import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import validation_curve
引入库np和sklearn等库。
#定义两个函数
def PR(degree=2,**kwargs):
return make_pipeline(PolynomialFeatures(degree),LinearRegression(**kwargs))
#使用make_pipeline串连两个模型(多项式特征,线性回归)
def md(n,err=1,rseed=1):#定义随机数据的生成,且具有一定关系。
rng=np.random.RandomState(rseed)
x=rng.rand(n,1)**2
y=10-1/(x.ravel()+0.1)
if err>0:
y+=err*rng.randn(n)
return x,y
然后简单的生产数据集。
#生成40个数据
x1, y1 = md(40)
plt.scatter(x1.ravel(), y1)
画出生产的数据集的散点图。
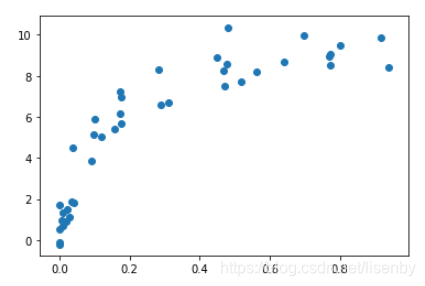
设置超参数,画出训练得分与验证得分的验证曲线
degree=np.arange(21)#超参数
ts1,vs1=validation_curve(PR(),x1,y1,'polynomialfeatures__degree',degree,cv=7)
#做出XY的验证曲线
plt.plot(degree,np.median(ts1,1),color='red',label='ts')
plt.plot(degree,np.median(vs1,1),color='blue',label='vs')
plt.ylim(0,1)
plt.xlabel('degree')
plt.ylabel('score')
plt.legend()
从验证曲线图里面就很容易看出数据在偏差和均方差为3的地方均衡性最好。
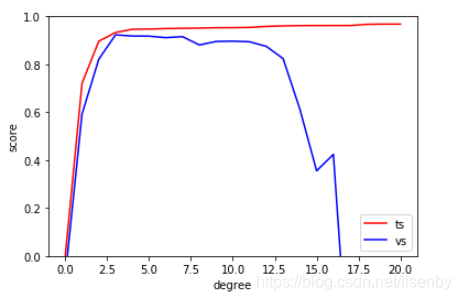
x_test=np.linspace(-0.1,1.1,500)[:,None]#生成500个均匀分布范围-0.1-1.1之间的数据集。
plt.scatter(x1.ravel(), y1)
lim = plt.axis()
y_test = PR(3).fit(x1, y1).predict(x_test)
plt.plot(x_test.ravel(), y_test);
plt.axis(lim);
于是画出三次多项式在原数据集上的形状。
下面扩大训练数据,获得数据新的拟合模型,用来观察模型的行为,绘制学习曲线
#讲不同量数的数据集进行模型
degree=np.arange(21)
ts2,vs2=validation_curve(PR(),x2,y2,'polynomialfeatures__degree',degree,cv=7)
plt.plot(degree,np.median(ts2,1),color='red',label='ts')
plt.plot(degree,np.median(vs2,1),color='blue',label='vs')
plt.plot(degree,np.median(ts1,1),color='red',alpha=0.3,linestyle='dashed')
plt.plot(degree,np.median(vs1,1),color='blue',alpha=0.3,linestyle='dashed')
plt.ylim(0,1)
plt.xlabel('degree')
plt.ylabel('score')
plt.legend()
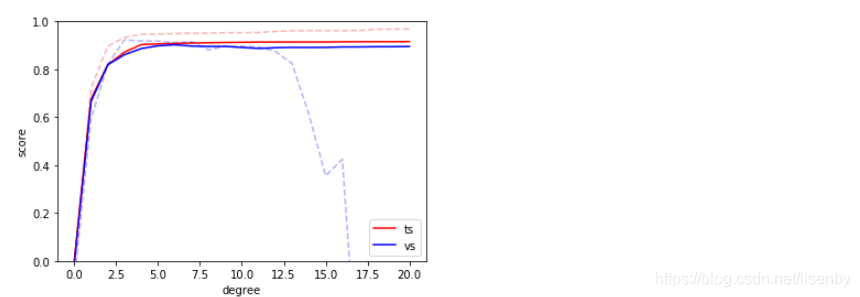
图中虚线部分是40个数据在不同超参数下的训练情况,而实线部分是用200个数据训练的情况。
通过这张图,可以看出大数据集会支持更复杂的模型,尽管这次的大数据集在6次多项式就已经获得了顶点,但是即使到了20次的多项式,过拟合情况也不严重。
PS:
1、特定复杂度的模型对较小的数据集容易过拟合:此时训练得分较高,验证得分较低。
2、 特定复杂度的模型对较大的数据集容易欠拟合:随着数据的增大,训练得分会不断降低,
而验证得分会不断升高。
3、模型的验证集得分永远不会高于训练集得分:两条曲线一直在靠近,但永远不会交叉
4、模型的复杂度和训练集的规模会影响模型得分,如果模型得分已经收敛到一定程度,那么改善模型性能的唯一方法就是换一个更复杂的模型。