IntelliLight: a Reinforcement Learning Approach for Intelligent Traffic Light Control
introduction
这篇文章是来自KDD 2018的IntelliLight,这篇文章是宾州州立大学黎珍辉老师团队做的,这个团队最近几年在交通领域尤其是交通灯控制方面做了很多研究。

Zhenhui Li
传统的交通灯控制主要有这两类:定时信号控制和车辆驱动的控制方法。最近的研究尝试将强化学习应用于交通灯控制问题。
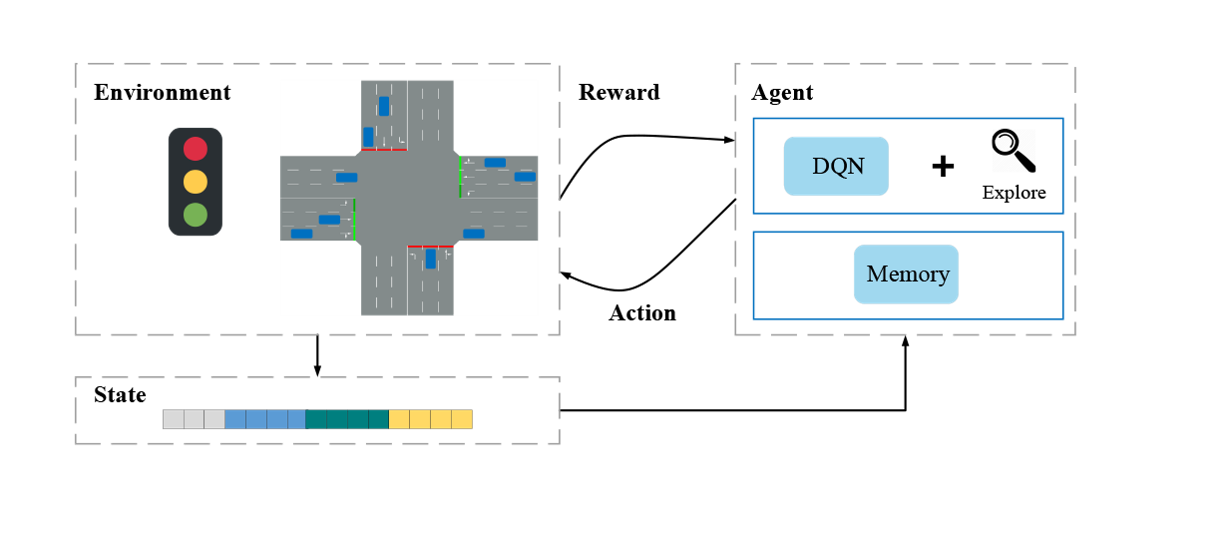
Deep reinforcement learning framework for traffic light control
与具体的交通灯控制问题相结合。环境由交通灯相位和交通状况组成,state是环境的特征表示。agent以state为输入,对灯光的控制作为action,比如改变交通灯的红绿灯阶段或者红绿灯时长等操作,然后agent会从环境得到一个reward,最直接的reward应该是车辆通过交叉口的总行驶时间但是这时间在每个时间步内无法直接计算,所以一般将reward设置为交叉路口的队列长度、车辆的等待时间、交叉口的吞吐量等。本文中的agent通过DQN网络来实现。agent根据DQN网络的损失函数更新模型以求奖励的最大化。
problem
首先,上面这些方法都假设相对静态的流量环境,与实际情况相距甚远,缺乏在真实数据上的检验。
而且,现有研究只求奖励的最大化而忽视了算法对实际流量的适应性,缺乏对策略结合实际情况的观察和理解。
第三个问题是交通灯的相位特征在很多算法中没有得到足够的重视,从而面对不同情况可能有相同的输出,但是输出结果并不符合实际需求。
下面通过两个小例子补充解释一下后两个问题。
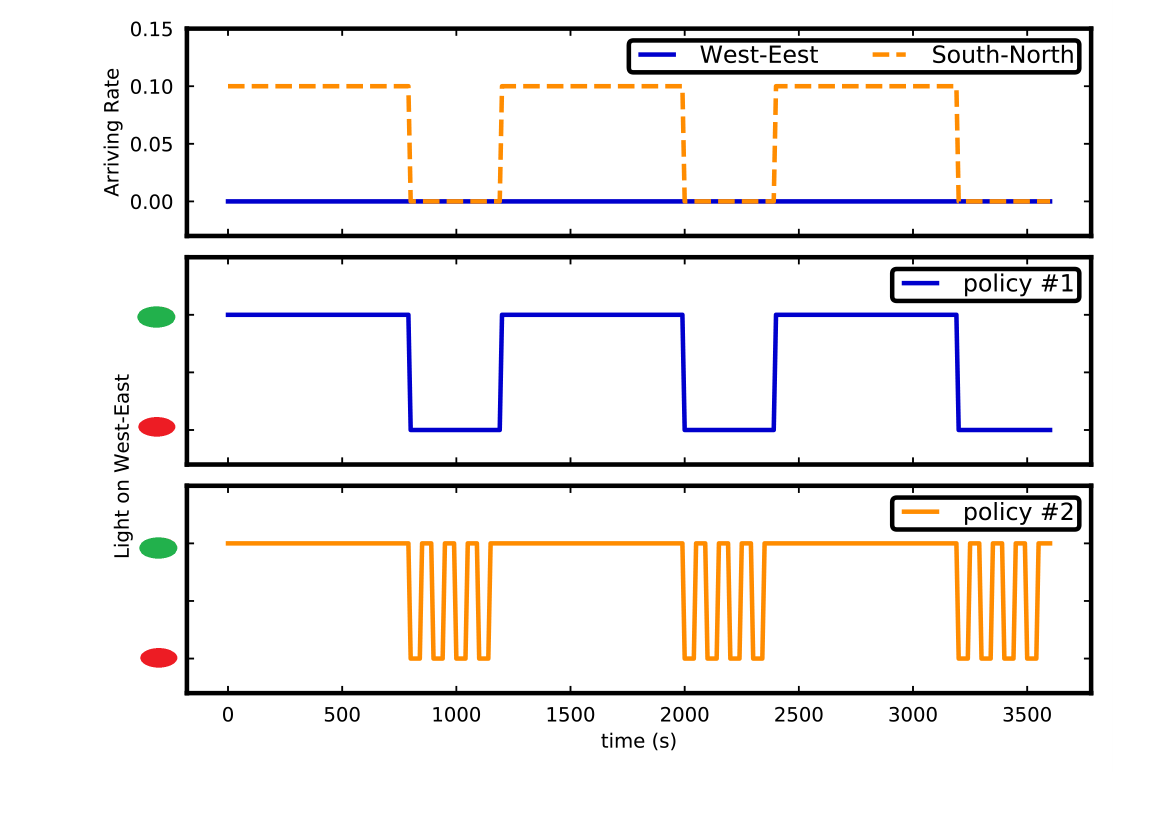
Reward is not a comprehensive measure to evaluate traffic light control performance. Both policies will lead to the same rewards. But policy #1 is more suitable than policy #2 in the real world
这个例子充分解释了不同的政策面对相同的情况虽然可以获得一样的奖励但是结合实际情况之后优劣显而易见。
最上面这张图是实际交通情况中的车辆到达率。蓝色实线是东西向的来车率,这个例子假设东西向没有来车,仅南北向有来车,每隔1200秒中前800秒以相同速率来车。下面两张图是两个不同的策略,显示的都是南北向的红绿灯时间。
策略1是每1200s南北方向先亮800s绿灯再亮400s红灯。策略2的不同之处在于后400s中不是连续的红灯而是每100s转换一次。
这两种政策在这个问题的环境中可以得到相同的奖励,因为都可以直接通过这个交叉口,但是在现实场景中显然策略1优于策略2。这就是这篇文章强调的不能仅关注奖励的最大化,要结合实际场景进行策略的分析和理解。

Case A and case B have the same environment except the traffic light phase
这个例子主要证明了交通灯相位信息的重要性在之前的算法中一直被低估了。
左右图交通状况相同,在左图状态下,agent倾向于维持当前红绿灯状态不改变,但是若如图右中这种情况,东西方向是红灯,那智能体应该做出调控,可见当前红绿灯的状态是会显著影响智能体选择策略的。如果仅将红绿灯状态作为输入特征的一维,那么它可能不足以影响Q值输出,导致模型无法拟合出有效的动作价值函数。
contributions
本文的主要贡献就在这三个方面。首先,在真实数据集上进行了算法的测试。并且这篇文章在不同情境(包括高峰时段、非高峰时段和工作日与周末等)在不同的情境下解释了策略的适应性。最后本文提出了一种新的相位敏感的强化学习agent,证明了它的优异性能。
model

Model framework
这是IntelliLight的整体模型。主要由离线和在线两部分组成。
左边的离线阶段是一个提前训练的过程,给定一个固定的交通灯信号时间表,让交通流通过红绿灯并采集数据训练模型,学习到一个基本的调控策略。在线阶段与环境进行交互对当前策略进行调整,在每个时间间隔∆t观察环境状态s并根据贪婪策略结合发现和探索做出行动a,发现是根据潜在回报选择可以使回报最大的动作,探索就是有一定的概率随机选择一个动作。然后代理会得到一个奖励r,元组(s, a, r, s')被放入记忆中存储。在一定数量的时间步之后,代理从记忆中抽取样本进行模型更新。
Agent
主要由三个部分组成:状态、动作和反馈。
state本文中选择的状态特征由五部分组成:车道上的队列长度、平均等待时间、当前红绿灯状态、等待车辆的数量以及使用卷积网络提取的十字路口状态特征。
action动作空间由两个动作构成,当a=0时保持当前交通灯相位,a=1时改变交通灯相位。相位分别为南北通行和东西同行,两个状态轮流切换。
reward奖励由六个部分组成:L是道路上的等待队列长度之和、W是道路上的平均等待时间、C是当前信号灯的action、D是车辆的推迟时间、N是通过交叉口的机动车数量、T是所有车辆的通过时间。以便从奖励中获得更丰富的信息,更容易的进行学习。

Q-network
当红绿灯路口处于不同状态时,智能体的动作做出相应的调整。phase gate 为每个不同的红绿灯状态创建独立的网络。红绿灯状态为0时,选择左半边网络进行输出,红绿灯状态为1时选择右半边网络进行输出。

Memory palace structure
Q-learning时off-policy算法,在deep Q-learning的算法中智能体将周期性的随机选取经验池中的交互数据来更新对Q值的估计。实验表明,在真实交通场景下,不同道路上的交通流量是不平衡的,若使用简单的经验回放,经验池会被频繁采用的红绿灯状态与调控动作的组合所占据,导致智能体对于频繁输入所对应的Q值有准确拟合,但却不够重视其他少量的输入,他们的Q值估计就可能会有很大偏差,从而导致调控不佳。
为了应对输入数据不平衡的问题,这篇文章为每个状态动作组合设置了独立的经验池。每次更新在各个训练池里选择相同的样本,从而改善了不平衡车流的问题,提高了网络估计Q值的精度。
experiment


实验中用SUMO模拟了一个双向六车道十字路口。交通灯只有两个状态:东西向绿灯或南北向绿灯。这两个表格展示了一些实验中的具体参数的设置。

baseline

several variations
三种传统的调控方式。FT表示固定时间间隔的调控方案。SOTL是使用了当前车流状态的基于手工规则的调控方案。QRL模型则是直接使用以图像为状态输入的deep Q-leaning算法。以及本文提出的IntelliLight模型的以及它的两种变体。


这篇文章分别在四个人工数据集和一个真实的数据集上进行了详尽的测试。


这篇文章提出的phase gate 网络结构和多个经验池的训练机制有效提升了IntelliLight的测试表现,并且超越了传统调度方案,改善了车辆通行的效率。

Traffic surveillance cameras in Jinan, China
真实数据集是2016年8月份在济南采集到的24个交叉路口的交通数据。由1704个摄像头在935个交通路口收集的,图片上是参与数据采集的摄像头位置。该数据集由4亿多条数据集构成,因此很好的反应了真实世界的交通状况。很好的实现了将强化学习实现的红绿灯调度落地到真实的道路数据中。
 表格中的实验结果表明IntelliLight在真实环境中比模拟环境下更好的超越了传统方法的表现。这反映出强化学习能够更好的应对复杂多变的真实环境。最终IntelliLigh在各个指标项中相比于最优的传统交通策略贡献了约20%-30%的提升。证明了用强化学习进行交通灯调度在真实场景下的优越性。
表格中的实验结果表明IntelliLight在真实环境中比模拟环境下更好的超越了传统方法的表现。这反映出强化学习能够更好的应对复杂多变的真实环境。最终IntelliLigh在各个指标项中相比于最优的传统交通策略贡献了约20%-30%的提升。证明了用强化学习进行交通灯调度在真实场景下的优越性。
observations with respect to real traffic
-
我们先看左边的两张图。图a显示了周一当天的交通情况。这一天中大部分时间东西向来车都比南北向来车多。理想的交通灯控制策略应该为东西方向提供更长的绿灯时间。从图c中可以看出东西向绿灯持续时间的比例通常大于0.5。这意味着本文策略为绿灯分配的持续时间更长。在三个高峰时间段,绿灯时间所占的比例也明显更高。清晨南北向的来车率更大,本文的策略也能给南北方向更多的绿灯时间。说明本文的方法能够很好的处理高峰时段与非高峰时段的红绿灯控制。
-
如图b与周一比,周日的交通流量表现出不同的模式,图d的红绿灯控制也相应的给出了不同策略。对比左右两边的图片可以发现,第二行的图片显示周末白天东西向的绿灯时间明显比工作日减少了,因为根据第一行两行图片可以看出周末白天的南北向来车率比东西向大。说明本文的方法能够智能的根据周内与周末的不同交通流量状况给出合理的交通灯控制策略。
-
在没有对主干道的先验知识的情况下,IntelliLight方法更倾向于给主干道绿灯。在图a中可以看出东西向的道路为主干道,交通量大。
conclusion
phase gate和memory palace的提出和配合使用效果很好,并且算法准确性的有效提高在真实数据集上得到了验证,得到的策略对不同情况下的车流量有适应性调整。
更多相关精彩内容,关注公众号图与交通。
