《Neural Approaches to Conversational AI》学习笔记
基本框架:
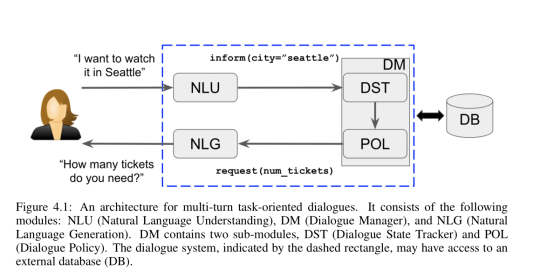
Natural Language Understanding (NLU): This module takes the user’s raw utterance as
input and converts it to the semantic form of dialogue acts.
Dialogue Manager (DM): This module is the central controller of the dialogue system. It
often has a Dialogue State Tracking (DST) sub-module that is responsible for keeping track
of the current dialogue state. The other sub-module, the policy, relies on the internal state
provided by DST to select an action. Note that an action can be a response to the user, or
some operation on backend databases (e.g., looking up certain information)
Natural Language Generation (NLG): If the policy chooses to respond to the us
NLU模块
NLU模块将用户的话语作为输入,并执行三个任务:域检测、意图确定和插槽标记。
下图给出了这三个任务的示例输出。
通常采用管道方法,这样三个任务就会一个接一个地解决。
准确度和F1得分是评价模型预测质量最常用的两个指标。
NLU是对话系统中后期模块的预处理步骤,其质量对系统的整体质量有重大影响)。

前两个任务也可看作分类问题,可用卷积神经网络或循环神经网络来做。
槽位标注任务可视为序列分类,分类器对输入话语的子序列预测语义类标签,其中模型为每个单词预测了一个语义标签(可用RNN进行)。
槽位标注任务可采用双向LSTM进行,每一个隐藏层输出用于预测当前词的槽点标注类型(可在尾部同步预测意图,整个工作也可用bert直接替代)。

三个任务同步进行的时候,可以使用更少的监督数据,提高工作效率。
对话状态
在填槽问题中,对话状态包含用户在当前对话中寻找的内容的所有信息。
对话策略将此状态作为输入,以决定下一步采取什么行动。

上面这个模型(DST)需要三个项作为输入,前两个分别是系统和用户最后的交互话语(用神经网络或多层感知机得到向量表征),第三个输入是模型正在跟踪的任何槽值对。
然后,这三个嵌入可能会相互作用以进行上下文建模,提供来自对话流的进一步上下文信息,以及语义解码,以决定用户是否明确地表达了与输入槽值对匹配的意图。最后,上下文建模和语义解码向量通过softmax层产生最终的预测。对所有可能的候选槽值对重复相同的过程。
对话策略学习模块
使用RL有两种方式进行对话策略学习:在线和批处理。在线学习方式要求学习者与用户进行互动,以改进策略;批处理方法假定一组固定的转换,并仅基于数据优化策略,而不与用户交互。这里主要讨论在线学习方式(内部含批处理)。
一种方法是将其编码为特征向量,包括:(1)对话动作和与最后用户动作对应的插槽的一个one-hot再现;(2)与最后一次系统动作对应的对话动作和插槽相同的一次one-hot表示;(3)对应到目前为止对话中所有先前填充的槽的一袋槽;(4)当前轮数;(5)与已填充的通知槽约束相匹配的知识库结果的数量。
通过训练上述向量,模型输出一个实值向量,它对应于对话系统可以选择的所有可能的(对话框-act,槽)对。如果某些(对话框-act,插槽)对对系统没有意义,比如请求(price),可用先验知识来减少输出的数量。
用q表示输出向量,g为激活函数,如relu,最后一层不用激活函数,作为输出。

过程中参数的更新可以使用强化学习的思想。
域扩展
在面向任务的对话系统部署为用户服务后,随着时间的推移,可能需要添加更多的意图或插槽,以使系统更具通用性。这个问题被称为域扩展,使得探索更具挑战性:代理需要明确地量化意图/插槽参数中的不确定性,以便更积极地探索新的内容,同时避免探索那些已经学习过的内容。
Lipton等人利用DQN的Backprop变体使用贝叶斯方法来解决这个问题(4.4.2章节)。
组合任务对话

人类交互(左)->强化学习->强化学习+人机交互


奖励机制
受深度学习对抗性训练的启发,Liu和Lane提出将奖励功能视为区分人类产生的对话和对话政策产生的对话的甄别器。因此,在他们的方法中有两个学习过程:作为甄别者的奖励功能和为最大化奖励功能而优化的对话策略。与手工设计的奖励功能相比,这种反向学习的奖励功能可以导致更好的对话政策。
自然语言生成模块Natural Language Generation (NLG)
自然语言生成(NLG)负责将对话管理器选择的通信目标转换为自然语言形式。
最常见的方法还是基于模板或规则。
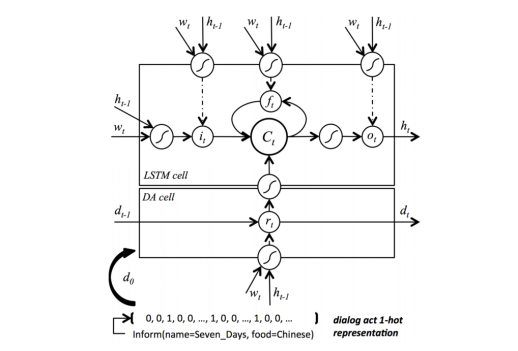
上述模型为SC-LSTM,相较于传统的LSTM,SC-LSTM中引入的额外组件是读取门rt,用于计算从原始对话行为d 0开始的对话行为序列{d t}。这个序列是为了确保生成的话语表示预期的意思,而读取门是为了控制为以后的步骤保留什么信息。在这个意义上,gate r t发挥了句子规划的作用。

输出分布:

其他
微软小冰框架

常用评价指标

神经网络


