文章目录
实验要求
设计一个32bits整数乘法器,输入为a[],b[],输出为y[]
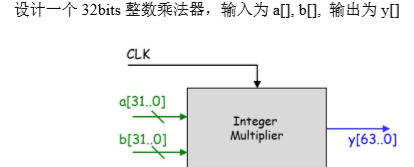
必做
面积优化的迭代乘法器
要求乘法器的迭代次数是1,2,4,8,16,32之内的可编程参数。
利用Vivado进行逻辑综合,分析不同迭代次数对逻辑资源的占用、吞吐性能、硬件效率的影响
设计一种方便展示的模块,验证你的设计
(利用第一个实验的7位数码管的显示)
选做(提高要求)
性能优化的单周期流水线乘法器
在单周期乘法器的基础上引入流水线结构,使流水线是个可编程参数。
在流水线级数为1,2,4,8的情况下分别进行逻辑综合
核心代码
工程结构

代码说明
Multi是顶层模块
Constrain是约束文件
其中
Multiplier_Pre M_P(.Clk(Clk),.A(A),.B(B),.Y(Y),.Done(Done));
AL_M AL_M(.A(A),.B(B),.C(Y),.clk(Clk),.rst(Rst));
两个语句分别是
Multiplier_Pre:面积优化的迭代乘法器
AL_M:流水线乘法器
使用哪一个就将另外一个注释掉即可
assign Y=A*B;//这是用来进行分析对比的时候的的代码,不需要管
由于Basy3硬件的限制,实际上要求的32bit乘法无法在硬件上做到显示
所以代码中个别部分直接将32bits乘数的高16bits位默认为零
顶层模块
module Multi(Array,Segs,Seg_sel,Clk,M_set,D_set,Rst_set
);
input D_set;
input M_set;
input Clk;
input Rst_set;
input [15:0]Array;
wire [6:0]Segs_n;
wire [3:0]Seg_sel_n;
output [6:0] Segs;
output [3:0]Seg_sel;
reg [31:0]out_sell;
reg [31:0]A;
reg [31:0]B;
reg M;
reg Done;
wire [3:0]Thrs;
wire [3:0]Hrs;
wire [3:0]Tens;
wire [3:0]Ones;
wire [3:0]Dval;
reg Rst;
wire [63:0]Y;
initial begin
out_sell<=32'b0;
A<=16'b0;
B<=16'b0;
M<=1'b0;
Done<=1'b0;
Rst<=0;
end
always@(posedge Clk)begin
if(Rst_set)begin
Rst<=1;
M<=0;
Done<=0;
end
if(M_set)begin
M<=1;
Done<=0;
Rst<=0;
end
else if(D_set)begin
Done<=1;
M<=0;
Rst<=0;
end
end
always@(M or Done or Clk or Array)begin
if(Done==1)begin
out_sell<=Y[31:0];
end
else if(M<=0) begin
out_sell<=Array;
A<={16'b0,Array};
end
else if(M==1)begin
out_sell<={16'b0,Array};
B<={16'b0,Array};
end
end
Binary_to_BCD B1(.SW(out_sell[15:0]),.Hrs(Hrs),.Tens(Tens),.Ones(Ones),.Ths(Thrs));
Refresh R1(.Clk(Clk),.Rst(1'b0),.SegSel(Seg_sel_n));
MUX M1(.Refresh(Seg_sel_n),.Dval(Dval),.Hrs(Hrs),.Tens(Tens),.Ones(Ones),.Thr(Thrs));
BCD_to_7_segment B_2_C(.X(Dval),.Lights(Segs_n));
//
//
//如下Multi_Pre和AL_M
//分别是迭代乘法器和流水线乘法器
//使用时只需要注释掉其中一个保留其中一个即可
Multiplier_Pre M_P(.Clk(Clk),.A(A),.B(B),.Y(Y),.Done(Done));
// AL_M AL_M(.A(A),.B(B),.C(Y),.clk(Clk),.rst(Rst));
// assign Y=A*B;//这是用来进行分析对比的时候的的代码,不需要管
assign Segs=~Segs_n;
assign Seg_sel=~Seg_sel_n;
endmodule
面积优化迭代乘法器
module Multiplier_Pre(Clk,A,B,Y,Done);
parameter N=2;
input Done;
input Clk;
input [31:0]A;
input [31:0]B;
output [63:0]Y;
reg [63:0]Y1;
reg [31:0] B_C;
reg [63:0]R;
reg [5:0]cnt;
integer i;
initial begin
cnt<=6'b0;
R<=63'b0;
B_C<=31'b0;
Y1<=64'b0;
end
always@(posedge Clk)begin
if(Done==0) begin
cnt=6'b0;
end
else begin
if(cnt<N)begin
if(cnt==0)begin
Y1=64'b0;
cnt=0;
end
for(i=0;i<32/N;i=i+1)begin
B_C[i]=B[32*cnt/N+i];
end
R=(B_C*A);
Y1=Y1+(R<<(32*cnt/N));
cnt=cnt+1'b1;
end
end
end
assign Y=Y1;
endmodule
流水线乘法器(选做、提升)
module AL_M(A,B,C,clk,rst
);
input rst;
input clk;
input [31:0]A;
input [31:0]B;
output [63:0]C;
reg [63:0]out_reg;
parameter N=1;//N级流水线
reg [15:0]A_reg;//将最短路径与外界隔开
reg [15:0]B_reg;
reg[31:0] store15;
reg[31:0] store14;
reg[31:0] store13;
reg[31:0] store12;
reg[31:0] store11;
reg[31:0] store10;
reg[31:0] store9;
reg[31:0] store8;
reg[31:0] store7;
reg[31:0] store6;
reg[31:0] store5;
reg[31:0] store4;
reg[31:0] store3;
reg[31:0] store2;
reg[31:0] store1;
reg[31:0] store0;
reg[31:0] add01;
reg[31:0] add23;
reg[31:0] add45;
reg[31:0] add67;
reg[31:0] add89;
reg[31:0] addAB;
reg[31:0] addCD;
reg[31:0] addEF;
reg[31:0] add0123;
reg[31:0] add4567;
reg[31:0] add89AB;
reg[31:0] addCDEF;
reg[31:0] add01234567;
reg[31:0] add89ABCDEF;
reg[31:0] addALL;
//以上store的相关用来存储最小积序列
//根据实际情况可以选择不用一些
initial
begin
A_reg<=16'b0;
B_reg<=16'b0;
store15<=32'b0;
store14<=32'b0;
store13<=32'b0;
store12<=32'b0;
store11<=32'b0;
store10<=32'b0;
store9<=32'b0;
store8 <= 32'b0;
store7 <= 32'b0;
store6 <= 32'b0;
store5 <= 32'b0;
store4 <= 32'b0;
store3 <= 32'b0;
store2<= 32'b0;
store1 <= 32'b0;
store0 <= 32'b0;
add01 <= 32'b0;
add23 <= 32'b0;
add45 <= 32'b0;
add67 <= 32'b0;
add89<=32'b0;
addAB<=32'b0;
addCD<=32'b0;
addEF<=32'b0;
add0123 <= 32'b0;
add4567 <= 32'b0;
add89AB<= 32'b0;
addCDEF<= 32'b0;
add01234567<= 32'b0;
add89ABCDEF<= 32'b0;
addALL<= 32'b0;
end
always @ (posedge clk or posedge rst)
begin
if(rst)
begin
A_reg<=16'b0;
B_reg<=16'b0;
store15<=32'b0;
store14<=32'b0;
store13<=32'b0;
store12<=32'b0;
store11<=32'b0;
store10<=32'b0;
store9<=32'b0;
store8<=32'b0;
store7 <= 32'b0;
store6 <= 32'b0;
store5 <= 32'b0;
store4 <= 32'b0;
store3 <= 32'b0;
store2 <= 32'b0;
store1 <= 32'b0;
store0 <= 32'b0;
add01 <= 32'b0;
add23 <= 32'b0;
add45 <= 32'b0;
add67 <= 32'b0;
add89<=32'b0;
addAB<=32'b0;
addCD<=32'b0;
addEF<=32'b0;
add0123 <= 32'b0;
add4567 <= 32'b0;
add89AB<= 32'b0;
addCDEF<= 32'b0;
add01234567<= 32'b0;
add89ABCDEF<= 32'b0;
addALL<= 32'b0;
end
else
begin//存储最小积
A_reg<=A[15:0];
B_reg<=B[15:0];
store0 <= B_reg[0] ? {16'b0,A_reg}:32'b0;
store1 <= B_reg[1] ? {15'b0,A_reg,1'b0}:32'b0;
store2 <= B_reg[2] ? {14'b0,A_reg,2'b0}:32'b0;
store3 <= B_reg[3] ? {13'b0,A_reg,3'b0}:32'b0;
store4 <= B_reg[4] ? {12'b0,A_reg,4'b0}:32'b0;
store5 <= B_reg[5] ? {11'b0,A_reg,5'b0}:32'b0;
store6 <= B_reg[6] ? {10'b0,A_reg,6'b0}:32'b0;
store7 <= B_reg[7] ? {9'b0,A_reg,7'b0}:32'b0;
store8 <= B_reg[8] ? {8'b0,A_reg,8'b0}:32'b0;
store9 <= B_reg[9] ? {7'b0,A_reg,9'b0}:32'b0;
store10 <= B_reg[10] ? {6'b0,A_reg,10'b0}:32'b0;
store11 <= B_reg[11] ? {5'b0,A_reg,11'b0}:32'b0;
store12 <= B_reg[12] ? {4'b0,A_reg,12'b0}:32'b0;
store13 <= B_reg[13] ? {3'b0,A_reg,13'b0}:32'b0;
store14 <= B_reg[14] ? {2'b0,A_reg,14'b0}:32'b0;
store15 <= B_reg[15] ? {1'b0,A_reg,15'b0}:32'b0;
//优先处理前16位,由于硬件版的限制,无法真正实现32位乘法,最多至16位,默认剩下16位均为0
// store0 <= B[0] ? {32'b0,A}:32'b0;
case(N)
1:
addALL<=store0+store1+store2+store3+store4+store5+store6+store7
+store8+store9+store10+store11+store12+store13+store14+store15;
2:
begin
add01234567<=store0+store1+store2+store3+store4+store5+store6+store7;
add89ABCDEF<=store8+store9+store10+store11+store12+store13+store14+store15;
addALL<=add01234567+add89ABCDEF;
end
4:
begin
add0123<=store0+store1+store2+store3;
add4567<=store4+store5+store6+store7;
add89AB<=store8+store9+store10+store11;
addCDEF<=store12+store13+store14+store15;
add01234567<=add0123+add4567;
add89ABCDEF<=add89AB+addCDEF;
addALL<=add01234567+add89ABCDEF;
end
8:
begin
add01<=store0+store1;
add23<=store2+store3;
add45<=store4+store5;
add67<=store6+store7;
add89<=store8+store9;
addAB<=store10+store11;
addCD<=store12+store13;
addEF<=store14+store15;
add0123<=add01+add23;
add4567<=add45+add67;
add89AB<=add89+addAB;
addCDEF<=addCD+addEF;
add01234567<=add0123+add4567;
add89ABCDEF<=add89AB+addCDEF;
addALL<=add01234567+add89ABCDEF;
end
endcase
out_reg<={32'b0,addALL};
end
end
assign C=out_reg;
endmodule
BCD-to-7-Segment
module BCD_to_7_segment(X,Lights);
input [3:0] X;
output reg [6:0] Lights;
reg X3,X2,X1,X0;
reg A,B,C,D,E,F,G;
always @(X)begin
{X3,X2,X1,X0}=X;
case({X3,X2,X1,X0})
4'd0:{A,B,C,D,E,F,G}=7'b1111110;
4'd1:{A,B,C,D,E,F,G}=7'b0110000;
4'd2:{A,B,C,D,E,F,G}=7'b1101101;
4'd3:{A,B,C,D,E,F,G}=7'b1111001;
4'd4:{A,B,C,D,E,F,G}=7'b0110011;
4'd5:{A,B,C,D,E,F,G}=7'b1011011;
4'd6:{A,B,C,D,E,F,G}=7'b1011111;
4'd7:{A,B,C,D,E,F,G}=7'b1110000;
4'd8:{A,B,C,D,E,F,G}=7'b1111111;
4'd9:{A,B,C,D,E,F,G}=7'b1111011;
default {A,B,C,D,E,F,G}=7'b0000000;
endcase
Lights={A,B,C,D,E,F,G};
end
endmodule
Binary-to-BCD
这个部分的代码和前两个实验略有不同,增加了对于千位的处理
module Binary_to_BCD(SW,Hrs,Tens,Ones,Ths);
input [15:0] SW;
output [3:0]Ths;
output [3:0]Hrs;
output [3:0]Tens;
output [3:0]Ones;
reg [31:0] Z;
always@(SW)begin
Z=32'b0;
Z[15:0]=SW;
repeat(16)
begin
if(Z[19:16]>4)
Z[19:16]=Z[19:16]+2'b11;
if(Z[23:20]>4)
Z[23:20]=Z[23:20]+2'b11;
if(Z[27:24]>4)
Z[27:24]=Z[27:24]+2'b11;
if(Z[31:28]>4)
Z[31:28]=Z[31:28]+2'b11;
Z[31:1]=Z[30:0];
end
end
assign Ones=Z[19:16];
assign Tens=Z[23:20];
assign Hrs=Z[27:24];
assign Ths=Z[31:28];
endmodule
多工器
module MUX(Refresh,Dval,Hrs,Tens,Ones,Thr
);
input [3:0] Refresh;
input [3:0]Tens;
input [3:0]Hrs;
input [3:0]Ones;
input [3:0]Thr;
output reg [3:0]Dval;
always@(*) begin
case(Refresh)
4'b0000:Dval=4'b0000;
4'b0001:Dval=Ones;
4'b0010:Dval=Tens;
4'b0100:Dval=Hrs;
4'b1000:Dval=Thr;
default:Dval=5'b0000;
endcase
end
endmodule
刷新电路
module Refresh(Clk,Rst,SegSel
);
input Clk,Rst;
output reg [3:0]SegSel;
initial begin
SegSel=4'b0001;
end
reg [7:0] count_fst;
reg[3:0]count_second;
always@(posedge Clk)begin
if(Rst==1) begin
count_fst<=8'b00000000;
SegSel<=4'b0000;
end
else begin
if(count_fst==8'b11111111)
begin
count_fst<=4'b00000000;
count_second<=count_second+1'b1;
if(count_second==4'b1111)begin
count_second<=4'b0000;
case(SegSel)
4'b0000:SegSel<=4'b0001;
4'b0001:SegSel<=4'b0010;
4'b0010:SegSel<=4'b0100;
4'b0100:SegSel<=4'b1000;
4'b1000:SegSel<=4'b0001;
default:SegSel<=4'b0000;
endcase
end
end
else count_fst<=count_fst+8'b00000001;
end
end
endmodule
面积优化计算器结果
综合结果



仿真结果
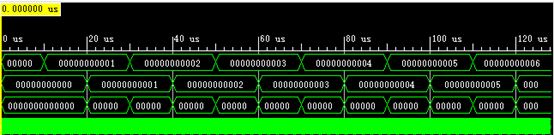
仿真代码
module Test(
);
reg [31:0]A;
reg [31:0]B;
wire [63:0]Y;
reg Clk;
M1 M1(.A(A),.B(B),.Y(Y),.Clk(Clk));
initial begin
Clk=0;
A=32'b0;
B=32'b0;
end
always begin
#5 Clk=~Clk;
end
always begin
#10000 A=A+1'b1;
#10000 B=B+1'b1;
$write("{%0d} {%0d} {%0d}",A,B,Y);
end
endmodule
实际效果

流水线计算器结果
仿真结果

仿真代码
module Testbench(
);
reg [31:0]A;
reg [31:0]B;
wire [63:0]Y;
reg Clk;
AL_M AL_M(.A(A),.B(B),.C(Y),.clk(Clk),.rst(0));
initial begin
A<=32'b0;
B<=32'b0;
Clk<=1'b0;
end
always
begin
#5000
A<=A+1;
end
always
begin
#10000
B<=B+1;
end
always
begin
#1
Clk<=~Clk;
end
endmodule
如果时钟超过最高频率

就会出现如上图的时延很严重的情况