五、远程调用之二
本节讲三个方便远程调用的宏命令。
宏命令@everywhere
远程调用的一种特殊情况是要让声明/函数/表达式在所有进程中执行。例如:开启1个Worker,然后在每个进程(主进程+1个Worker)上声明一个变量beta并计算一个表达式beta+1。用之前讲的方法,可以写成:
julia> for pid = 1:2
r = @fetchfrom pid (beta=0;beta+1)
println(r)
end
1
1
其中用了println()来打印结果,因为REPL默认是打印最后一行的结果,而此例中最后一行是end,不会显示任何结果。特别提醒:远程调用多个表达式时要用括号,否则只会调用最后一个,导致beta未定义,就像这样:
julia> for pid = 1:2
r = @fetchfrom pid beta=0;beta+1
println(r)
end
ERROR: UndefVarError: beta not defined
能不能一步到位呢?有!这就是@everywhere。可以简写为:
julia> @everywhere (beta=0;beta+1)
它是一个表达式的广播,会把表达式在所有进程上执行。但它不会返回Future对象,看不到结果,所以一般用于广播声明,之后的表达式仍使用@fetch等“单体命令”远程调用以返回结果。当然,我们可以取巧一点,把一些不需要返回结果的、所有进程共有的表达式也用@everywhere广播出去,然后只对最后必须返回结果的表达式使用“单体命令”拿回结果即可。这样写起来会简洁点。
宏命令@eval
@eval命令用于对表达式做“值取代”,这里所谓的“值取代”意思是先对表达式求值然后用值取代表达式的位置。也可以在表达式中只对某一个变量做“值取代”,只需要在变量前加上$符号。由于这个命令的优先级很高,所以我们可以用它做一些骚操作,比如在Worker上使用本地变量:
julia> beta = 0;
julia> @eval @everywhere $beta+1
其中@eval比@everywhere更早生效,把beta取代为1,所以@everywhere不会报错。为了证明确实是@eval优先级更高,可以尝试:
julia> p = 0; @fetch @eval $p+1
1
# 或者
julia> p = 0; @everywhere @eval $p+1
可见@eval放在前后都一样。
作为对比,我们看一下报错的情况:
julia> kappa = 0; @everywhere kappa+1
ERROR: On worker 2:
UndefVarError: kappa not defined
注意这里不要用beta,因为上文已经把beta广播出去了,所以每个进程中已经有了beta的声明。
宏命令@distributed
再讲一个专门针对for循环的宏命令@distributed。它的用法是
@distributed (聚合函数) for var = range
表达式
end
若有多个表达式,则参与聚合的是最后一个表达式的值。聚合函数是一个可选参数,如果为空,则表示不聚合。例如:
julia> s = @distributed (+) for i = 1:10
2*i
3*i
end
165
可见它把最后一行的结果聚合了。如果不写聚合函数,那么返回的就不再是一个值了。在单台计算机上,@distributed会优先使用协程级并行,所以返回的是一个Task,如下:
julia> s = @distributed for i = 1:10
2*i
3*i
end
Task (queued) @0x00000000079d99f0
注意Task正处于排队中,因为它是在创建时立即返回的。不论写不写聚合函数,Julia的调度器总会自动安排它在合适的时间运行。我们可以随时查看它的执行情况:
julia> istaskdone(s)
true
至于怎样指定@distributed做进程级并行,以及在计算机集群上@distributed会不会优先使用进程级并行,书上没写清楚,有待测试。
六、远程引用
上述的所有远程调用都是基于跨进程的数据传递,即每个进程的数据都是互相隔离的,借助远程引用来实现合作。远程引用是一个对象,分为Future对象和RemoteChannel对象。前者是从一个Worker引用到主进程,后者是创建并存储在某个Worker上、对所有进程可见。
举个栗子来说明:
julia> c = Channel(2)
Channel{Any}(sz_max:2,sz_curr:0)
julia> @fetchfrom 2 put!(c,10)
10
julia> isready(c)
false
julia> @fetchfrom 2 isready(c)
true
这种远程引用是利用Future对象实现的。如图,在主进程创建的c(红色),作为远程调用的参数时,会在Worker上创建一个拷贝(绿色),执行表达式得到结果(蓝色),然后提取结果存入主进程的Future中(所以这个Future实际上与本地的c无关)。Worker上的操作只改变拷贝的状态而不影响主进程。
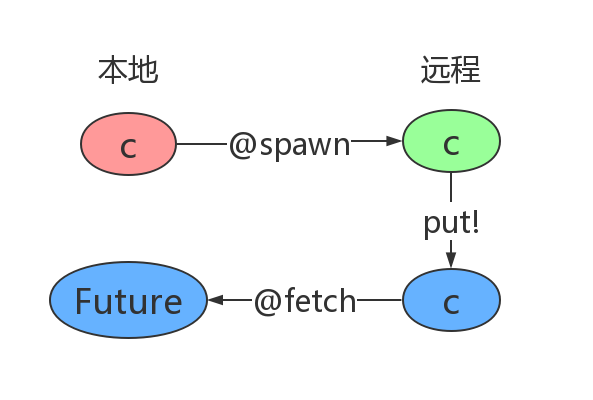
注意@fetchfrom提取的是表达式put!(c,10)的结果(蓝色),因此该结果(蓝色)会从Worker上移除,但c的拷贝(绿色)作为一个参数不会被移除,仍然存在于Worker上,所以可以在远程上继续操作它。
如果我们想在Worker对c进行操作的过程中,随时从主进程去修改Worker上的c,那么上述基于Future的远程引用就行不通了。为此,Julia提供了一个RemoteChannel,创建方法举例如下:
julia> f = ()->Channel{Int}(10)
#47 (generic function with 1 method)
julia> r = RemoteChannel(f,2)
RemoteChannel{Channel{Int64}}(2, 1, 45)
第一步声明一个函数f(参见匿名函数的语法),它必须返回一个Channel。第二步用RemoteChannel(f, 2)在PID=2的Worker上创建一个RemoteChannel,并具有与f返回的Channel相同的属性。当然这样写会造成主进程剩下一个多余的f,所以书中把两句写成了一句:
julia> r = RemoteChannel(()->Channel{Int}(10),2)
RemoteChannel{Channel{Int64}}(2, 1, 47)
r是这个RemoteChannel的句柄,位于主进程。我们可以通过操作r来实现对RemoteChannel的修改,好比是遥控无人机。例如isready(r),put!(r,100)等,也包括提取fetch(r)和take!(r)。而且,我们可以把它作为一个参数传递到任意一个Worker上,然后在那里操作,例如:
julia> @fetchfrom 3 put!(r,100)
RemoteChannel{Channel{Int64}}(2, 1, 47)
julia> take!(r)
100
julia> isready(r)
false
这里我们在PID=3的Worker上向r放入一个元素,然后在主进程提取,最后在主进程查看到r变空了,可见r是共享的。
如果创建RemoteChannel时不指定PID,则默认创建在主进程上。不论创建在哪儿,对句柄的操作都会导致数据在“操作的进程"和”创建的进程“之间传递。如果数据很大,这种传递就会耗费大量时间。下文介绍”共享数组“的概念,可以解决这个问题。