编译系统的结构
前端与源语言相关,后端与目标语言相关

词法分析
- 主要任务是将识别出的单词转换为统一的机内表示——词法单元形式
- Token:<种别码,属性值>
- 识别单词,确定单词的类型
语法分析
- 主要任务是构造语法分析树。
- </D/>:声明语句;</T/>:类型;</IDN/>:标识符
- 识别短语,构造语法分析树
- 中间代码生成
语义分析
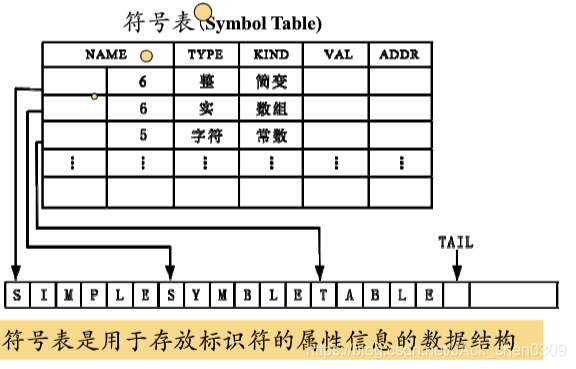
- 收集标识符的属性信息
- 种属。
- 类型。
- 存储位置、长度。
- 值。
- 作用域。
- 语义检查
- 变量或过程未经声明就使用
- 变量或过程名重复声明
- 运算分量类型不匹配
- 操作符与操作数之间类型不匹配

中间代码生成及编译器后端
- 中间表示形式:三地址码、语法结构树。
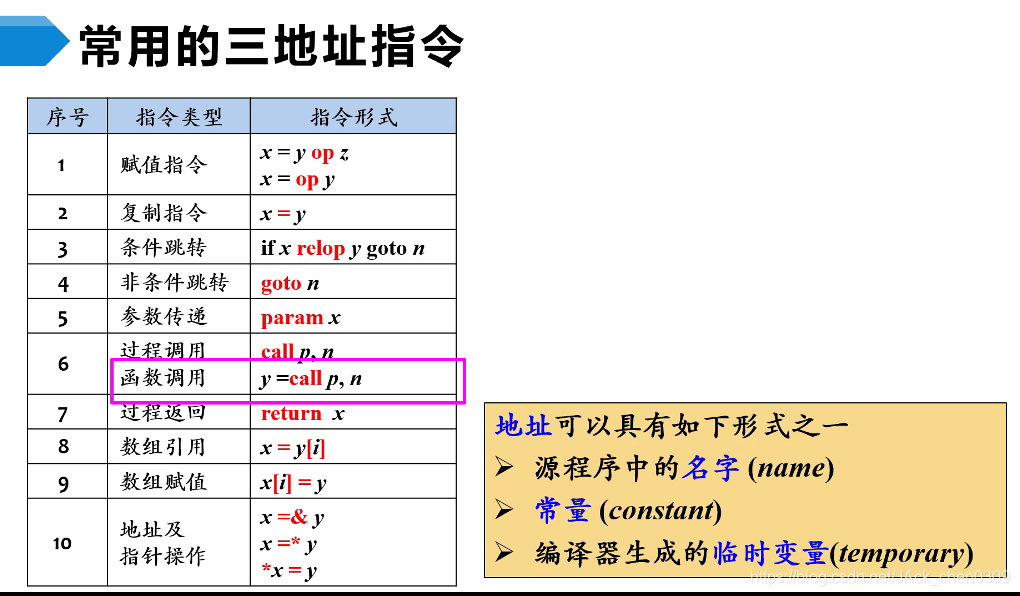
注意:8中是i是数组的偏移量
函数中有三个或以上的函数参数时,7中的n表示参数个数
三地址指令序列唯一确定了一个运算完成的顺序

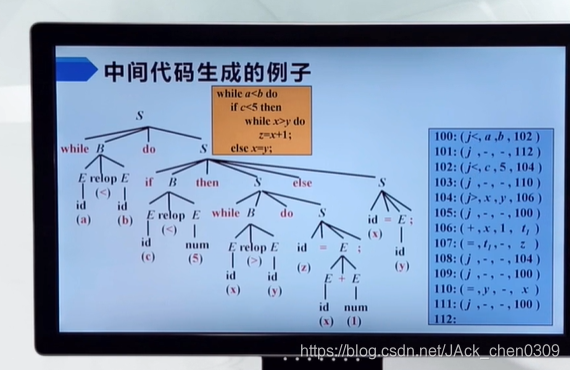
- 中间代码生成
- 编译器的结构

目标代码生成
代码优化
错题分析

解析:
词法分析是识别单词,输入:短语,输出:单词
语法分析是识别短语,输入:单词,输出:短语。
