Cuboid剪枝优化
为什么要进行Cuboid剪枝优化
将以减少Cuboid数量为目的的Cuboid优化统称为Cuboid剪枝。在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果被称为Cuboid。
- 如果有4个维度,可能最终会有2^4 =16个Cuboid需要计算。但在实际开发中,用户的维度数量一般远远大于4个。
- 如果有10个维度,那么没有经过任何优化的Cube就会存在2^10 =1024个Cuboid
- 如果有20个维度,那么Cube中总共会存在2^20 =104 8576个Cuboid
这样的Cuboid的数量就足以让人想象到这样的Cube对构建引擎、存储引擎压力非常巨大。因此,在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化。
Cube的剪枝优化是一种试图减少额外空间占用的方法,这种方法的前提是不会明显影响查询时间。在做剪枝优化的时候, - 需要选择跳过那些“多余”的Cuboid --》结合业务来判断哪些cuboid是多余
- 有的Cuboid因为查询样式的原因永远不会被查询到,因此显得多余–》层级维度,省市区,年月日
- 有的Cuboid的能力和其他Cuboid接近,因此显得多余 --》衍生维度
Kylin提供了一系列简单的工具来帮助他们完成Cube的剪枝优化

实际生产中,有部分cuboid是永远使用不到的,这些不使用的cuboid就可以不预计算。
检查Cuboid数量
Apache Kylin提供了一个简单的工具,检查Cube中哪些Cuboid最终被预计算了,称这些Cuboid为被物化的Cuboid,该工具还能给出每个Cuboid所占空间的估计值。由于该工具需要在对数据进行一定阶段的处理之后才能估算Cuboid的大小,因此一般来说只能在Cube构建完毕之后再使用该工具。
使用如下的命令行工具去检查这个Cube中的Cuboid状态:
bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader CUBE_NAME
# CUBE_NAME 想要查看的Cube的名字
示例:
bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader cube_order
============================================================================
Statistics of cube_order[20191011000000_20191015000000]
Cube statistics hll precision: 14
Total cuboids: 3
Total estimated rows: 20
Total estimated size(MB): 1.02996826171875E-4
Sampling percentage: 100
Mapper overlap ratio: 0.0
Mapper number: 0
Length of dimension ITCAST_KYLIN_DW.FACT_ORDER.DT is 1
Length of dimension ITCAST_KYLIN_DW.FACT_ORDER.USER_ID is 1
|---- Cuboid 11, est row: 12, est MB: 0
|---- Cuboid 01, est row: 4, est MB: 0, shrink: 33.33%
|---- Cuboid 10, est row: 4, est MB: 0, shrink: 33.33%
----------------------------------------------------------------------------
输出结果分析:
Cube statistics hll precision: 14
Total cuboids: 3
Total estimated rows: 20
Total estimated size(MB): 1.02996826171875E-4
Sampling percentage: 100
Mapper overlap ratio: 0.0
Mapper number: 0
- 估计Cuboid大小的精度(Hll Precision)
- 总共的Cuboid数量
- Segment的总行数估计
- Segment的大小估计,Segment的大小决定mapper、reducer的数量、数据分片数量等
|---- Cuboid 11, est row: 12, est MB: 0
|---- Cuboid 01, est row: 4, est MB: 0, shrink: 33.33%
|---- Cuboid 10, est row: 4, est MB: 0, shrink: 33.33%
- 所有的Cuboid及它的分析结果都以树状的形式打印了出来
- 在这棵树中,每个节点代表一个Cuboid,每个Cuboid都由一连串1或0的数字组成
- 数字串的长度等于有效维度的数量,从左到右的每个数字依次代表Rowkeys设置中的各个维度。如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度
- 除了最顶端的Cuboid之外,每个Cuboid都有一个父亲Cuboid,且都比父亲Cuboid少了一个“1”。其意义是这个Cuboid就是由它的父亲节点减少一个维度聚合而来的(上卷)
- 最顶端的Cuboid称为Base Cuboid,它直接由源数据计算而来。Base Cuboid中包含所有的维度,因此它的数字串中所有的数字均为1
- 每行Cuboid的输出中除了0和1的数字串以外,后面还有每个Cuboid的具体信息,包括该Cuboid行数的估计值、该Cuboid大小的估计值,以及这个Cuboid的行数与父亲节点的对比(Shrink值)
- 所有Cuboid行数的估计值之和应该等于Segment的行数估计值,所有Cuboid的大小估计值应该等于该Segment的大小估计值。每个Cuboid都是在它的父亲节点的基础上进一步聚合而成的
检查Cube大小
在Web GUI的Model页面选择一个READY状态的Cube,当我们把光标移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate)

一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因:
- Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多
- Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大
- 存在比较占用空间的度量,例如Count Distinct,因此需要在Cuboid的每一行中都为其保存一个较大度量数据,最坏的情况将会导致Cuboid中每一行都有数十KB,从而造成整个Cube的体积变大。
- Kylin的核心思想:空间换时间
对于Cube膨胀率居高不下的情况,管理员需要结合实际数据进行分析,优化。
使用衍生维度
示例:
- 有两张表 用户维度表(dim_user)、订单事实表(fact_order),要根据各个维度建立MOLAP立方体
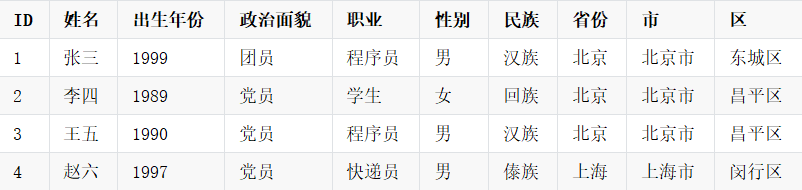
用户维度表(dim_user)
订单事实表(fact_order)

问题: - 生成Cube时,如果指定维度表中的:姓名、出生年份、政治面貌、职业、性别、民族、省份、市、区等维度生成Cube,这些维度相互组合,会造成较大的Cube膨胀率
使用衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
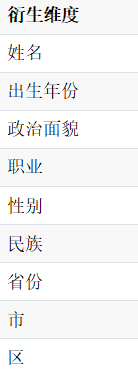
创建Cube的时候,这些维度如果指定为衍生维度,Kylin将会排除这些维度,而是使用维度表的主键来代替它们创建Cuboid。后续查询的时候,再基于主键的聚合结果,再进行一次聚合。 - 优化效果:维度表的N个维度组合成的cuboid个数会从2的N次方降为2。
不适用的场景:
-
如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,此时作为一个普通的维度聚合更合适,否则会影响Kylin的查询性能
-
第一种情况
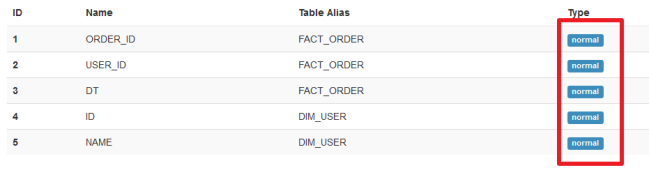
22222-1=31

-
第二种情况
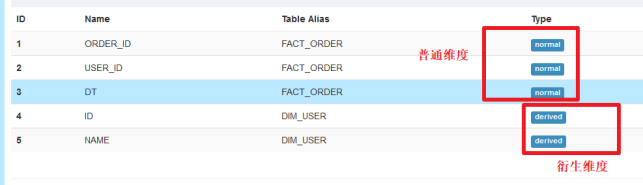
222-1=7

bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader
CUBE_NAME
- 第一种情况创建的cuboid数量会比第二种情况创建的cuboid数量多
所以使用衍生维度能够大量减少计算任务和空间的占用。
聚合组
- 聚合组(Aggregation Group)是一种更强大的剪枝工具
- 聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组
- 同一个组内的维度更可能同时被同一个查询用到,每个分组的维度集合均是Cube所有维度的一个子集
- 不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度
- 每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合
- 不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次

对于每个分组内部的维度,用户可以使用如下三种可选的方式定义它们之间的关系,具体如下:
强制维度(Mandatory)
- 如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。所有cuboid必须包含的维度,不会计算不包含强制维度的cuboid
- 每个分组中都可以有0个、1个或多个强制维度
- 如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度
- 适用场景
- 可以将确定在查询时一定会使用的维度设为强制维度。例如,时间维度。
- 优化效果
- 将一个维度设为强制维度,则cuboid个数直接减半
层级维度(Hierarchy)
- 每个层级包含两个或更多个维度
- 假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中,这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现
- 每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度
- 如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度
- 使用场景
- 年,月,日;国家,省份,城市这类具有层次关系的维度
- 优化效果
- 将N个维度设置为层次维度,则这N个维度组合成的cuboid个数会从2的N次方减少到N+1
联合维度(Joint)
- 每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现
- 每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度
- 适用场景
- 可以将确定在查询时一定会同时使用的几个维度设为一个联合维度
- 优化效果
- 将N个维度设置为联合维度,则这N个维度组合成的cuboid个数会从2的N次方减少到1

- 将N个维度设置为联合维度,则这N个维度组合成的cuboid个数会从2的N次方减少到1
示例:
- 对Cube膨胀率进行调优
准备: - 执行Kylin\kylin_Cube调优中的SQL脚本
- 导入Kylin中的数据
优化前:

优化后:

- 指定层级维度
