一、绪论
1.复杂度分析的主要方法
迭代:级数求和
递归:递归跟踪+递推方程
猜测+验证
2.级数的分类和计算:


最下面的调和级数和对数级数是后面要经常用到的
3.谈到空间复杂度时,除非有特别说明,我们都只考虑除了输入本身所需要的空间以外,我们另外申请的用于计算的空间
4.10^5sec≈1day
5.一个高效计算斐波那契数的算法:

这个方法就相当于在计算fib(i)时,经过一次循环后g存储fib(i),f存储fib(i-1)
6.渐进分析的几个符号:

总结起来就是,O是大于,Θ是介于,Ω是小于
二、向量(查找和排序)
查找:顺序查找,二分查找,斐波那契查找,插值查找
排序:冒泡排序
2.1知识点
1.递增扩容和成倍扩容相比,增加的时间成本就在于过于频繁地扩容,从而导致的频繁的复制原数组
2.复制数组时,不能用memcpy代替for循环+一个个地把数据复制到新数组里面,因为如果数组类型不是基本数据类型,那么memcpy只能进行浅复制
3.关于平均复杂度和分摊复杂度,前者偏向于概率,后者偏向于实际可行:

4.无序向量并不一定指向量里面的元素是无序的,有时候这个向量里面的元素甚至都无法进行排序
5.无序向量只要求元素可以判等,或已经重载操作腐“==”或“!=”;而有序向量的要求则高一点,还要求元素可以比较大小,而且元素确实是有序排列的
6.输入敏感算法:最好情况下的时间复杂度和最坏情况下的时间复杂度相差很大
7. T & Vector<T>::operator[](Rank r) { return _elem[r]; }中的返回值T&是什么意义?
这是类型T的引用,使用它是因为返回值可以作为左值
8.关于斐波那契查找为什么比二分查找在平均时间复杂度上更优,我记录一下我的理解:其实主要区别就是划分左右区间的长度不同,而且这个和算法也有很大的关系
先来看一下老师的代码:

可以看到,如果需要查找的元素在S[mi]的左边,那只需要一次关键码的比较便可;如果在关键码的右边,则需要先在if分支这里对关键码进行一次比较,然后在else if这个分支中和关键码进行一次比较,也就是进行两次关键码的比较。所以,在二分查找中,我们的左右区间长度相同,但是对关键码的比较次数却是不同的,所以我们可以让只需要进行一次比较的左区间尽可能长,需要进行两次比较的右区间尽可能短,这就是斐波那契查找所做的事情:

那至于这个左右区间的比例取多少才是最合适的呢?全部课件的合并版PDF的165+166页有求,答案是左区间取黄金分割率0.618时,性能最优
9.下面这个查找成功(蓝色节点)次数的计算方式:父节点的权值+路径的权值
查找失败(橙色节点)次数的计算:从根节点到橙色节点的路径权值之和

10.几个接口的语义
1)search(e):返回不大于e的最后一个元素;这样,有多个命中元素时,必须返回最靠后的元素的位置;失败时,应该返回小于e的最大者的位置,包括low-1
11.插值查找虽然能把查找效率从O(logn)下降到O(loglogn),但是其实这种下降带来的效果并不明显。插值查找比较擅长的是把区间快速缩减到一定的范围,所以综合起来应该是这样的:
1)先用插值查找快速缩小查找区间
2)再用二分查找进一步缩小区间
3)最后当数据项只有200~300时,使用顺序查找(为什么用顺序查找而不是效率更高的二分查找呢?我觉得老师的意思应该是二分查找相对顺序查找而言,多了一些加和除的步骤,所以实际运行可能更慢)
12.关于归并排序的复杂度计算:

计算过程:

13.冒泡排序有两种优化方式:
1)如果在某一次迭代中发现没有逆序对了,那就说明已经全部有序了,可终止
2)在某次遍历中,发现待排序部分的尾部已经有序了,那就不需要继续在这部分中找逆序对。这个优化可通过在每次迭代中,记录最后一次发生交换的位置来实现
14.归并排序有以下优化方式:
1)如果左子数组已经全部耗尽了,后面就不用管了,因为右子数组本来就是在母数组的右边的
2.2课后习题
三、列表
3.2 课后习题
1.对于n个节点的双向、单向列表,定位某节点p直接前驱的最坏时间复杂度分别为:O(1)和O(n)
解析:这个我觉得根据答案的意思就是,这个节点p是已经找到了的,现在我们要根据这个节点p和列表去找p的前驱节点,所以双向列表中可以直接通过p找到前驱节点,而单项列表要从列表头开始找
四、栈与队列
1.计算括号匹配时,有两种方法,1是栈,2是计数器,用栈的好处在于可以应用到多种类型的括号匹配题目里面去,计数器只能用于只有1种括号的情况,即使是多个计数器也无法实现多种括号同时存在的问题,比如([)]
2.像这样,我们用尖括号来表示栈顶,用方括号表示栈底:
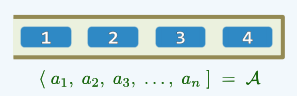
3.栈混洗与括号匹配的关系:我们把栈S的一次push操作视为左括号,一次pop操作视为右括号,那么可以发现刚好可以对应起来。n个元素构成的栈混洗有多少种,n对括号能够构成的合法表达式就有多少种(相当于一个元素对应一对括号)

4.所有操作数在中缀表达式和RPN表达式中的相对次序是一样的
五、二叉树
1.有根树:就是把某个顶点作为根的树
2.有序树:对某个分支节点的子树指定一种顺序,比如分支节点T有T1,T2,…,Tn棵子树,指定Ti为T的第i棵子树,这样,树就变成了有序树
3.任一节点与树根之间都存在唯一路径
4.在从根节点到节点v的路径path(v)中,path(v)上的所有结点均为v的祖先,包括v自己;除了v自身以外的其它祖先,称为v的真祖先
5.把树称为半线性结构,是因为对于任何一个结点而言,往上走,它任何一个层次的祖先都是唯一的;往下走,它的后代却是不唯一的。总之就是,在每个确定的层次中,结点的前缀(祖先)唯一,后缀(后代)不唯一
6.根节点是所有结点的公共祖先,深度为0
7.树的高度=该树叶子结点的最大深度。特别地,只有一个结点的树(退化树)的高度为0,空树的高度为-1。
8.同样的,求某个结点v的高度时,就看以它为根节点的子树中深度最大的叶子节点,这时候深度是从v开始算的,也就是这时候把v的深度当作0,开始计算子树的的深度
9.在以T为根节点的树中,任意一个节点v满足:
depth(v)+height(v)<=height(T),其中当v包含整棵树中深度最大的叶结点时取等号
10.真二叉树:节点的度只为0或2。我们在实践的时候,可以通过给普通二叉树补充一些假想的节点,来构造一棵真二叉树
11.左侧链:从当前子树的根节点开始,沿着左孩子链不断下行形成的序列,我们称为左侧链,比如下面这棵树中,以i为根节点的树的左侧链为i->d->c->a

12.尾递归:如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的
13.为什么普通二叉树中,只依靠前序+后序序列无法还原二叉树呢?因为只有这俩只能确定根节点,而无法界定左右子树的节点集合
六、图
1.所谓邻接关系,指的是点和点之间的关系,如果某两个点之间是有边的,那么就称这两个点邻接;
所谓关联关系,指的是这个点和以它为其中一个端点的边之间的关系,即点和边的关系
2.digraph:有向图
undigraph:无向图
3.所谓路径,就是由一系列的顶点按照依次邻接的关系构成的一个序列
4.简单路径:路径中不含重复的顶点
5.环路:就是起点和终点一致的路径
6.DAG(有向无环图):directed acyclic graph
7.欧拉环路
8.邻接矩阵(n个顶点):n×n矩阵
9.关联矩阵(n个顶点,e条边):n×e矩阵,而且每一列都只恰好有两个位置值为1,其余均为0
10.关于长子兄弟法的优点,结合老师的解答,我觉得首先是揭示了二叉树的普适性,然后是让树的表示更加简单,因为二叉树是要比多叉树简单好写的
11.邻接矩阵表示平面图(即在一个平面上可以把这个图画出来,而且不同边不会相交。通过欧拉公式可以知道这些平面图边数e<=3n-6=O(n))的空间效率是很低的,只有1/n
12.广度优先遍历的时间复杂度是O(n×n+e),但是实际上第二个n来自于while里面的那个for循环,而这个for循环进行的n次遍历所需要的操作不过是判断元素,这个操作带来的时间花销是很小的,因此可以视为常数,故真正的时间复杂度是O(n+e)
13.向前边:先访问的节点指向后访问的节点,相当于祖先指向后代;回边/后向边则刚好相反,后代指向祖先
14.用DFS遍历图时,求点c和点g的dtime和ftime:

错因:你从点b开始遍历到点d后,就直接返回到点c中了,实际上点b的邻居还没有遍历完,所以应该是转头去遍历点g
正确的表格:
错因:你从点b开始遍历到点d后,就直接返回到点c中了,实际上点b的邻居还没有遍历完,所以应该是转头去遍历点g
正确的表格:

15.用BFS遍历图时:

求点f的dtime。
你错于把队列里的点的遍历顺序搞混了,应该从点e开始遍历时你跑去从点b开始遍历了
七、二叉搜索树
1.循关键码搜索时,关键码需要同时支持大小比较和相等比对
2.我们讲节点、词条、关键码这3个概念等同起来
3.二叉搜索树处处满足顺序性,即每一节点的值均不小于/不大于其左/右后代节点的值;而全局上又满足单调不降性
4.二叉搜索树的单调性:BST的中序遍历序列,必然单调非降,同时这也是BST的充要条件
5.在二叉搜索树的查找算法中,每递归一次,就会下降一层,所以二叉搜索树查找算法的时间复杂度是O(h),其中h是树高
6.卡特兰数:
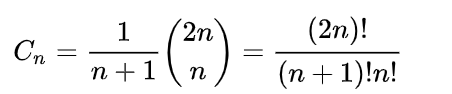
7.节点数目固定时,兄弟子树高度越接近(越平衡),全树也将倾向于更低
8.由n个节点组成的二叉树,高度不低于logn向下取整,恰为logn时,称作理想平衡。但是理想平衡出现的概率极低,维护成本也很高
9.高度渐进地不超过O(logn)时,即可把该树称为适度平衡。而适度平衡的BST,则称作平衡二叉搜索树(BBST)
10.等价的BST之间有这样的性质:
1)上下可变:联接关系不尽相同,承袭关系可能颠倒
2)左右不乱:中序遍历序列完全一致,全局单调非降
11.如

像上面这种顺时针的旋转变换,我们称为zig变换,下面的逆时针旋转,我们称为zag变换:

12.我们把一棵BST恢复成BBST时,需要满足两个点:
1)恢复操作的局部性,比如像11点中的旋转,它只局限在v、c两个节点中。这样就能保证变换的时间复杂度是O(1)
2)局部的顺序性,即保证在每个节点中,它的值都不小于左后代的值,不大于右后代的值
13.令一棵失衡的平衡二叉搜索树重新平衡的过程,叫重平衡(rebalance),这个过程依然需要保证O(logn)的复杂度
14.BST已经很优秀了,但是为什么还要提出更优秀的BBST呢?因为BST的最坏情况和平均情况都不能达到O(logn)以下
15.某个节点v的平衡因子balFac(v)=height(v->lc)-height(v->rc),即该节点左右子树的高度之差。如果一棵树的所有结点的平衡因子的绝对值均不超过1,那么这棵树就是一棵AVL树
16.AVL树的适度平衡:高度为h的AVL树,至少包含S(h)=fib(h+3)-1个节点,待证明的核心表达式是S(h)=1+S(h-1)+S(h-2)
17.stature(节点)表示该节点的高度
18.在AVL树中摘除一个节点,那么至多只有1个祖先会失衡,而且这个祖先恰好还是它的父亲节点。因为首先如果会失衡,那么说明肯定是左右子树的高度差拉大了,如果是两棵一样高的子树,那么随便摘除一个,高度差只是从0变成1,不会失衡;如果左子树高度比右子树高1个单位,那么如果是左子树被摘除了一个,则高度差从1变成0,不失衡;如果是右子树被摘除了一个,那么高度差变为2,但是父亲节点的高度仍然由左子树决定,所以父亲节点的高度没有变化,所以爷爷节点的左右子树高度之差自然也没有变化
19.在插入和删除这两种会导致AVL树失衡的操作中,插入操作相对要简便一些,而删除操作会比较麻烦
20.复衡的时候,插入操作的时间复杂度为O(1),因为只需要调整局部的子树就可以复衡;而删除操作的最坏时间复杂度为O(logn),因为局部复衡后,这种失衡会继续沿着祖先向上传播,最后就是每个祖先都要来一次复衡操作
21.实现删除操作时,是从被删除节点的父亲开始晚上走的,找各个失衡的节点进行旋转调整
22.由n个互异节点组成的二叉搜索树一共有:
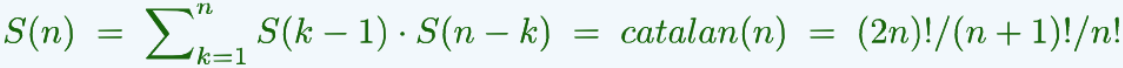
23.在AVL树中插入一个节点,复衡后树的高度不变;在AVL树中删除一个节点并复衡后,树的高度可能不变也可能减1.
插入的情况如下:

删除的情况如下:

红色表示这个节点可能存在,也可能不存在;存在时复衡后树的高度不变,不存在时复衡后树的高度减一
八、高级搜索树
1.局部性:刚被访问过的数据,极有可能很快地再次被访问
2.为什么不把内存做得更大一点?因为从物理层面来说,存储器的容量越大,那么访问它其中的数据也就越慢
3.关于存储器的两个特性:
1)访问一次内存的数量级是10^-9,访问一次磁盘的时间的数量级是10^-3,中间差了5个数量级以上,因此宁愿访问内存千次万次,也最好不要访问一次磁盘
2)从磁盘中读写1B数据,与读写1KB数据的耗时几乎是一样快的
4.在不同层次的存储单元之间进行IO操作时,一般是通过批量式访问呢来完成的,即以页或块为单位,使用缓冲区,比如C语言的这段例子:

5.虽然内存的实际容量在不断增加,但是相对于实际应用的数据存储而言,内存实际上是不断减小的