Pytorch神经网络基础
Tensor
tensor称为张量,Torch能够将torch中的tensor放到GPU中加速运算。
import torch
import numpy as np
data = [1, 2, 3, 4]
tensor1 = torch.LongTensor(data) #list---> tensor
np_data1 = tensor1.numpy() #tensor ---> array
np_data2 = np.array(data) #list ---> array
tensor2 = torch.from_numpy(np_data1) #array---> tensor
Variable
神经网络用到的数据类型是Variable,所以Variable相当于一个篮子,要用Variable把tensor装起来才行。
import torch
from torch.autograd import Variable
tensor = torch.FloatTensor([[1,2], [3, 4]])
x = Variable(tensor, requires_grad=True) #tensor要转变成Variable的形式才能加入到神经网络中
v_out = torch.mean(x*x)
v_out.backward()
print(x.grad)
Activation Function
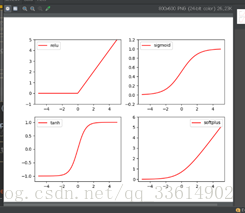
激励函数有很多中,最常用的几种为relu,sigmoid,tanh,softplus,softmax。卷积神经网络中常用relu,循环神经网络中常用tanh、relu。softmax不能直接画出来,关于概率用于分类。
import numpy as np
import torch
import torch.nn.functional as F #神经网络中的激励函数都在这
from torch.autograd import Variable #torch中运算的基本神经元是Variable
x = torch.linspace(-5,5,200) #x data(tensor),从-5到5之间200个数据,(200,1)
#print(x)
x = Variable(x)
x_np = x.data.numpy() #转换成numpy,画图的时候用
# relu, sigmoid, tanh, softplus
y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).data.numpy()
y_tanh = F.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
#softmax比较特殊,不能直接显示,不过它是关于概率的,用于分类
建造神经网络
1、 数据集及数据预处理
2、 搭建合适的神经网络
3、 训练
net = Net() #建造神经网络
opt = torch.optim.XXX(net.parameters(), lr=X) #选择合适的优化器,如随机梯度下降SGD
loss_func = torch.nn.XXX() #选择合适的损失函数,如MSELoss
for epoch in range(EPOCH):
prediction =net.forward(x)
loss =loss_func(prediction, y)
opt.zero_grad()
loss.backward()
opt.step()
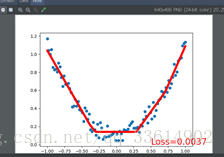
拟合回归问题
这里我们构建一个3层神经网络:输入输出层各1各神经元,隐藏层10个神经元
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
import torch.nn as nn
#建立数据集
x =torch.unsqueeze(torch.linspace(-1,1,100), dim=1)
# x = torch.linspace(-1, 1, 100)
# x = torch.unsqueeze(x, dim=1) #x data (tensor),shape = (100,1) torch中只能存二维的数据,将一维变为二维
y= x.pow(2) + 0.2 * torch.rand(x.size())#noisy y data(tensor),shape=(100,1)
x, y =Variable(x), Variable(y)
#画图
#plt.scatter(x.data.numpy(), y.data.numpy())
#plt.show()
#搭建神经网络
import torch.nn.functional as F
# class Net(torch.nn.Module):
# def __init__(self, n_feature, n_hidden, n_output):
# super(Net, self).__init__() #继承__init__的功能
# self.hidden = torch.nn.Linear(n_feature, n_hidden)
# self.predict = torch.nn.Linear(n_hidden, n_output)
#
# def forward(self, x):
# x = F.relu(self.hidden(x)) #激励函数(隐藏层中的线性输出)
# x = self.predict(x) #为什么能这样调用上面定义的函数呢???
# return x
net = torch.nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 1)
)
# net =Net(n_feature=1,n_hidden=10,n_output=1)
print(net)
#训练神经网络,optimizer是训练工具
opt = torch.optim.SGD(net.parameters(),lr=0.5)
loss_func = torch.nn.MSELoss()
for t in range(1000):
predition = net(x)
loss = loss_func(predition, y)
opt.zero_grad()
loss.backward()
opt.step()
保存与提取已经训练好的神经网络
保存
# 搭建net1的神经网络结构
net1 = torch.nn.Sequential(nn.Linear(1, 10), nn.ReLU(), nn.Linear(10, 1))
#训练net1
…
…
…
l 方法1
torch.save(net1, ‘test.pkl’) #保存整个神经网络net1为test.pkl
l 方法2
torch.save(net1.state_dict(), 'test_state.pkl') #仅保存网络中的参数
提取
l 方法1
net2 = torch.load(‘test.pkl’) #提取整个神经网络
l 方法2
# 先构建整个网络架构,再加载参数
# 先搭建net3的神经网络结构,使其与需要提取的结构(net1)一致。
net3 = torch.nn.Sequential(nn.Linear(1, 10), nn.ReLU(), nn.Linear(10, 1))
net3.load_state_dict(torch.load(‘test.pkl’))
批训练
批训练需要先将数据转换成Data.TensorDataset形式,再封装到Data.DataLoader中
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10) # tensor
torch_data =Data.TensorDataset(data_tensor=x, target_tensor=y)
loader = Data.DataLoader(
dataset=torch_data,
batch_size=BATCH_SIZE, #每批次的数据量
shuffle=True, #是否打乱数据
num_workers=2 #多线程读数据
)
for epoch in range(3):
for step,(batch_x, batch_y) in enumerate(loader):
print('\n\n\n\nepoch:', epoch, 'step:', step, 'batch_x',batch_x.numpy(),'batch_y', batch_y.numpy())
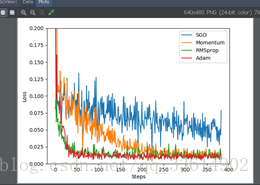
Optimizer优化器
分别测试以下优化器的训练效果:SGD,Momentum,RMSProp,Adam
代码就不粘了,数据和结果如下:
高级神经网络结构
CNN
image à convolution à max pooling à convolution àmax pooling à fully connected à fully connected à classifier(图片 卷积 池化卷积 池化 全连接 全连接 分类器)。
卷积是提取边缘图片信息,池化是从边缘信息中提取出更高层的信息结构,最后通过全连接层进行分类。
这里我们用到的数据集为NMIST,目标是正确识别手写数字。
CNN网络结构
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # (1*28*28)
nn.Conv2d(
in_channels=1, #黑白图片所以为1
out_channels=16, #卷积是用到的过滤器的高度,为16
kernel_size=5, #每次采样的长和宽,5*5
stride=1, #每次移动的步长,1*1
padding=2 #提取到图片与原图大小一致,图片周围的填充,(kernel_size-1)/2
), # (16*28*28)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # (16*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=5,
stride=1,
padding=2
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # (32*7*7)
)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
return self.out(x), x
训练
# training
cnn = CNN()
opt = torch.optim.Adam(cnn.parameters(),lr=LR) #选择Adam优化器
loss_func = torch.nn.CrossEntropyLoss() #选择交叉熵损失函数
for epoch in range(EPOCH):
for step, (batch_x, batch_y) in enumerate(train_loader):
x, y = Variable(batch_x), Variable(batch_y)
prediction = cnn(x)[0]
loss = loss_func(prediction, y)
opt.zero_grad()
loss.backward()
opt.step()
RNN分类
数据预处理
使用MNIST数据集
import torch
import torchvision
from torchvision import datasets
from torch.utils import data
train_data = datasets.MNIST(root='./mnist/',train=True, transform=torchvision.transforms.ToTensor())
train_loader = data.DataLoader(train_data,BATCH_SIZE, True)
test_data = datasets.MNIST('./mnist',False, torchvision.transforms.ToTensor())
test_x = Variable(test_data.test_data,volatile=True).type(torch.FloatTensor)[:2000]/255
test_y =test_data.test_labels.numpy().squeeze()[:2000]
搭建RNN
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # if use nn.RNN(), ithardly learns
input_size=INPUT_SIZE,
hidden_size=64, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True, # input &output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10)
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step,output_size)
# h_n shape (n_layers, batch, hidden_size)
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None represents zero initial hidden state,h_n为主线、h_c为分线
# choose r_out at the last time step
out = self.out(r_out[:, -1, :])
return out
训练
optimizer = torch.optim.Adam(rnn.parameters(),lr=LR)
loss_func = nn.CrossEntropyLoss()
# training and testing
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader): # gives batch data
b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step,input_size)
b_y = Variable(y) # batch y
output = rnn(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # cleargradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step()