
壹 ❀ 引
我在从零开始学正则(一)这篇文章中介绍了正则横向模糊与纵向模糊匹配模式,以及常用的字符组与量词,掌握了这些其实已经算正则入门了。在文尾留下了两个正则问题,请写出匹配24小时制时间与16进制颜色的正则,在学习第二章之前我们先搞定这两个问题。
24小时制时间格式一般是09:30这样,小时的第一位数字可能是[0-2]三种情况之一,当为0,1时,第二位数字可以是[0-9]任意数字,当为2时第二位数字只能是0-3之间的数字。第三位数字只能是0-5之间的数字,最后一位数字只能是0-9之间。
我们只用对于小时的两种情况做个分支,所以正则可以写成这样:
var regex = /^([01][0-9]|[2][0-3]):[0-5][0-9]$/; regex.test("00:07"); //true regex.test("23:59"); //true
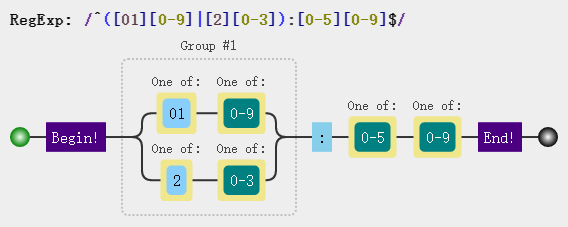
注意,匹配小时的分支我们使用了一对圆括号包裹,表示这是一个组,而组内包含了两个分支情况,如果不加圆括号正则解析时会将管道符 | 左右两侧理解成两个分支,如下图,很明显这不是我们想要的规则:
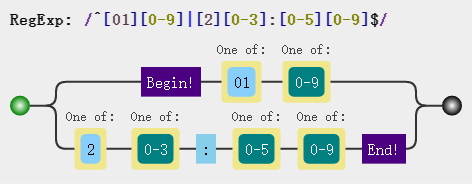
其次,在正则内部开头和结尾我们分别使用了^$两个符号,这表示正则匹配时严格以字符串开头和结尾中间的内容为匹配对象,如果不加效果就是这样:
var regex = /([01][0-9]|[2][0-3]):[0-5][0-9]/; regex.test("0000:0709");//true
这里是因为字符串中间有一部分是符合规则的,因此还是符合匹配规则,所以如果我们想匹配一个字段从头到尾是否符合规则,一定得记得加上^$符号。
我们再来分析16进制颜色,老实说我还真不知道16进制颜色范围是多少,查了下,每个字母范围均为[0-9a-fA-F],但由于颜色值可以简写,比如 #ffffff 可以简写成 #fff,所以存在6位与3位的情况,正则可以这么写:
var regex = /^#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})$/; regex.test("#e4393c"); //true regex.test("#2b99ff"); //true
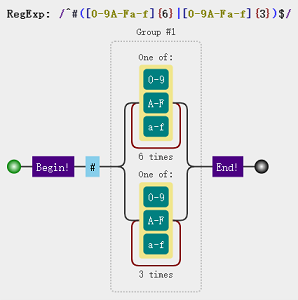
那么上章节留下的问题就说到这,开始第二章学习。说在前面,正则学习系列文章均为我阅读 老姚《JavaScript正则迷你书》的读书笔记,文中所有正则图解均使用regulex制作。本章节主要讲述如何匹配字符位置,那么本文开始!
贰 ❀ 正则中的位置
注意,这里所说的位置并不是我们遍历数组时所使用的索引概念,正则匹配的位置又称为锚,是指相邻字符之间的位置,这里借用原书中的图解,每个箭头就是一个位置:

正则使用中,匹配位置的字符又称为锚,在文章开头我们已经见过了 ^$ 两个锚,我们来验证下位置的概念,看个简单的例子:
var str = '听风是风'; var regex = /^|$/g; var result = str.replace(regex, '❀'); //❀听风是风❀
可以看到两个位置被替换成了花朵,此时字符串的开头位置与结尾位置发生了变化,开头变成了花朵左边,结尾位置变为第二朵花的右边。
叁 ❀ 理解正则的锚
出了常用的^$,在ES5中一共包含六个锚,分别是^、$、\b、\B、(?=p)、(?!p),我们一一细说。
^ 脱字符:匹配开头,在多行中匹配行开头,比如:
var str = '听风\n是风'; var regex = /^/mg; var result = str.replace(regex, '❀');
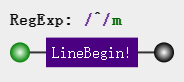

注意,正则结尾添加了一个mg,g(global)前面有解释表示全局匹配,表示一行从左到右完整匹配一遍,而m(more)表示多行匹配,mg就是多行全局匹配,每行不管文本多长,都完全匹配一遍。
$美元符号:匹配结尾,在多行中匹配行尾。
\b单词边界:表示\w(单词字符)与\W(非单词字符)之间,\w(单词字符)与 ^ (脱字符)之间,以及\w (单词字符)与$ 之间的位置,有点难理解,先看个例子:
var str = '[echo].123'; var regex = /\b/g; var result = str.replace(regex, '❀'); //[❀echo❀].❀123❀
上面解析有点长,我们缩短点,\b表示\w与\W、^、$之间的位置,而\w范围是[0-9a-zA-Z_],那么我们再看上面的例子,为了方便理解,我们拆分细说:
从左往右看,首先 ^ 与 [ 之间不满足,再到 [ 与 e 之间,[ 是非单词符而 e 是单词符,满足条件。
echo由于四个字母都是单词符,直接跳过,o 与 ] 又满足了条件。
] 与 . 之间很明显不符合,再看 . 与1又满足了条件。
123都是单词符,跳过,直接到了尾部 3 与 $,满足条件。
\B非单词边界,意思与\b相反,匹配\w 与 \w、 \W 与 \W、^ 与 \W,\W 与 $ 之间的位置,还是上面的例子,我们改改匹配条件:
var str = '[echo].123'; var regex = /\B/g; var result = str.replace(regex, '❀'); //❀[e❀c❀h❀o]❀.1❀2❀3
可以看到 ^ 与 [ 之间,以及单词符与单词符之间都满足了条件。
(?=p)正向先行断言:p表示一个匹配模式,即匹配所有满足条件p的字段的前面位置,有点绕口,看个简单的例子:
var str = 'hello'; var regex = /(?=l)/g; var result = "hello".replace(regex, '❀'); //he❀l❀lo
这里就是先在字符串中找到字母 l,然后再找到 l 前面的位置就是目标位置。为了方便,直接利用前面位置理解的图,也就是这两个红框了:
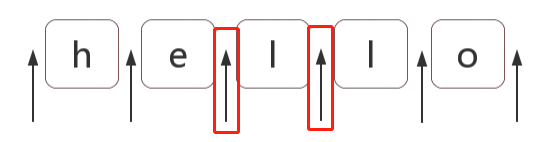
那么(?!p)与(?=p)就是反过来的,还是上面的例子,我们改改条件,也就是下图中绿框中的位置:
var str = 'hello'; var regex = /(?!l)/g; var result = "hello".replace(regex, '❀'); //❀h❀ell❀o❀
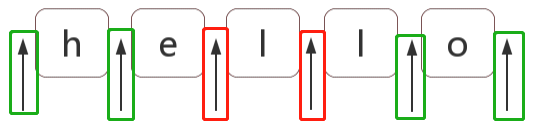
如果不看这个图,我不知道大家有没有这样的疑惑,不对啊,前面解释 \b单词边界时,是从 ^脱字符 开始判断的,脱字符也不满足条件前面也应该加朵❀,最终输出难道不应该是 ❀❀h❀ell❀o❀ 这样吗?o后面有❀ 是因为o后面还有个 $,$不满足条件所以才这样啊。
记住,^和$是两个位置,^$是两个位置,^$是两个位置,不要将^$主动理解成两个隐藏字符,我们现在是在匹配位置。
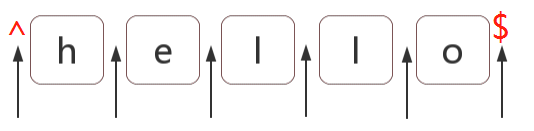
所以 /(?=l)/g 就是在找 l 前面的位置,而 /(?!l)/g 本质上来说就是找不是字母 l 前面的其它所有位置!
那为什么 \b单词边界还能从 ^ 开始判断呢,因为概念就包含了判断\w 与 ^ 之间的位置,在判断单词边界时,^$这两个特殊位置就像两个隐藏字符一样,也成了判断位置的条件(用位置判断位置,骚的不行)。而在判断(?!p)与(?=p)时,主要p不是^$,那么此时的 ^$ 单纯作为两个位置,不会主动作为判断条件参与判断,这一点千万不要弄混了!!!
肆 ❀ 位置的特性
读到这里我也有点迷糊,本来就是找位置,你 ^$ 作为位置应该是被找的对象,怎么还反客为主成了找位置的条件了,位置和位置之间难道还有位置?正则里还真是这样!
我们可以将位置理解成一个空字符" ",就像上图的箭头,一个hello可以写成这样:
"hello" = "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
它甚至还能写成这样,站在位置的角度,位置能是无限个:
"hello" = "" + "" + "hello"
以正则的角度,我们测试一个单词是否为hello甚至可以写成这样:
var str = 'hello'; var regex = /^^^^^hello$$$$$$$$$$$$/g; var result = regex.test(str); //true
当然这是我们站在匹配正则位置的角度抽象理解成这样的,毕竟真的给字符串加空格,字符串就真的变样了。
我也不太理解这个位置概念为啥要设计成这样....脑壳疼,反正大家理解这个点就好了。

\b单词边界会拿^$这两个特殊位置作为判断其它位置的条件,记住这一点。
伍 ❀ 总
那么到这里,第二章就说完了,内容其实真不多,只是这个位置让人有点懵,多回顾一下就好了。这里我整理了一份简单的思维导图,大家可以看着回顾一下本篇知识点:

最后留几个思考题,请写出一个正则将"12345678"变成千位分隔符表示法 "12,345,678",以及写一个正则验证密码,密码格式必须在6-12位之间,且至少包含数字,小写字符,大写字符其中两种。
那么本文就到这里了,我得学习第三章了!