数据结构:内排序(C++)
一、插入排序
基本思想:
逐个处理待排序的记录。每个新记录与前面已排序的子序列进行比较,将它插入到子序列中正确的位置。
排序过程:
(1)输入一个记录数组A,存放着n条记录。
(2)先将数组中第1个记录看成是一个有序的子序列,然后从第2个记录开始,依次逐个进行处理(插入)将第i个记录X,依次与前面的第i-1个、第i-2个,…,第1个记录进行比较,每次比较时,如果X的值小,则交换,直至遇到一个小于或等于X的关键码,或者记录X已经被交换到数组的第一个位置,本次插入才完成。
(3)继续处理,直至最后一个记录插入完毕,整个数如中从元表将按关键码非递减有序排列。
伪代码描述:
template <class Elem, class Comp>
void inssort (Elem A[], int n)
{
for (int i=1; i<n; i++)
for (int j=i; (j>0) && (Comp::prior(A[j],A[j-1])); j--)
swap(A, j, j-1) ;
}
加入监视哨的插入排序伪代码描述:
template <class Elem, class Comp>
void inssort (Elem A[], int n)
{
for (int i=1; i<n; i++)
{
int value = A[i];
j = i-1;
while (Comp::prior(value, A[j]))
{
A[j+1] = A[j];
j--;
}
A[j+1] = value;
}
}
二、冒泡排序
基本思想:
比较并交换相邻元素对,直到所有元素都被放到正确的地方为止。
排序过程:
(1)输入一个记录数组A,存放着n条记录。
(2)每次都从数组的底部( 存放最后一个记录)开始,将第n-1个位置的值与第n-2个位置的值比较,若为逆序,则交换两个位置的值,然后,比较第n-2个位置和第n-3个位置的值,依次处理,直至第2个位置和第1个位置值的比较(交换)。
(3)重复这个过程n-1次,整个数组中的元素将按关键码非递减有序排列。
伪代码描述:
template <class Elem, class Comp>
void bubsort (Elem A[], int n)
{
for (int i=0; i<n-1; i++)
for (int j=n-1; j>i; j--)
if(Comp::prior(A[j], A[j-1]))
swap(A, j, j-1) ;
}
改进后的冒泡排序伪代码描述:
template <class Elem, class Comp>
void bubsort (Elem A[], int n)
{
bool flag;
for (int i=0; i<n-1; i++)
{
flag = false;
for (int j=n-1; j>i; j--)
if(Comp::prior(A[j], A[j-1]))
{
swap(A, j, j-1);
flag = true;
}
if(flag==flase) return;//发现已全部有序了
}
}
三、选择排序
基本思想:
第i次时“选择”序列中第i小的记录,并把该记录放到序列的第i个位置上。
排序过程:
(1)输入一个记录数组A,存放着n条记录。
(2)对于n个记录的数组,共进行n-1趟排序。
每一趟在n-i+1个(i=1,2, … n-1)记录中通过n-i次关键字的比较选出关键码最小的记录和第i个记录进行交换
(3)经过n-1趟,整个数组中的元素将按关键码非递减有序排列。
伪代码描述:
template <class Elem, class Comp>
void selsort (Elem A[], int n)
{
for (int i=0; i<n-1; i++)
{
int lowindex = i; // Remember its index
for (int j=n-1; j>i; j--) // Find least
if (Comp::prior(A[j], A[lowindex]))
lowindex= j; // Put it in place
swap(A, i, lowindex);
}
}
四、希尔排序
动机:
插入排序算法简单,在n值较小时,效率比较高;在n值很大时,若序列按关键码基本有序,效率依然较高,其时间效率可提高到O(n)。
基本思想:
先将整个待排记录序列分割成若千个较小的子序列,对子序列分别进行插入排序,然后把有序子序列组合起来;待整个序列中的记录“基本有序”时,再对全体记录进行一次插入排序。
排序过程:
(1)输入一个记录数组A,存放着n条记录以及一个(递
减)增量序列数组
(2)按照递减的次序,对于每一个增量,从数组的位置1开始,根据增量计算出子序列的最后一个值的位置,然后调用基于增量的插入排序函数;从数组的位置2开始,根据增量计算出子序列的最后一个值的位置,然后调用基于增量的插入排序函数;依次类推,计算出当前增量下的所有子序列,并排序。
(3)依法处理下一个增量,直至增量为1,执行一次标准的简单插入排序。
基于增量的插入排序过程:
(1)输入一个记录数组A,起始位置i,结束位置n,增量incr
(2)先将数组中第i位置的记录看成是一个有序的子序列,然后从第i+jincr位置的记录开始,依次对逐个增量位置进行处理(插入)将第i+jincr位置的记录X,依次与前面的第i+(j-1)*incr位置、第i+(j-2)*incr位 置,.,. 第i位 置的记录进行比较,每次比较时,如果X的值小,则交换,直至遇到一个小于或等于X的关键码,或者记录X已经被交换到第i位置,本次插入才完成。
(3)继续处理,直至最后一个记录插入完毕,整个子序列有序。
伪代码描述:
template <class Elem, class Comp>
void inssort2(Elem A[], int n, int incr)
{
//子序列插入排序
for (int i=incr; i<n; i+=incr)
for (int j=i; (j>=incr) && (Comp::prior(A[j], A[j-incrI]); j-=incr)
swap(A, j, j-incr);
}
template <class Elem, class Comp>
void shellsort(Elem A[], int n)
{
for (int i=n/2; i>2; i/=2) // For each incr
for (int j=0; j<i; j++) // Sort sublists
inssort2<E,Comp>(&A[j], n-j, i);
inssort2<E,Comp>(A, n, 1);
}
五、归并排序
动机:分治思想
基本思想:将两个或多个有序表归并成一个有序表
2路归并排序基本思想:
(1)设有n个待排记录,初始时将它们分为n个长度为1的有序子表;
(2)两两归并相邻有序子表,得到若千个长度2为的有序子表;
(3)重复(2) 直至得到一个长度为n的有序表。
排序过程:
归并排序(划分过程)用递归实现。
(1)若当前(未排序)序列的长度不大于1,则返回当前序列;
(2)否则,将当前未排序序列分割为大小相等的两个子序列,分别用归并排序对两个子序列进行排序,将返回的两个有序子序列合并成一个有序序列。
合并两个有序子序列的过程:
(1)记录数组A,起始位置left,结束位置right,中间点mid;
(2)首先将两个子序列复制到辅助数组中,
首先对辅助数组中两个子序列的第一条记录进行比较,并把较小的记录作为合并数组中的第一个记录,复制到原数组的第一个位置上;
继续使用这种方法,不断比较两个序列中未被处理的记录,并把结果较小的记录依次放到合并数组中,直到两个序列的全部记录处理完毕。
(3)注意要检查两个子序列中的一个被处理完,另一个未处理完的情况。只需依次复制未处理完的记录即可。
伪代码描述:
template <class Elem, class Comp>
void mergesort(E A[], Elem temp[], int left, int right)
{
if (left == right) return;
int mid = (left+right)/2;
mergesort<E,Comp>(A, temp, left, mid);
mergesort<E,Comp>(A, temp, mid+1, right);
for (int i=left; i<=right; i++) // Copy
temp[i] = A[i];
int i1 = left; int i2= mid+ 1;
for (int curr=left; curr<=right; curr++)
{
if(i1 == mid+1)
// Left exhausted
A[curr] = temp[i2++];
else if (i2 > right) // Right exhausted
A[curr] = temp[i1++];
else if (Comp::prior(temp[i1], temp[i2]))
A[curr] = temp[i1++];
else
A[curr]= temp[i2++];
}
}
优化归并排序算法伪代码描述:
template <class Elem, class Comp>
void mergesort(Elem A[], E temp[],int left, int right)
{
if (right-left) <= THRESHOLD)
{
inssort<E,Comp>(&A[left],right-left+1);
return;
}
int i, j, k, mid = (left+right)/2;
if (left == right) return;
mergesort<E,Comp>(A, temp, left, mid);
mergesort<E,Comp>(A, temp, mid+1, right);
for (i=mid; i>=left; i--) templil = A[i];//正序复制前半个表
for (i=1; j<=right-mid; j++)
temp[right-j+1] = A[j+mid];//逆序复制后半个表
for (i=left,j=right,k=left; k<=right; k++)// 从前后两半个表相向比较来复制较小值
if(temp[i] < templi)
A[k] = temp[i++];
else
A[k] = templ[j--];
}
六、快速排序
动机:
分治思想:划分交换排序
基本思想:
在待排序记录中选取一-个记录R(称为轴值pivot),通过一趟排序将其余待排记录分割(划分)成独立的两部分,比R小的记录放在R之前,比R大的记录放在R之后,然后分别对R前后两部分记录继续进行同样的划分交换排序,直至待排序序列长度等于1,这时整个序列有序。
排序过程:
快速排序(划分过程)用递归实现。
(1)若当前(未排序)序列的长度不大于1,则返回当前序列;
(2)否则在待排序记录中选取一个记录做为轴值,通过划分算法将其余待排记录划分成两部分,比R小的记录放在R之前,比R大的记录放在R之后;分别用快速排序对前后两个子序列进行排序(注意轴值已经在最终排序好的数组中的位置。无须继续处理)
选取轴值,划分序列的过程:
(1)记录数组A,待排子序列左、右两端的下标i和j;
(2)选取待排序子序列中间位置的记录为轴值,交换轴值和位置j的值,依据在位置j的轴值,将数组i-1到j之 间的待排序记录划分为两个部分(i到k-1之 间的记录比轴值小,k到j-1之间的记录比轴值大);
(3)从数组i-1到j之间的待排序序列两端向中间移动下标,必要时交换记录,直到两端的下标相遇为止(相遇的位置记为k),交换轴值和位置k的值。
伪代码描述:
template < class Elem, class Comp >
void qsort(Elem A[], int i, int j)
{
if(j <= i) return; // List too small
int pivotindex = findpivot(A, i, j);
swap(A, pivotindex, j); // Put pivot at end k will be first position on right side
int k = partition<E,Comp>(A,i-1, j, A[j]);
swap(A, k, j);
// Put pivot in place
qsort<E,Comp>(A, i, k-1);
qsort<E,Comp>(A, k+1, j);
}
template <class E1em>
int findpivot (E1em A[], int i, int j)
{
return (i+j) /2;
}
template < typename E, typename Comp >
inline int partition(E A[], int l, int r, E& pivot)
{
do
{
//Move the bounds inward until they meet
// Move l right and
while(Comp::prior (A[++l], pivot));
while((l < r) && Comp::prior(pivot, A[--r])); // r left
swap(A, l, r) ; //Swap out-of- place values
} while (l < r) ; // Stop when they cross
return l; //Return first position in right part
}
七、堆排序
动机:
选择排序:树形选择排序,最值堆
基本思想:
首先将数组转化为一个满足堆定义的序列。然后将堆顶的最值取出,再将剩下的数排成堆,再取堆顶数值,…,如此下去,直到堆为空,就可得到一个有序序列。
排序过程:
(1)建堆:将输入序列用数组存储,利用堆的构建函数将数组转化为一个满足堆定义的序列(如果是递增排序,则构建最大值堆,反之,构建最小值堆)
(2)然后将堆顶的最大元素取出,再将剩下的数排成堆,再取堆顶数值,…,如此下去,直到堆为空。每次应将堆顶的最大元素取出放到数组的最后。
(3)假设n个元素存于数组中的0到n-1位置上。把堆顶元素取出时,应该将它置于数组的第n-1个位置。这时堆中元素的数目为n-1个。再按照堆的定义重新排列堆,取出最大值并放入数组的第n-2个位置。到最后结束时,就排出了一个由小到大排列的数组。
伪代码描述:
template< Kclass Elem, class Comp>
void heapsort (Elem A[], int n)
{
Elem mval ;
maxheap KElem,Comp> H(A, n, n) ;
for (int i=0; i<n; i++) // Now sort
H. removemax (mval) ; // Put max at end
}
八、分配排序
动机:
分配:按关键码划分;不进行关键码比较。
基本思想:
关键码用来确定一个记录在排序中的最终位置。
伪代码描述:
for (i=0; i<n; i++)
B[A[i]] = A[i] ;
template <class E, class getkey>
void binsort(E A[], int n)
{
List<E> B[MaxKeyValue] ;
E item;
for (i=0; i<n; i++)
B[A[i]].append (getkey::A[i]));
for (i=0; i<MaxKeyValue; i++)
for (B[i].setStart() ;
B[i].getValue(item); B[i].next() )
output(item) ;
}
桶式排序(bucket sort):
分治法:
(1)将序列中的元素分配到一组(数量有限的)桶中;
(2)每个桶再分别排序(可以使用其它排序方法或递归使用桶式排序);
(3)最后,依序遍历每个桶,将所有元素有序放回序列。
九、基数排序
动机:
分配排序:按关键码划分;不进行关键码比较;而是一种多关键字的排序
基本思想:
将关键码看成有若千个关键字复合而成。然后对每个关键字进行分配(计数)排序依次重复,最终得到一个有序序列。
排序过程:
(1)将所有待排序数值(正整数)按照基数r统一为同样的数位长度,数位较短的数前面补零。
(2)然后,从最低位开始,依次进行每趟(计数分配)排序。定义一个长度为r的辅助数组cnt。记录每个盒子里有多少个元素。初始值为0。定义一个和原数组A一样大小的数组B。依次处理每个元素,根据元素的值计算其盒子编号,统计出每个盒子需要存放的记录数。(cnt[j]存储了数位j (第i个盒子)在这一趟排序时分配的记录数)
(3)利用cnt的值,计算该盒子在数组B中的( 最后一个)下标位置,从后向前,依次把数组A中的元素,依据该元素在cnt中记录的下标,把元素值存入(分配)数组B的(盒子中)相应位置将数组B的值依次复制到数组A,进行下一趟排序。
伪代码描述:
template <class E1em, class Comp>
void radix (Elem A[], Elem B[], int n, int k, int r, int cnt[]){
// cnt[i] stores # of records in bin[i]
int j;
for (int i=0,rtok= =1; i<k; i++, rtok*=r) {
for (j=0; j<r; j++) cnt[j] = 0;
// Count # of records for each bin
for(j=0; j<n; j++) cnt[(A[j]/rtok)%r]++;
// cnt[j] will be last slot of bin j .
for (j=1; j<r; j++)
cnt[j] = cnt[j-1] + cnt[j] ;
for (j=n-1; j>=0; j--)
B[--cnt[(A[j]/rtok)%r]] = A[j] ;
for (j=0; j<n; j++)
A[j] = B[j] ;
}
}
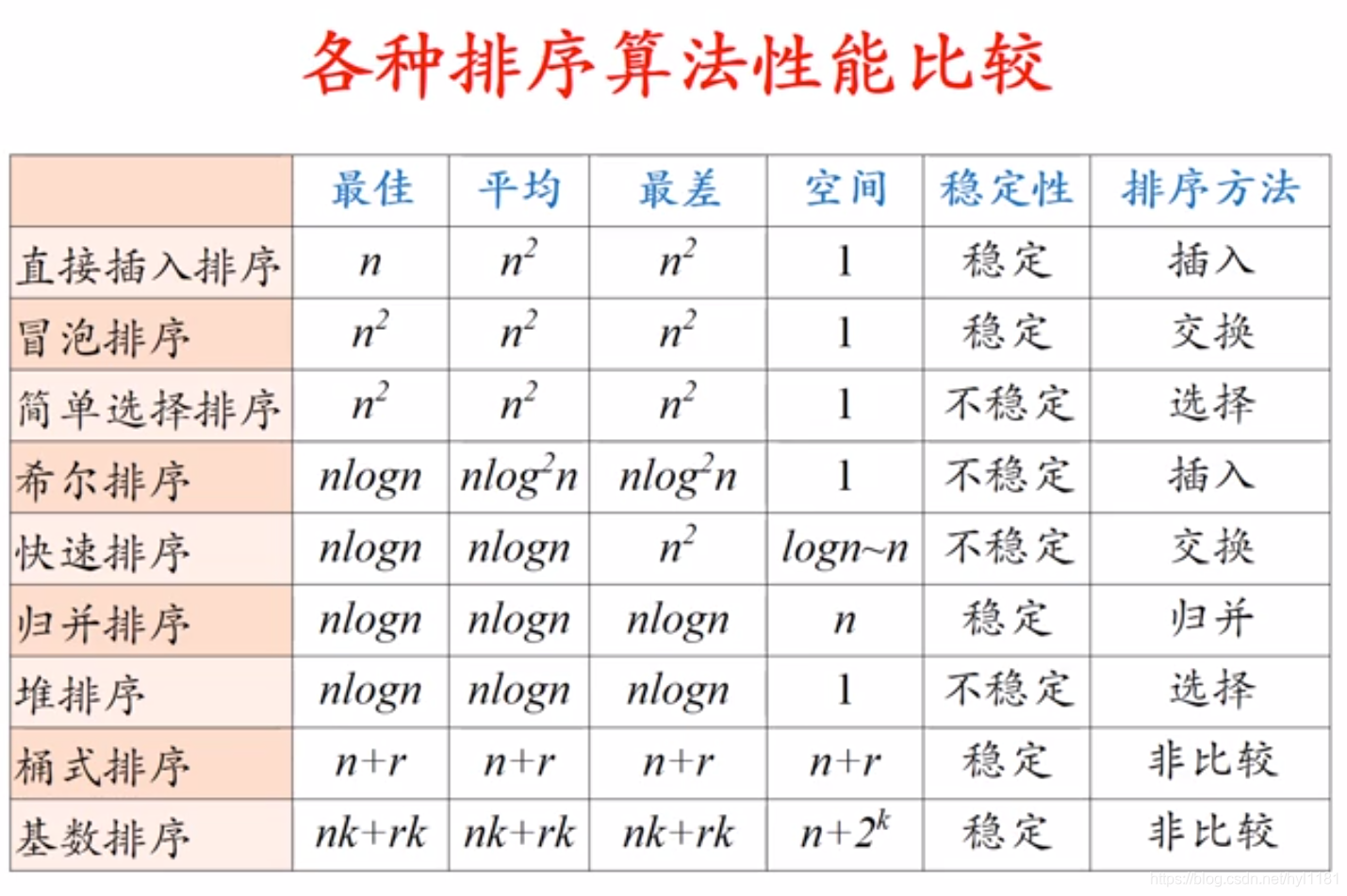
十、性能比较及总结
性能比较
总结
(1)简单排序以直接插入排序最简单,当序列“基本有序”或n较小时,它是最佳排序方法,通常用它与先进的排序方法结合使用。如果记录空间大,宜用移动次数较少的简单选择排序。
(2)平均时间性能快速排序最佳,但最坏情况下的时间性能不如堆排序和归并排序。
(3)基数排序最适合n很大而关键字较小的序列。
(4)从稳定性看,归并排序,基数排序插入排序和冒泡排序是稳定的;而选择排序、快速排序、堆排序和希尔排序是不稳定的。
(5)简单排序,堆排序和快速排序对内存占用小;而归并排序和各种分配排序需要辅助空间。