Python——Django框架(五)
参考博文:https://www.cnblogs.com/yuanchenqi/articles/6083427.html
ORM多表操作之多对多
一、多对多添加记录
1、添加多对多关系
继续前面的。多一个作者(Author)表,一本书可以有多个作者,一个作者可以有多本书,这就是多对多的关系。
首先要知道,两张表是完成不了多对多的关系的。
那么多对多怎么实现呢?有个很通俗的单词:ManyToMany:

我这作者的表已经创建过了,接着如果想要再加一个字段:

也就是想要再加一个age字段,就会出现这种去情况:

系统不知道你新加的这个 age 应该赋予什么值,所以我们可以给它一个null:

接着输入代码创建表,这时就会发现,除了原本的三张表(Book,publish,author),还多了一张表:

这个ManyToMany就会自动帮你创建第三张表。
现在表已经创建好了,就要绑定多对多的关系了。

上面的数字,是手动填上去的。我们能不能通过ORM来给这张表添加信息呢?当然不行!!
现在是通过编辑器来直接对这张表操作的,但是如果回到用ORM来赋值,你会发现根本没有相关的代码。
所以我们只能通过对象的方式来绑定关系。
那么我们该怎么绑定呢?看下图:

解释:首先要先取出这本书的对象,然后如果想要为这本书添加作者,就通过 add() 的方式来添加,当然,我们应该要先取出作者的信息:

这里取出的是所有作者的信息,取出的是一个集合,所以下面add增加操作那里,要加个星号 * 。当然,如果取出的只有一个,就不用 * 了。看下图:

这时候,就可以发现,多对多的绑定关系出来了:

继续前面的,如果添加多个作者信息,就会这样:
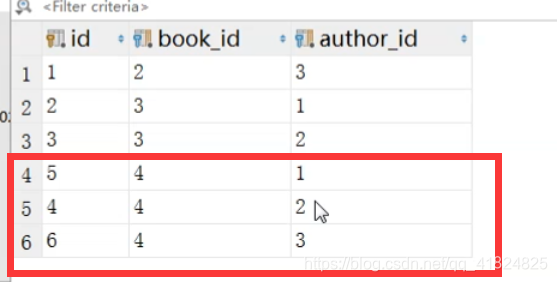
三个作者都对应了一本书了。
2、删除多对多关系
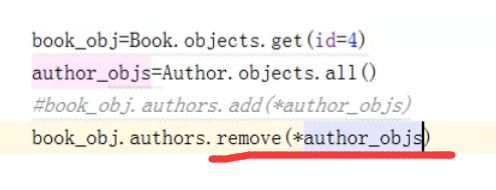
这样,就解除了绑定的多对多的关系:

可以看到,成功解除了多对多的关系。
当然,还有相对简便的方法:
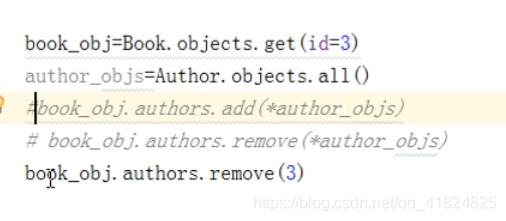
这个操作意思是:把 id=3 的书,删除 id=3 的作者的多对多关系。如果删除不存在的 id ,也不会报错。
3、通过直接操作来赋予多对多关系(不推荐)
注意:

这里把那个 ManyToMany 的字段删了,然后输入相关代码 (… migrate),系统会自动把这个字段相关联的数据给删掉。
前面都是通过对象的方式来赋予多对多关系。如果我们就是要直接操作来赋予多对多关系,那该怎么做呢?
答案是可以的。前面我们是通过ManyToMany 来让数据库自动帮我们创建第三张表。如果我们手动创建第三张表,就可以实现通过直接操作来赋予多对多关系。
记得前面讲过,实质上是没有多对多的关系的,是通过两张表的一对多,来实现多对多的关系。

两个都是外键!
创建外键,系统会自动帮我们在后面加上 _id。
然后创建表:
接着我们就开始赋予多对多关系:

解释:绑定书id为2,作者id为3,的多对多关系。
可以看到,创建成功:

二、多对多查询(接上)
然后开始关联查询:
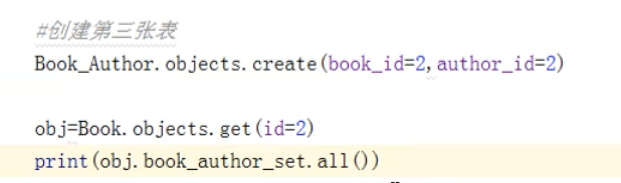

可以看到,取出来了对象集合。接着取第一个对象,看它的信息:


可以看到,作者的信息出来了。
可以发现,这种操作跟一对多的差不多。学到这里,就可以忘记这种操作了,因为后面主要不是通过这种操作来赋予关系,主要是通过filter,双下划线等等的方式。但是这里要知道怎么回事,有这么一个方法,就行了。
还没结束,我们尝试查询 alex出过的书籍名称及价格:


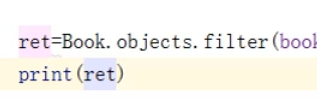

可以看到,能查出来,但是因为这表是我们手动创建出来的,所以这么查起来比较麻烦,如果是ManyToMany,会轻松很多。
如果是ManyToMany,看下图:

可以看到,最终是可以查到的(中间的数据改过,但重要的是能查出来):

三、查询之聚合查询,分组查询
1、聚合查询
如果你想要例如 sub ,min 之类的函数,要先导入:

来个需求:现在想要所有书的平均价格,怎么求?看下图:

然后结果:

如果是求和呢?

结果:

再来个需求,求 alex出过的书的总价格:
首先要筛选条件,接着再求和:
 结果:
结果:
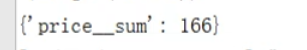
可以看到 这个 ‘price__sum’ 是系统自动帮我们做拼接的,我们也可以自己命名:

结果:

2、分组查询
顾名思义,我们可以根据某个条件来分组,这里用名字举例:

先筛选作者姓名,再根据这个来分组:

解释:此操作意思是每一个作者出过的书的总价格是多少。
结果:

再来个需求,每一个出版社所出过最便宜的书的价格:
 结果:
结果:

四、多表操作之F查询与Q查询
仅仅靠单一的关键字查询已经很难满足查询的要求。此时Django为我们提供了F查询和Q查询。
如果要使用F、Q查询,首先要引入它们:

1、 F查询
来个需求:如果此时想要所有书的价格都提价10块钱,该怎么做?尝试下:

可以看到,这种方式是不行的。
所以此时我们需要F、Q的帮助

可以看到,这样子就没问题了。结果也确实都加了10块钱。
2、Q查询
a、
我们能做到“与”查询,但是“非”跟“或”做不到。所以这时就需要Q查询来帮助:

通过Q包起来,就可以使用管道符 “ | ” ,来完成或操作。
通过Q包起来,就可以在Q前面加波浪线 “ ~ ” ,来完成非操作。
举例子:

输出价格为87或者名字为GO的书:

输出名字不是GO的书:


b、模糊查询
如果要查找书的名字里带有G的,该怎么做呢?看下图:


3、F、Q查询与关键字查询组合使用
例子:

结果:

注意:如果要组合查询,F或Q查询,一定要放在关键字查询前面!
五、QuerySet集合对象的特性
QuerySet特点:
1、可迭代的
2、可切片
1、惰性求值
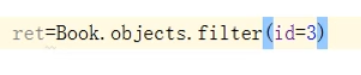
当执行了上面这么一段代码的时候,数据库有没有查询?
答案是没有。
这个现象,是 querySet 造成的。这种现象称为“惰性求值”。
当你需要用到的时候,才会执行,否则不会执行。为什么要这么设计呢?
因为到数据库查询需要时间;如果你现在不用,后面再用,这样子就会浪费时间。
只要你用到,就会执行,比如:

比如这种。
注意:
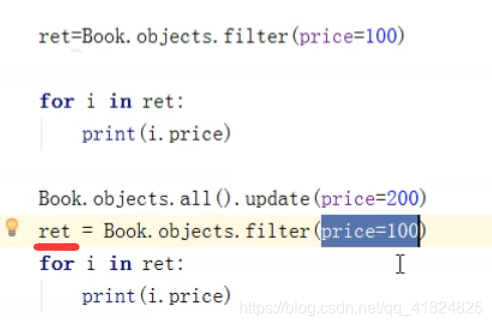
但是,这种情况就不一定了:

两个 for 循环,虽然看起来是执行了两次,但实质上只执行了一次!
Django给 querySet 做了一个缓存,第一次遍历的时候,会存进缓存,第二次再用到的时候,就不会到数据库拿,而是进缓存里拿。这种情况,也能提升性能。
我们可以验证一下:

结果:

结论:确实是没有到数据库里拿,而是进到了缓存里。这就是利弊关系了。
但是真的没有办法吗?
很简单,你重新赋值就行了!
2、关于exists与节省缓存
现在有这么个需求,我只要看下QuerySet里面有没有数据,但是不要它存到缓存里:
xxx.exists()
看下图:

这么写,虽然还是会走数据库,但是不会把里面的数据存到缓存里面。
3、QuerySet与迭代器和生成器
如果数据很多,一下放到缓存里,对缓存也是个很大的消耗,我们可以用到以前学过的迭代器与生成器,一条一条放到缓存里,用到的时候才拿。
首先就要先做一个迭代器:
通过 iterator():

迭代器的特点:只能遍历一次,遍历完就没有了,比如下图的两个for循环:

只能输出一次,第二次已经没有了,所以输出不出来。
总结:
