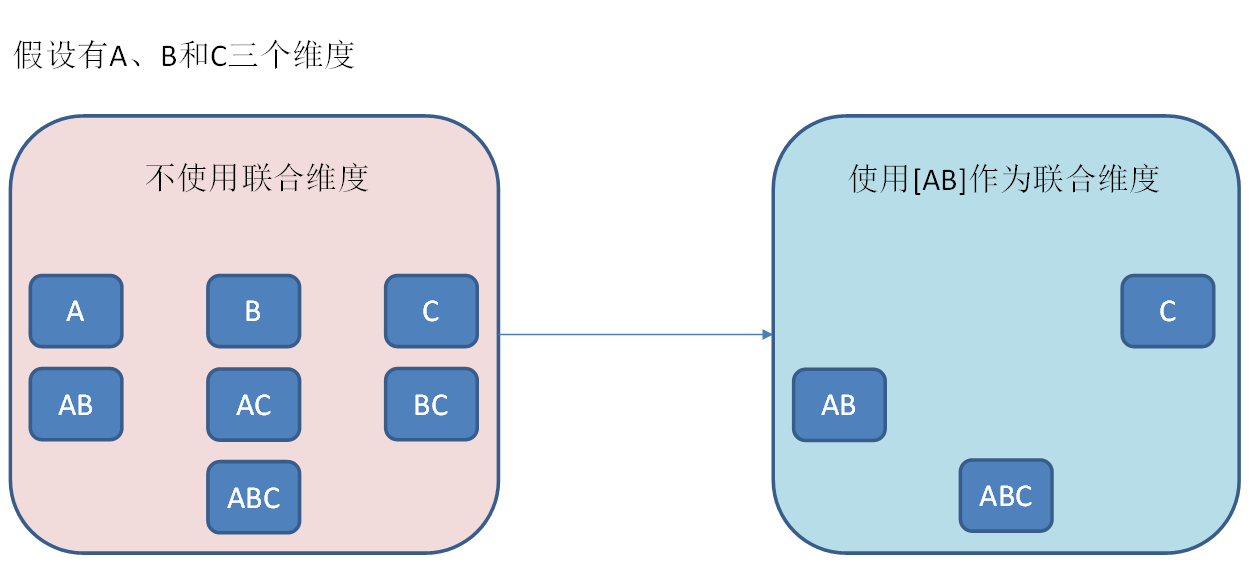
联合维度
联合维度之间必须同时存在


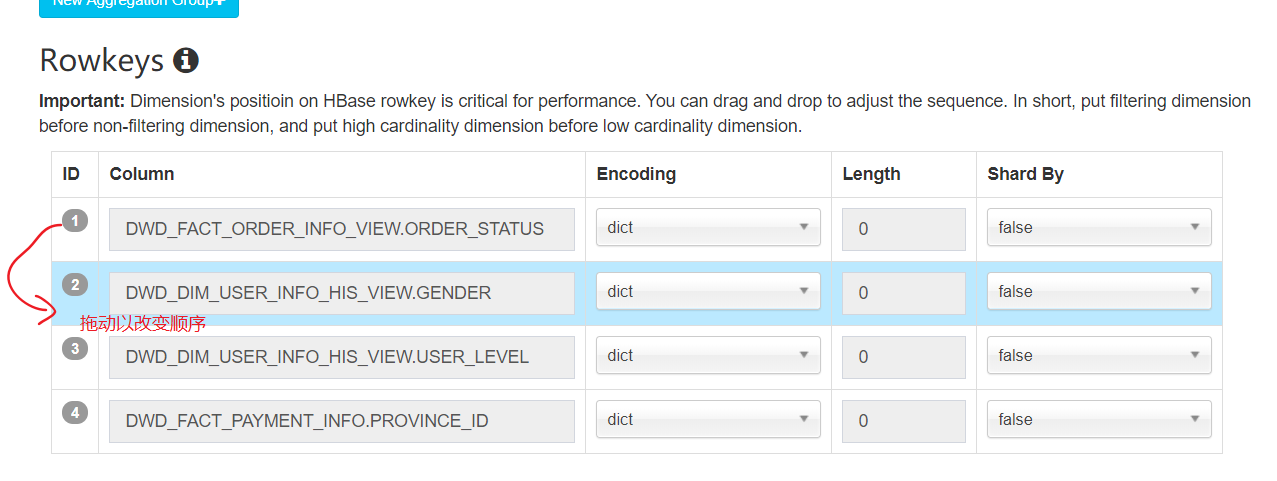
RowKey 的设计
1)被用作where过滤的维度放在前边。

2)基数大的维度放在基数小的维度前边。
当cube 从 三维 往 二维 聚合运算时,会默认选择cuboid小的 三维 进行聚合, 从图中可以看出,C 的 基数 比 D 的基数大的多,所以右边的运算速度会更快一点

操作
并发粒度优化(了解)
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,
从而优化Cube的查询速度。具体的实现方式如下:构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,
如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。
用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
Cube 在 HBase中是以 Segment的形式存储的,这里其实就是在优化Hbase的分区策略,分区越多,并发度就会越好,一般保持默认就行
设置方法