上篇博客我们介绍了MapReduce的基本概念,并且对它的运行原理做了一些解析,今天我们来通过一个实际例子来深刻体会一下它的运行过程。
三、实例
今天我们来做一个简单的统计。对只用空格将英文单词隔开的一些数据源,将所有单词出现的次数做一些统计。
1、数据源
hello tom
hello jerry
hello kitty
hello world
hello tom2、Map
Map过程需要继承org.apache.hadoop.mapreduce包中的Mapper类,并重写map方法
通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中的value值存储的是文本文件中的一行(以回车符作为行结束标记),而key值为该行的首字符相对于文本文件的首地址的偏移量。然后WCMapper 类将每一行拆分成一个个的单词,并将
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException,
InterruptedException {
//接收数据V1
String line=value.toString();
//切分数据
String[] words=line.split(" ");
//循环
for (String w:words) {
//出现一次,记作一个,输出
context.write(new Text(w), new LongWritable(1));
}
}
}2、Reduce
Reduce过程需要继承org.apache.hadoop.mapreduce包中的Reducer类,并重写reduce方法
reduce方法的输入参数key为单个单词,而values是由各Mapper上对应单词的计数值所组成的列表,所以只要遍历values并求和,即可得到某个单词的出现总次数
public class WCReducer extends Reducer<Text, LongWritable,Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> v2s,Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//接收数据
//定义一个计算器
long counter=0;
//循环v2s
for (LongWritable i:v2s) {
counter+=i.get();
}
//输出
context.write(key,new LongWritable(counter));
}
}3、WordCount调用
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。此处设置了使用WCMapper完成Map过程和使用的WCReduce完成Combine和Reduce过程。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为LongWritable。任务的输入和输出路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
//构建job对象
Job job=Job.getInstance(new Configuration());
//main方法所在的类
job.setJarByClass(WordCount.class);
//设置Mapper相关属性
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("/words.txt"));
//设置Reducer相关属性
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job, new Path("/wcount.txt"));
//提交任务
job.waitForCompletion(true);
}
}4、解说
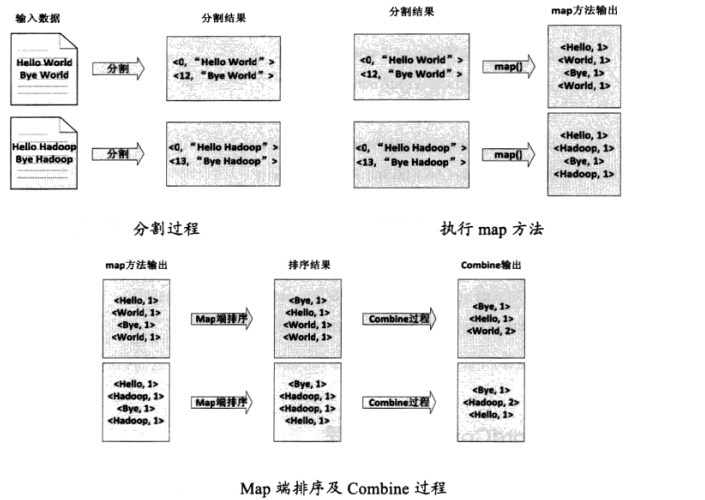
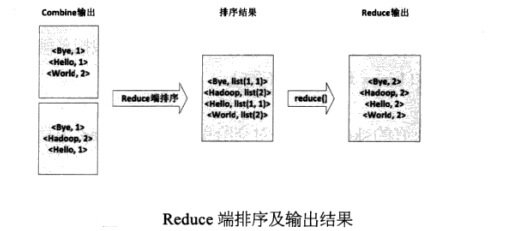
(1)将文件拆分成splits,由于测试用的文件较小,所以每一个文件为一个split,并将文件按行分割成<key, value>对,如图,这一步由Mapreduce框架自动完成,其中偏移量包括了回车所占的字符(2)将分割好的<key, value>对交给用户定义的map方法进行处理,生成新的<key, value>对(3)得到map方法输出的<key, value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果(4)Reduce先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key, value>对,并作为WordCount的输出结果总结:
至此,我们将Hadoop的两大核心学习完了,但是对我们来说,这只是刚刚开始,不过我们要打好基础,在之后的学习过程中去更加深入的研究。让我们一起准备迎接明天的挑战吧。