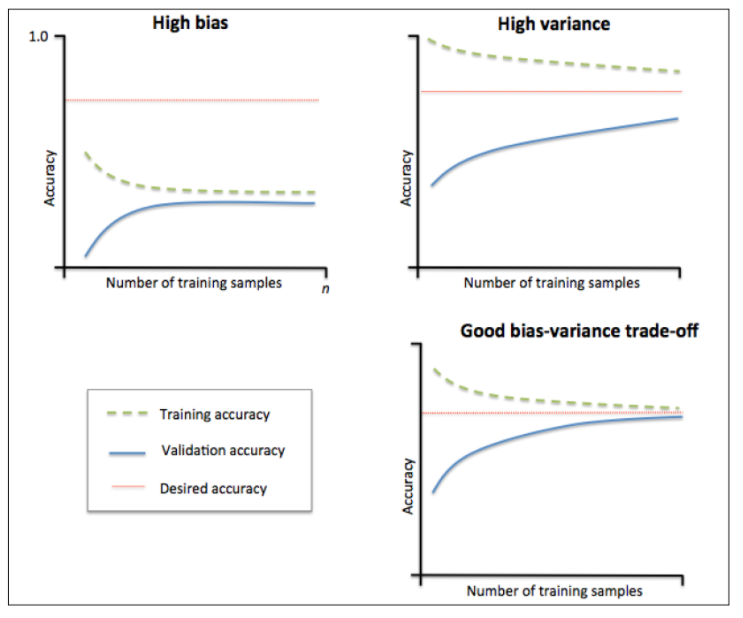
学习曲线是一种有用的诊断图形,它描述了机器学习算法相对可用观测量数量的表现。它的主要思想是将算法的训练性能与交叉验证结果进行比较,训练性能主要是指样本内误差获准确率,交叉验证通常采用十折交叉验证方法。
就训练集而言,训练结果的期待开始时应该高,然后会下降。然而,根据假设的偏差和方差水平不同,有不同的表现。
1)高偏差的机器学习算法倾向于从平均性能开始,当遇到更多复杂数据时性能迅速降低,然后,无论增加多少实例都保持在相同的水平。低偏差的机器学习算法在样本多时能够更好地泛化,但是只适用于相似的复杂数据结构,因此也限制了算法的性能。
2)高方差的假设往往开始时性能很好,然后随着增加更多的实例,性能慢慢降低,原因在于它记录了大量的训练样本特征。
对于验证集而言,表现如下:
1)高偏差的假设往往从低性能开始,但它的增长非常迅速,直到达到了几乎与训练数据相同的性能。然后,它的性能不再提高。
2)高方差的假设往往从非常低的性能开始。然后,平稳又缓慢地提高性能,这是因为更多的实例有助于提高泛化能力。它很难达到训练集上的性能,在它们之间总有一段差距。
理想的学习曲线
模型的最终目标是,误差小并能很好地泛化到未知数据。
如果测试曲线和训练曲线均收敛,并且误差极低,这是理想中的模型。这种模型能根据未见过的数据非常准确地进行预测