之前一直在写程序,了解到运行程序的两个步骤:编译,运行。在Microsoft visual C++中编译和运行是分开的两部分。在DEV C++中集成为一个按键。在之前的印象中,编译就是寻找语法错误的过程。只要程序语法有错误,程序就无法通过编译。并会提示相应的信息,告诉写程序的人去哪里修改什么类型的错误。这学期开始,开设了编译原理课程。按照之前的习惯,通过写博客,及时梳理自己的思路并希望能在某些方面有所提高。下面开始吧!
学东西先问自己几个问题:什么是编译原理?为什么需要编译原理?怎么才能实现编译原理?
刚开始学习,对编译原理的理解不是那么深刻。简单谈一谈自己的看法。如果后续学习过程中发现自己理解有误,也会及时修改。
为什么需要编译原理?
了解计算机的人都知道对于计算机来说,它所能识别的只是机器代码。就是我们常说的0,1串。但对于编写程序的人来说,如果利用机器语言编写程序,那过程必将是痛苦且低效的。程序员为了让生活对自己好点,慢慢的开发出了高级语言,如C,C++,python等等。抽象来看,输入是高级语言,输出是机器语言,那中间的转化器就是编译器,其原理就是编译原理。现在知道为什么需要编译原理了吧!它是我们和计算机更好沟通的桥梁。
什么是编译器?
由之前的问题了解到,编译器的作用是把高级语言转换成低级语言(机器语言)。其实这简单的解释了编译器的定义。运用编译原理编写的程序,并能起到编译作用的程序叫做编译程序。把编译程序做一个推广:翻译程序。翻译程序的定义是:把某一种语言程序(称为源语言程序)转换成另一种语言程序(称为目标语言程序),而两种程序在逻辑上等价。对翻译程序的源语言(高级语言)和目标语言(机器语言)加以限制就成为了编译程序。
怎么才能实现编译原理?
问题有点抽象。转换的直接一点:编译程序怎么写?编写程序自然有它的步骤,下面会陆续介绍到编译过程的五大步骤。只有了解编译过程,才能对应去写如何实现这些编译过程的代码。
回答完刚才的问题,想必对编译原理和编译程序有了少许的了解。下面开始进入正文:通过本篇文章,想解释明白下面几个问题:
1.编译程序的五大步骤及各步骤的主要工作
2.有关编译程序的几个名词解释,包括:表格管理、出错处理、遍、编译前端/后端
3.编译程序的生成,自展和移植。
注意:因为作者对C语言比较熟悉,所以编译程序的举例都以C语言作为基准。
一、编译程序的五大步骤及各步骤的主要工作
先对五大步骤做一个说明,再详细介绍各个步骤:
1) 词法分析
2) 语法分析
3) 语义分析及中间代码生成
4) 优化
5) 目标代码生成
它们的顺序其实已经说明其关系,但为了便于理解,这里附上一张关系图:
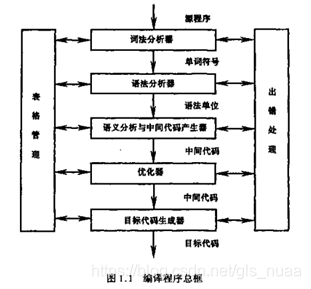
下面对各个步骤进行详细说明:
1) 词法分析
词法分析就是从头到尾扫描,识别出语法单元,并查看是否存在词法错误。那什么是词法错误呢?举个例子:在部分编程语言中,要求变量名只能由下划线或字母打头而不能使用数字。比如在C语言中的int 3a;就一个不合法的声明,这种错误会在词法分析是被检测出来。再举一个例子,作为编程新手常犯的错误:总是把英文的;写成中文的;这个在编译过程中都会报错,错误的阶段属于词法分析。
在词法分析的过程中不止会寻找错误,也会对正确的词进行一个分类。包括以下几个类别:
1. 基本字(保留字):主要指语言中已经定义好的那些字符,例如:int double typedef return等等
2. 标识符:主要指在程序中定义的变量名。如int a;/double b;中a,b就属于标识符
3. 界符:界符用于分隔程序,常见的界符有; { } 等
4. 算符:主要指进行运算的字符,运算包括数值运算和逻辑运算。例如:+,-,*,/和&,|;
5. 赋值符:完成的功能就是赋值,例如:=,+=,-=等
举个例子,说明词法分析干的事情:

2) 语法分析
语法分析主要作用是根据语法规则识别语法单位并分析语句中有没有语法错误(这句话听起来很抽象,啥算语法错误?)识别语法错误,就像a=+c其实本来应该是a=b+c,b没有写,对于词法分析过程只认定出是两个连续的算符。对于加号的语法是左右都要有变量,这就是语法错误。另一个作用是识别语法单位,。举个例子:A=B+C*60;是一个赋值语句,可以构建以下语法分析树,说明这是一个正确的赋值语句:
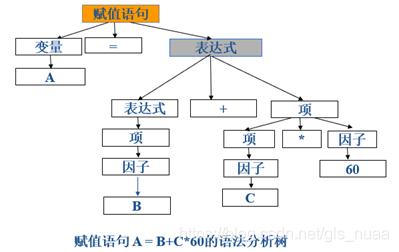 使用语法分析树的好处有什么呢?
使用语法分析树的好处有什么呢?
好处在于能够表示出语句的层次结构,同时也可以用于辅助对语句的翻译。
从下往上看,经历的算符分别是*到+再到赋值符=。这正好符合我们运算过程中对于优先级的体现(想想在运算中是不是先乘除,再加减,最后把结果赋值给左边)。
对于词法分析和语法分析的总结:词法分析是一种线性分析,语法分析是一种层次结构分析。
3) 语义分析与中间代码产生器
语义分析在语法分析之后,所以能到语义分析说明程序中已不存在语法错误。还用之前的a=b+c举例。对于+语义来说,要求左右两个操作数的类型应当相同。对其的检测就属于语义分析的部分。还有一些与具体语言相关的,典型情况包括:变量在使用前先进行声明、每个表达式都有合适的类型、函数的调用和函数的定义相关。(参考博客:https://blog.csdn.net/hit_shaoqi/article/details/83120448link,该博客中列举很多语义分析的错误例子)
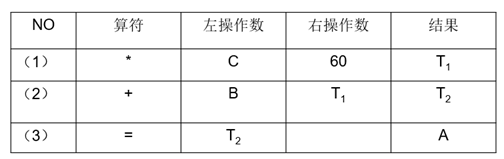
中间代码生成的步骤要先理解什么是中间代码?中间代码就是用简单表达式表示你要进行的操作,举个例子就明白:
对于A = B+C60;这个表达式生成的中间代码如下:
temp1 = C60
temp2 = B+temp1
A = temp2
对中间代码常用四元式表示,四元式的结构如下:

所以对于上面的中间代码转换为四元式如下:
4) 优化
优化的意思很明显,就是对代码进行调整使其运行时效率更高(体现在时间/空间上)。优化主要有三个方面:公共子表达式的提取,循环优化(主要优化对象),删除无用代码。
下面对三种优化分别举例:
公共子表达式的提取优化:
优化前
A = B + C;
…
D = B + C;
优化后
T = B + C;
A = T;
…
D = T;
循环优化:
优化前
for k=1 to 100
M=I+10k;
N=J+10k;
优化后
M=I;
N=J;
For k=1 to 100
M=M+10;
N=N+10;
从上面可以看出,循环优化的主要思想是把乘除法优化为加减法。(我们都知道乘除运算所用时间远大于加减法)。
删除无用代码:
无用代码就是对程序的结果没有影响的代码。主要可分为两部分
1. 复制传播
如果存在语句y=x,并且下面有许多语句在使用y。由于x,y在数值上相等,所以可利用x代替所有的y。这样就可以减少y=x这条语句。这种思想就叫做复制传播。
2. 无用代码(死code)
在程序编写过程中,可能出现对一个变量赋值,但后面并没有使用该变量,就认为该赋值无效,将其删除。
5) 目标代码生成:
目标代码生成的过程非常复杂,就是把优化好的中间代码转换成指定的低级语言代码(汇编语言或者机器语言等等)。比如上面所举例子最终转换的汇编代码如下图:

从以上五个步骤可以看出一个明显的分界线,就是第三步中语义分析和中间代码生成之间。在中间代码生成之前,都没有对代码的任何翻译,所做的只是分析,故又称为分析部分。语义分析之后都是对代码的翻译调整,故又称为综合部分。
二、有关编译程序的几个名词解释,包括:表格管理、出错处理、遍、编译前端/后端
表格管理:
在编译程序中的表格主要的指的是符号表。符号表内存储的内容就是标识符(变量)的各种信息。例如:变量类型,存储位置等等。而对符号表的维护是贯彻在整个阶段的。(即每个阶段对符号表都会增添或删改)
出错处理:
在编写程序过程中难免出错,所以对于错误的处理就至关重要。出错可分为两大类:语法错误和语义错误。对于错误处理分几个层次,由坏到好分别为:检测到错误并暂停报错、检测到错误提示报错信息并继续执行程序以发现更多的错误、检测到错误并由对应的办法对错误进行处理校正。
遍(趟):
平时总说一遍,两遍。但这里的“遍”定义为对源程序或源程序的中间结果从头到尾扫描一次并作有关的加工处理,生成新的中间结果或目标程序。一遍即可以对一个阶段而言(比如把词法分析单独作为一遍),也可以包括多个阶段(比如把词法分析、语法分析、语义分析和中间代码产生和为一遍)。
遍的作用是什么?
“遍”可以使编译程序结构更清晰,每一遍可以集中处理关键问题
编译前端/后端:
在概念上一个编译程序可划分为编译前端和编译后端。
编译前端主要由与源语言有关但与目标机无关的那部分组成的。这些部分通常包括词法分析,语法分析,语义分析与中间代码生成。
编译后端主要由与目标机有关的那部分组成的。这些部分通常包括优化和目标代码生成。
那为什么需要划分编译前端和后端呢?
从上面的概念可以看出,中间代码处于编译前端和编译后端的过渡位置。做这样一个图:
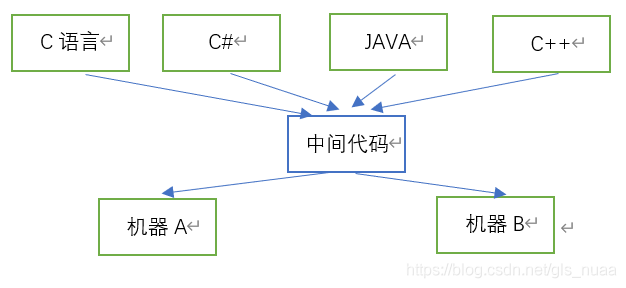
从这个图看出,高级语言变成中间代码这部分叫前端。前端可以由不同的部分引起。同样也可以产生不同的后端。这样不同的前端可以对应相同的后端,相同的前端可以对应不同的后端。就可以很好的体现代码的移植性。对于移植性的介绍会在后面说明。
在这里解释下为啥会有机器A,机器B的区分。在不同机器上的架构是不同的,据两个方面的例子。一方面是手机和pc机(一大一小,实现方式肯定不同),另一方面是指令集体系结构的不同,像CISC和RISC的实现结果肯定也不相同。
三、编译程序的生成、自展和移植
编译程序的生成有三大组成部分:源语言、编译程序、目标语言。编译程序的作用就是把源语言变成目标语言。更为具体:如果想让编译程序在目标机上运行,那么编译程序的编写语言需要是目标语言。(是不是很绕?这语言,那语言的)。为了更方便的说明,做了图形的规定(还是拿图说话!)取名为T形图:
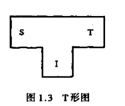 (s代表源语言,T代表目标语言,I代表编译程序)
(s代表源语言,T代表目标语言,I代表编译程序)
编译程序的自展
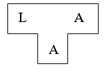
给定一个目标:在机器A(目标机)上,用语言A(编译程序实现语言),构造高级语言L(源语言)的编译程序。T形图表示为:
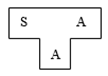
Step1:可以考虑使用L的子集S,在机器A上用语言A构造S的编译程序。T形图如下:
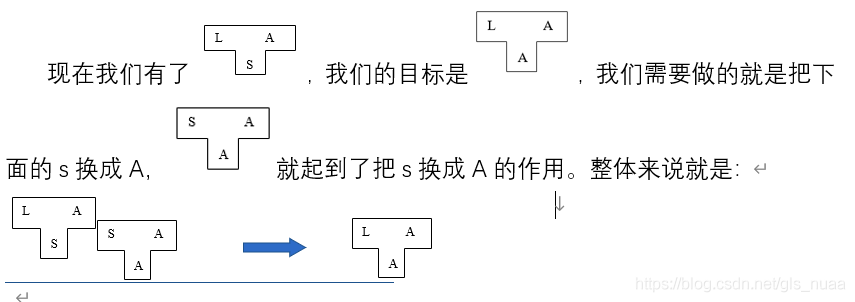
Step2:再在机器A上,用语言S构造L的编译程序。T形图如下:

再将两者结合,step1中s可编译成A,step2中可以利用S对L进行编译并在A机器上执行。我们所希望的是L以A的机器语言在A机器上运行,由step1可将S转换成A机器代码,所以L语言就可以用A的机器代码在A的机器上运行(是不是很绕?你如果第一次学那肯定是一脸懵的)我们用图说话:
写完以上过程,我有个疑问:为什么需要s是L的子集?上网找到一种说法发现可以接受,也更为贴切于自展的名字。(下图中的L1就是L的子集,从子集出发才能够慢慢扩展为L)

(节选于博客:https://blog.csdn.net/NameOfBlog/article/details/82857644link
编译程序的移植:
什么叫编译程序的移植呢?就是在A机器上已有的高级语言L编写一个在B机器上运行的高级语言L的编译程序。(简单来说就是L目前已经能使用A机器语言在机器A上运行,想要L能使用B机器语言在机器B上运行)T形图如下:
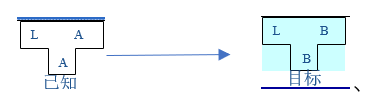
过程简记为一次编程两次编译
一次编程:使用L语言编写能够让L语言产生B机器代码的编译程序R
第一次编译:把R在A机器代码下编译使其变为A机器代码的语言,记为编译程序I,作用是把L编译成B
第二次编译:用编译程序I对R进行编译,成功完成L使用B机器语言完成的汇编程序在机器B上运行。
就单单这三段话就能让人找不着北!!!我们还是看图说话:
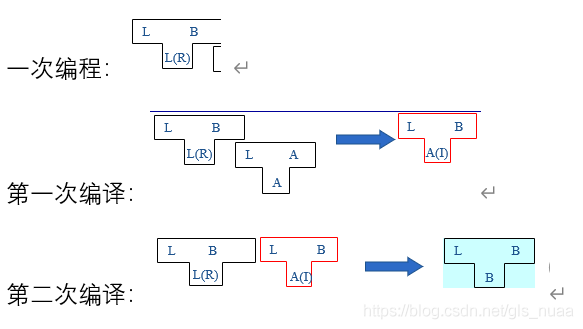
文字配图,事半功倍:
第一次编程,我们用L语言实现了编译程序R。注意R的本质是L语言,只不过功能是把L翻译成B。既然是L语言,通过已知L->A,我们可以把L语言变成A语言。这里的变成只是实现方式的改变,并没有改变原有的功能,还是一次编程的图,作用还是变成B语言,区别在于原来是用L语言实现的,现在用了A语言。也可以这样理解:
原来是L1-(L2)->B,又因为L2-(A)->A1。于是L1-(A1)->B。由一次编程知L通过R可变成B,现在只要R变成B就可以了。R的本质是L,第一次编译实现了L变成B,利用第一次的编译程序就可以把L变成B。这样R就变成了B就实现L-(B)->B。
刚学了绪论,对于编译原理的各个部分了解还过于粗浅。用了将近5000字才完成这篇文章。随着后面的学习,会更深层次的剖析每一个部分的。继续加油哈!
致谢:感谢编译原理课程谢老师对文章的耐心修改,同样感谢网上各位博主的优秀博文,为我不懂的地方提供解决办法。
因作者水平有限,如有错误之处,请在下方评论区指正,谢谢!