lxml同python的内置xml包一样,可以用来处理xml文件,但是相对于xml,lxml的处理速度更快,下面简单介绍一下lxml的用法
本次演示所采用的xml例子为如下所示:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/css" href="cd_catalog.css"?>
<CATALOG>
<CD id="001">
<TITLE>Empire Burlesque</TITLE>
<ARTIST>Bob Dylan</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>Columbia</COMPANY>
<PRICE>10.90</PRICE>
<YEAR>1985</YEAR>
</CD>
<CD id="002">
<TITLE>Hide your heart</TITLE>
<ARTIST>Bonnie Tyler</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>CBS Records</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1988</YEAR>
</CD>
</CATALOG>
我们以第一个元素CD为例,它是CATALOG的子节点,是TITLE的父节点,标签(tag)为CD,属性及属性值分别是id、001,而它的子节点TITLE,文本内容(text)为Empire Burlesque。以上就是xml文件中各个部分的称呼。下面我们看python代码:
#-*-coding:utf-8-*-
from lxml import etree#导入lxml库
tree = etree.parse("C:\\Users\\Administrator\\Desktop\\1.xml")#将xml解析为树结构
root = tree.getroot()#获得该树的树根
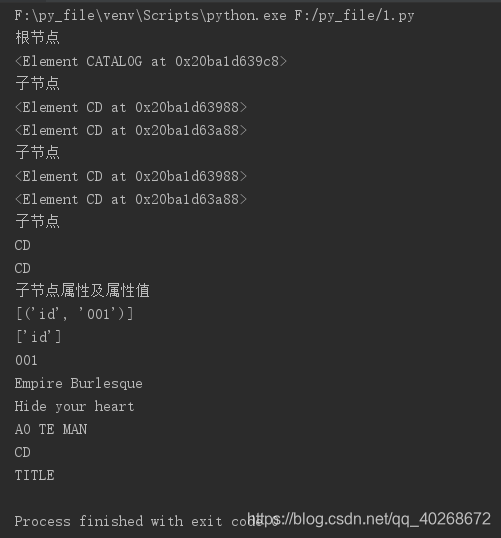
print("根节点")
print(root)
#访问子节点方式1
print("子节点")
for sub_node in root:
print(sub_node)
#访问子节点方式2
print("子节点")
for i in range(2):
print(root[i])
#访问子节点方式3
print("子节点")
for node in root.getchildren():
print(node.tag) #输出节点的标签名
#子节点
print("子节点属性及属性值")
print(root[0].items()) #获取全部属性和属性值
print(root[0].keys()) #获取全部属性
print(root[0].get('id', '')) #获取具体某个属性
#采用xpath
for node in root.xpath('//TITLE'):
print(node.text)
#添加一个CD节点
#cd = etree.SubElement(root, 'CD')
cd=etree.Element('CD')
cd.set('id','003')
title=etree.SubElement(cd,'TITLE') #创建CD的子节点TITLE
title.text="AO TE MAN"
root.append(cd) #将CD作为子节点加入root中
print(root[2][0].text)
print(root[2].tag)
print(root[2][0].tag)
cd3=root[2][0] #删除TITLE节点
root[2].remove(cd3)
tree = etree.ElementTree(root)
tree.write('test.xml', pretty_print=True, xml_declaration=True, encoding='utf-8')
上面包括了增(node.append(sub_node))、删(node.remove(sub_node)),访问标签(node.tag),访问文本(node.text),访问属性(node.keys())等等基本操作。运行结果如下