本篇文章纪念自己大二python课设做的一个小作品,虽然作业提交完,但还是想写篇博客纪念自己这段时间的努力,不积跬步无以至千里,每天有进步就是成功!
我的小作品以GUI界面为基础,但我并不是用qt进行创建,我使用的是tkinter,放出一些图片:
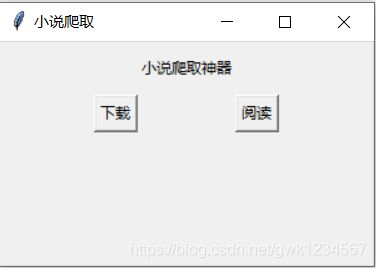
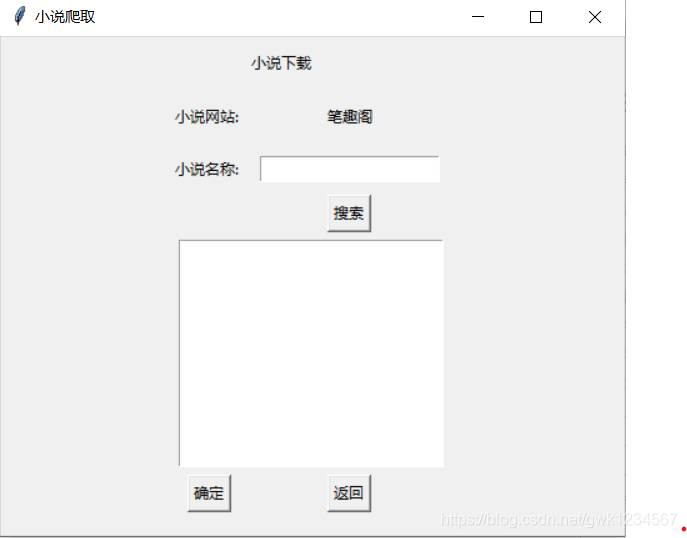
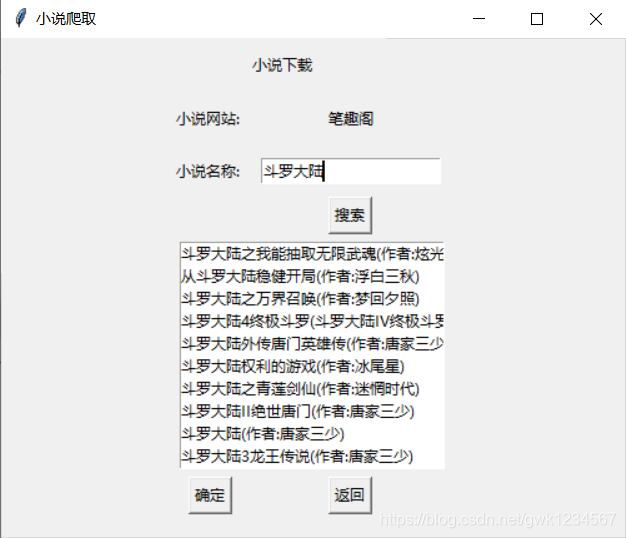
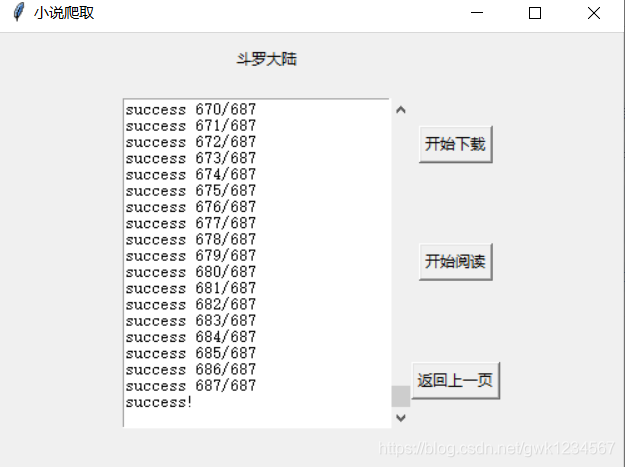
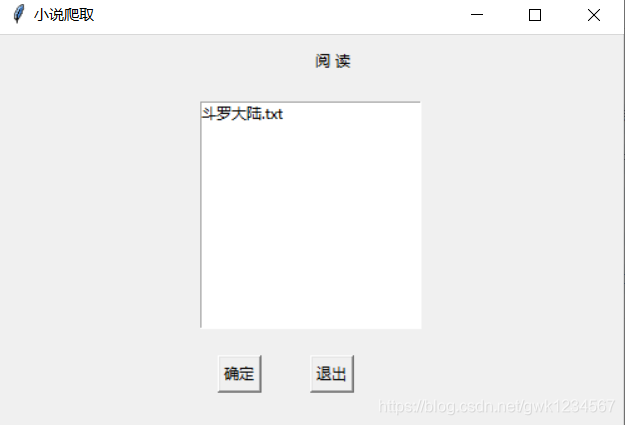
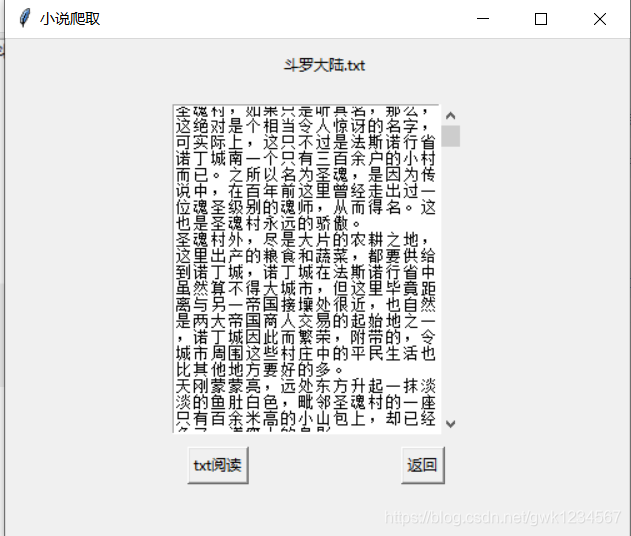
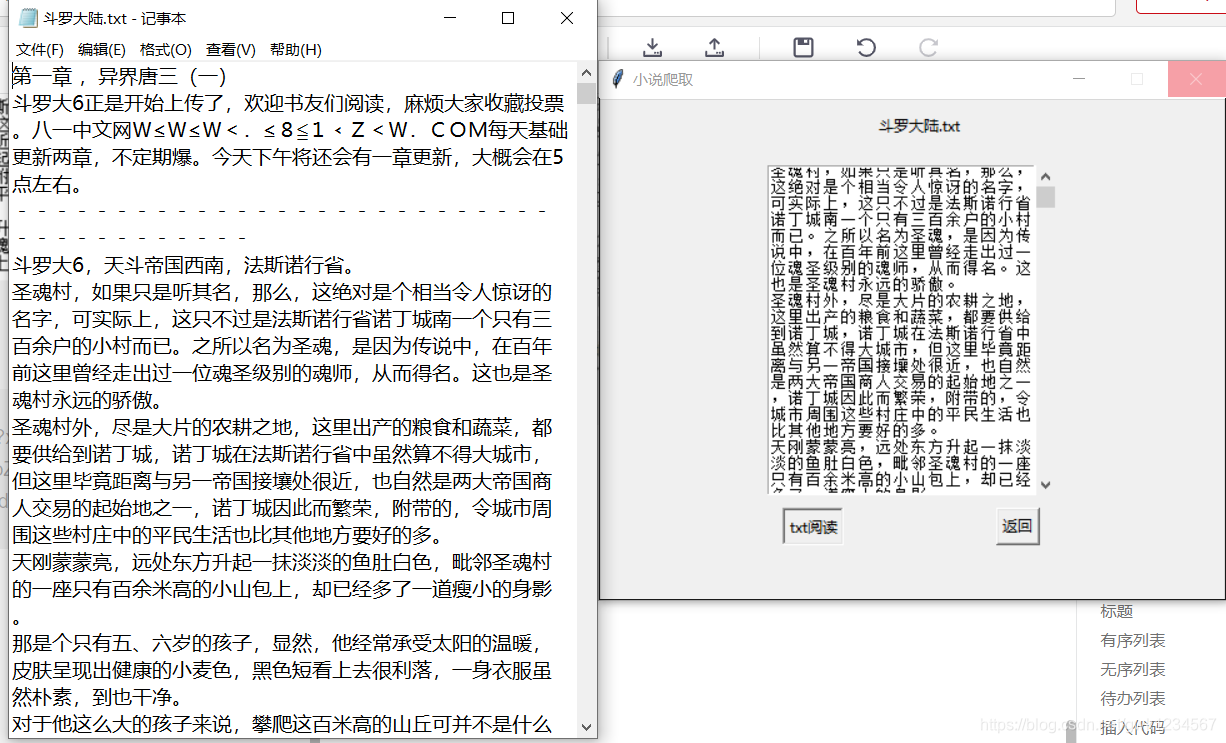
以上就是我做的小作品的主要功能界面,我连接的谷歌浏览器,同时我爬取的小说网站是笔趣阁,这应该是很多人爬取小说都会选择的网站,很适合练手,同时我用的是多线程的爬取,我程序中设置的是20个进程,根据网站的html获得小说相应的地址,使用字典将小说每个章节的内容保存作为值,每一章用相应的数字作为键(下载是没有顺序的),之后按顺序提取出内容。下面放代码:
这是main.py
from tkinter import *
from model import *
window = Tk()
window.title("小说爬取")
Login(window)
window.mainloop()
model.py
from tkinter import *
from tkinter import END
from tkinter import scrolledtext
import tkinter as tk
import tkinter.messagebox
from collections import OrderedDict
from selenium import webdriver,common
import requests,os
import threadpool
from bs4 import BeautifulSoup
from lxml import etree
import time
import threading
class Login(object):
def __init__(self,master = None):
self.window = master
self.window.geometry('%dx%d'%(300,180))
self.create()
def create(self):
self.page = Frame(self.window)
self.page.pack()
Label(self.page,text = "小说爬取神器").grid(row = 0,column = 2,pady = 10)
Button(self.page,text = "下载",command = self.downloand).grid(row = 2,column = 1)
Button(self.page,text = "阅读",command = self.scan).grid(row = 2,column = 3)
def downloand(self):
self.page.pack_forget()
Model(self.window)
def scan(self):
self.page.pack_forget()
Read(self.window)
class Model(object):
def __init__(self,master = None):
self.window = master
self.window.geometry("%dx%d"%(500,400))
self.name = StringVar()#小说名称
self.x = StringVar()#列表选择
self.novelName = []
self.novelAuthor = []
self.location = []
self.position = -1
self.create()
def create(self):
self.page = Frame(self.window)
self.page.pack()
option = webdriver.ChromeOptions()
option.add_argument('headless')
self.driver = webdriver.Chrome(chrome_options = option) # 浏览器静默态
Label(self.page,text = "小说下载").grid(row = 0,column = 1,pady = 10,stick = W)
Label(self.page,text = "小说网站: ").grid(row = 1,column = 0,stick = W)
Label(self.page, text="笔趣阁").grid(row=1, column=1, padx=10, pady=10)
Label(self.page, text="小说名称: ").grid(row=2, column=0, stick = W)
Entry(self.page,textvariable = self.name).grid(row = 2,column = 1,padx=10, pady=10)
Button(self.page,text = "搜索",command = self.search).grid(row = 3,column = 1)
Button(self.page, text="确定", command=self.sure).grid(row = 6, column = 0)
Button(self.page, text="返回", command=self.back).grid(row = 6, column = 1)
self.lt = Listbox(self.page, width=30, height=10, listvariable=self.x,
exportselection=False)
self.lt.grid(row = 4,column =0,columnspan = 3,pady = 5)
self.lt.bind("<<ListboxSelect>>",self.select)
def select(self,*args):
for i,item in enumerate(self.novelName):
if item == self.lt.get(self.lt.curselection()):
self.position = i
break
def search(self):
self.novelName = []
self.novelAuthor = []
self.location = []
self.driver.get("https://www.biquge.com.cn/")
self.driver.find_element_by_xpath("//*[@id='keyword']").send_keys(self.name.get())
self.driver.find_element_by_xpath("//span[@class='s_btn']").click()
self.pagesize = self.driver.find_element_by_xpath('//div[@class="search-result-page-main"]/a[last()]')
if self.pagesize.text=="末页":
self.pagesize = self.driver.find_element_by_xpath('//div[@class="search-result-page-main"]/a[last()-1]')
self.s = self.driver.find_elements_by_xpath('//a[@cpos="title"]')
self.y = self.driver.find_elements_by_xpath('//a[@cpos="title"]/span')
self.z = self.driver.find_elements_by_xpath('//div[@class="result-game-item-info"]/p[1]/span[last()]')
for i in self.s:
self.location.append(i.get_attribute('href'))
for i in self.y:
self.novelName.append(i.text)
for i in self.z:
self.novelAuthor.append(i.text)
if self.pagesize.text != "1":
for i in range(2,eval(self.pagesize.text)+1):
self.driver.get("https://www.biquge.com.cn/search.php?q="+str(self.name.get())+"&p="+str(i))
self.s = self.driver.find_elements_by_xpath(
'//a[@cpos="title"]')
self.y = self.driver.find_elements_by_xpath(
'//a[@cpos="title"]/span')
self.z = self.driver.find_elements_by_xpath(
'//div[@class="result-game-item-info"]/p[1]/span[last()]')
for i in self.y:
self.novelName.append(i.text)
for i in self.z:
self.novelAuthor.append(i.text)
for i in self.s:
self.location.append(i.get_attribute('href'))
if len(self.novelName)>=20:
break
l = len(self.novelName)
for i in range(0,l):
self.novelName[i] = self.novelName[i]+"("+"作者:"+self.novelAuthor[i]+")"
self.x.set(tuple(self.novelName))
def sure(self):
self.page.pack_forget()
self.tar = self.location[self.position]
self.driver.get(self.location[self.position])
DownLoad(self.window,self.driver,self.tar)
def back(self):
self.page.pack_forget()
self.driver.quit()
Login(self.window)
class Read(object):
def __init__(self,master = None):
self.window = master
self.window.geometry("%dx%d"%(500,400))
self.directary = StringVar()#下载完成的书的目录
self.website = None
self.d = []
self.create()
def create(self):
self.page = Frame(self.window)
self.page.pack()
Label(self.page,text = "阅 读").grid(row = 0,column = 1,pady = 10,padx = 10)
self.box = Listbox(self.page,listvariable = self.directary,width = 25,height = 10,exportselection=False)
self.box.grid(row = 1,column = 0,columnspan = 3,pady = 10)
self.box.bind("<<ListboxSelect>>",self.k)
Button(self.page,text = "确定",command = self.s).grid(row = 2,column = 0,pady = 10)
Button(self.page,text = "退出",command = self.b).grid(row = 2,column = 1,pady = 10)
for dir in os.walk("books"):
self.directary.set(tuple(dir[2]))
def k(self,*args):
self.website = self.box.get(self.box.curselection())
def s(self):
self.page.pack_forget()
means(self.window,self.website)
def b(self):
self.page.pack_forget()
Login(self.window)
class means(object):
def __init__(self,master = None,name = None):
self.window = master
self.window.geometry("%dx%d"%(500,400))
self.name = name
self.create()
def create(self):
self.page = Frame(self.window)
self.page.pack()
Label(self.page,text = self.name).grid(row = 0,column = 1,pady = 10)
self.show = scrolledtext.ScrolledText(self.page,width = 30,height = 20)
self.show.grid(row = 1,column = 0,pady = 10,rowspan = 3,columnspan = 3)
Button(self.page, text="txt阅读", command=self.readtxt).grid(row = 4, column = 0)
Button(self.page, text="返回", command=self.back).grid(row = 4, column = 2)
f = open("books/"+str(self.name),"r",encoding = "utf-8")
s = f.read()
self.show.insert(END,s)
def readtxt(self):
os.system(r"notepad books/"+str(self.name))
def back(self):
self.page.pack_forget()
Read(self.window)
class DownLoad(object):
def __init__(self,master = None,driver = None,tar = None):
self.window = master
self.driver = driver
self.tar = tar
self.window.geometry("%dx%d" % (500, 500))
self.speed = StringVar()
self.novel =dict()
self.location = []#章节链接
self.locations = []
self.nums = 0#章节数目
self.boname = []#存章节名
self.target = self.tar
self.already = 0
self.server = "https://www.biquge.com.cn"
self.create()
def create(self):
self.page = Frame(self.window)
self.page.pack()
self.name = self.driver.find_element_by_xpath('//div[@id="info"]/h1')
Label(self.page,text = self.name.text).grid(row = 0,column = 0,pady = 10)
self.t = scrolledtext.ScrolledText(self.page,height = 20,width = 30)
self.t.grid(row = 1,column = 0,pady =10,rowspan = 3)
Button(self.page, text="开始下载", command=self.craw).grid(row=1, column=1)
Button(self.page, text="开始阅读", command=self.scan).grid(row=2, column=1)
Button(self.page, text="返回上一页", command=self.back).grid(row=3, column=1)
def craw(self):
self.req = requests.get(url=self.target)
self.req.encoding = 'utf-8'
self.html = self.req.text
self.div_bf = BeautifulSoup(self.html,'lxml')
self.div = self.div_bf.find_all('div',id = 'list')
self.a_bf = BeautifulSoup(str(self.div[0]),'lxml')
self.a = self.a_bf.find_all('a')
self.nums = len(self.a)
for i in self.a:
self.boname.append(i.string)
self.location.append(self.server+i.get('href'))
for i in range(len(self.location)):
self.locations.append([i,self.location[i]])
for i in self.locations:
pool = threading.Thread(target=self.download,args=(i,))
pool.setDaemon(True)
pool.start()
def download(self,a):
req= requests.get(a[1])
contents = []
html = etree.HTML(req.text)
title = html.xpath('//div[@class="bookname"]/h1/text()')[0]
o = title+'\n'
content = html.xpath('//div[@id="content"]/text()')
for i in content:
contents.append(i)
for i in contents:
i="".join(i.split())
o = o + i + '\n'
self.novel[str(a[0])] = o
self.already += 1
self.t.insert(END,"success "+str(self.already)+"/"+str(self.nums)+"\n")
if self.already == self.nums:
self.t.insert(END, "success! " + "\n")
time.sleep(0.001)
def scan(self):
if not os.path.exists("books/" + str(self.name.text) + '.txt'):
with open('books/' + self.name.text + '.txt', 'w',
encoding='utf-8') as f:
for i in range(self.nums):
f.write(self.novel[str(i)])
else:
tk.messagebox.showinfo('提示','此小说已下载')
self.page.pack_forget()
self.driver.quit()
Read(self.window)
def back(self):
self.page.pack_forget()
self.driver.quit()
Model(self.window)
以上就是小作品的全部代码,感兴趣的伙伴可以去试试,代码没有过于难懂的,有问题也希望大家提出,共同进步。