一.分组查询:annotate
# 统计每个出版社出版书籍的平均价格
from django.db.models import Avg,Max,F,Q
obj = models.Book.objects.values('publishs_id').annotate(a=Avg('price')).values('a')
print(obj) #values中是分组依据,后面是分组结果的统计,统计你需要什么
obj = models.Publish.objects.annotate(a=Avg('book__price')).values('a')
print(obj) #以Publish每一条记录作为分组依据,后面是分组之后要统计的结果
二.F查询
# F查询:自己这张表中字段比较
# 点赞数大于评论数的
obj = models.Book.objects.filter(good__gt=F('comment'))
print(obj)
# 批量修改数据 让书籍表中的所有书的价格都加上20
models.Book.objects.all().update(price=F('price')+20)
# 注意:如果values里面有多个字段的情况: #是按照values里面的两个字段进行分组,两个字段同时相同才算是一组
obj = models.Author.objects.values('name','age').annotate(a=Count('nid'),b=Max('age'))
print(obj)
三.Q查询
# 评论数大于80,并且点赞数大于80的
obj = models.Book.objects.filter(Q(comment__gt=80) & Q(good__gt=80))
print(obj)
# 评论数大于80或者点赞数大于80的
obj = models.Book.objects.filter(Q(comment__gt=80) | Q(good__gte=80))
print(obj)
# Q:| & ~
# 评论数大于80或者点赞数小于等于80的
obj = models.Book.objects.filter(Q(comment__gt=80) | Q(good__lte=80))
print(obj)
# 评论数小于等于80并且点赞数小于等于80的
obj = models.Book.objects.filter(~Q(comment__gte=80) & Q(good__lte=80))
print(obj)
# 并且的另一种写法 逗号连接的普通关键字 要放到Q查询的后面
# 评论数小于等于80并且点赞数小于等于80的
obj = models.Book.objects.filter(~Q(comment__gte=80),good__lte=80)
print(obj)
# 优先级的关系 and优先级高
# 评论数大于80或者点赞数小于等于80的 且价格等于44的
obj = models.Book.objects.filter(Q(comment__gt=80) | Q(good__lte=80) & Q(price=44))
print(obj)
# 想让or的优先级高就再用一个Q括起来
obj = models.Book.objects.filter(Q(Q(comment__gt=80) | Q(good__lte=80)) & Q(price=44))
print(obj)
四.查询练习题
# 1 查询每个作者的姓名以及出版的书的最高价格
obj = models.Author.objects.annotate(a=Max('book__price')).values('a')
print(obj)
# 2 查询作者id大于2的姓名以及出版的书的最高价格
obj = models.Author.objects.filter(nid__gt=2).annotate(a=Max('book__price')).values('name','a')
print(obj)
# 3 查询作者id大于2或者作者年龄大于等于20岁的女作者的姓名以及出版的书的最高价格
obj = models.Author.objects.filter(Q(nid__gt=6) | Q(Q(age__lt=20) & Q(sex='female'))).annotate(
a=Max('book__price')).values('name','a')
print(obj)
# 4 查询每个作者出版的书的最高价格 的平均值
obj = models.Author.objects.annotate(a=Avg('book__price')).values('a').aggregate(b=Avg('a'))
obj = models.Author.objects.annotate(a=Avg('book__price')).aggregate(b=Avg('a'))
print(obj)
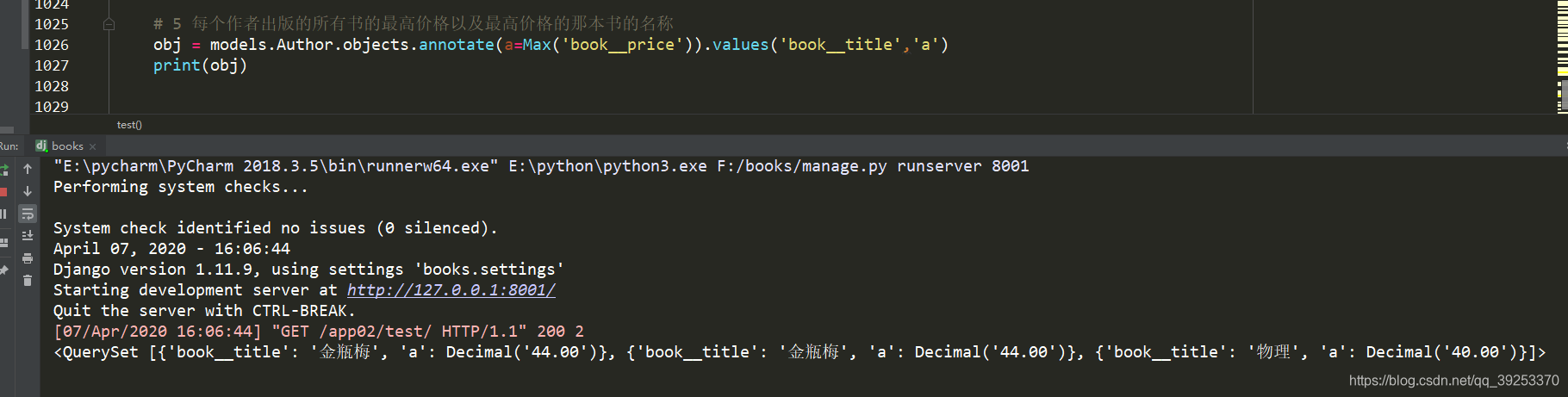
# 5 每个作者出版的所有书的最高价格以及最高价格的那本书的名称
obj = models.Author.objects.annotate(a=Max('book__price')).values('a','book__title')
print(obj)
# 6 查询每个作者出版的书的最高价格
obj = models.Author.objects.annotate(a=Max('book__price')).values('a')
print(obj)
四.ORM执行原生sql语句
# orm执行原生sql语句
obj = models.Book.objects.raw('select * from app02_book')
print(obj) #RawQuerySet
for i in obj:
print(i.title)
#可以查询其他表的数据
obj = models.Publish.objects.raw('select * from app02_book;')
for i in obj:
print(i.title)
五.django外部脚本使用models
import os
if __name__ == '__main__':
#使用Django环境 设置了一个键值对 值就是我们项目的住配置文件
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "books.settings")
import django
django.setup() #运行Django环境
from app02 import models
obj = models.Book.objects.all()
print(obj)
六.ORM分组的坑(重要)
书籍表:

第三张表:
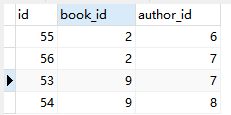

结果为什么有两个物理?
<QuerySet [{‘book__title’: ‘金瓶梅’, ‘a’: Decimal(‘44.00’)}, {‘book__title’: ‘物理’, ‘a’: Decimal(‘44.00’)}, {‘book__title’: ‘物理’, ‘a’: Decimal(‘40.00’)}]>
解释:
我们是用*号去查询的,他只会拿第一条记录中的价格,但是其他字段他不管,这就会导致书名拿错,实际上我们是拿到【金瓶梅】这本书才对
解决办法:
需要在mysql中配置一下:sql_mode=only_full_group_by这样分组的时候就要指定对应字段去分组,不能直接select * from
全局配置:
set global sql_mode=‘STRICT_TRANS_TABLES,ONLY_FULL_GROUP_BY’;
配置文件配置:
默认安装位置:C:\ProgramData\MySQL\MySQL Server 8.0\my.ini
修改my.ini配置文件:

配置好之后再运行我们的sql语句看下结果:
原生sql解决:
加sql_mode:
#sql_mode='only_full_group_by'
select id,name,price,title from (
SELECT #不能select * from 这里写的字段必须是分组后面的字段 也可以是聚合结果
app02_author.nid,
app02_author.`name`,
max(app02_book.price) as m
FROM
app02_author
INNER JOIN app02_book_authors ON app02_author.nid = app02_book_authors.author_id
INNER JOIN app02_book ON app02_book_authors.book_id = app02_book.nid
GROUP BY
app02_author.nid,
app02_author.`name`
) AS t1
INNER JOIN app02_book_authors ON t1.nid = app02_book_authors.author_id
INNER JOIN app02_book ON app02_book.nid = app02_book_authors.book_id
WHERE t1.m=app02_book.price
sql解释:t1表中的最大价格等于app02_book中的价格
#sql_mode!='only_full_group_by' 不加sql_mode
SELECT
*
FROM
(
SELECT
app02_author.nid,
app02_book.title,
app02_book.price
FROM
app02_author
INNER JOIN app02_book_authors ON app02_author.nid = app02_book_authors.author_id
INNER JOIN app02_book ON app02_book_authors.book_id = app02_book.nid
ORDER BY
app02_book.price DESC
) AS b
GROUP BY
nid;