起步


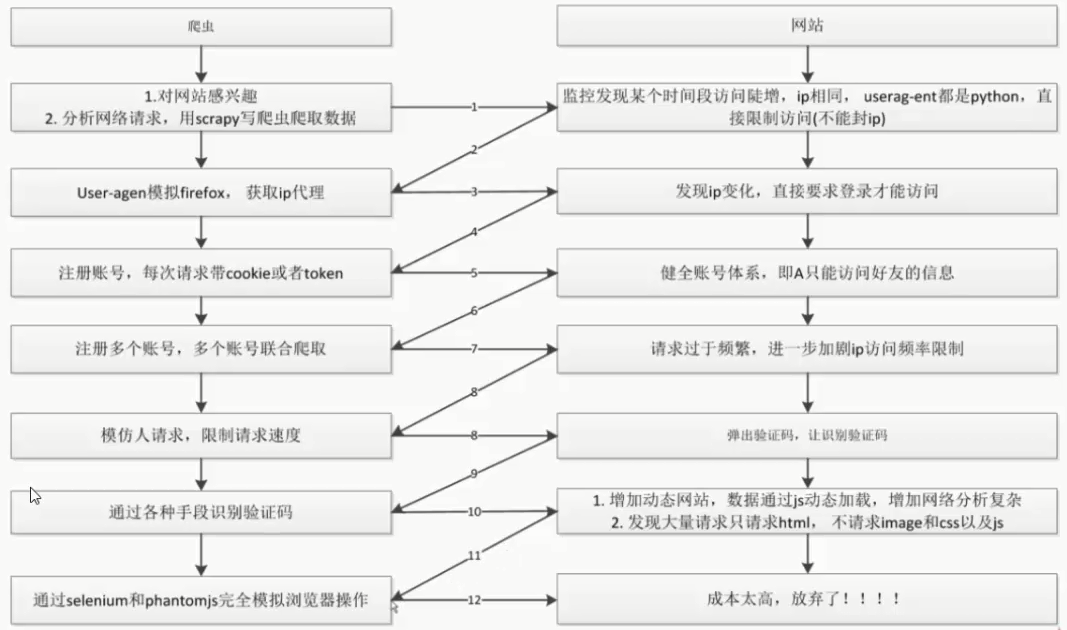
对抗过程
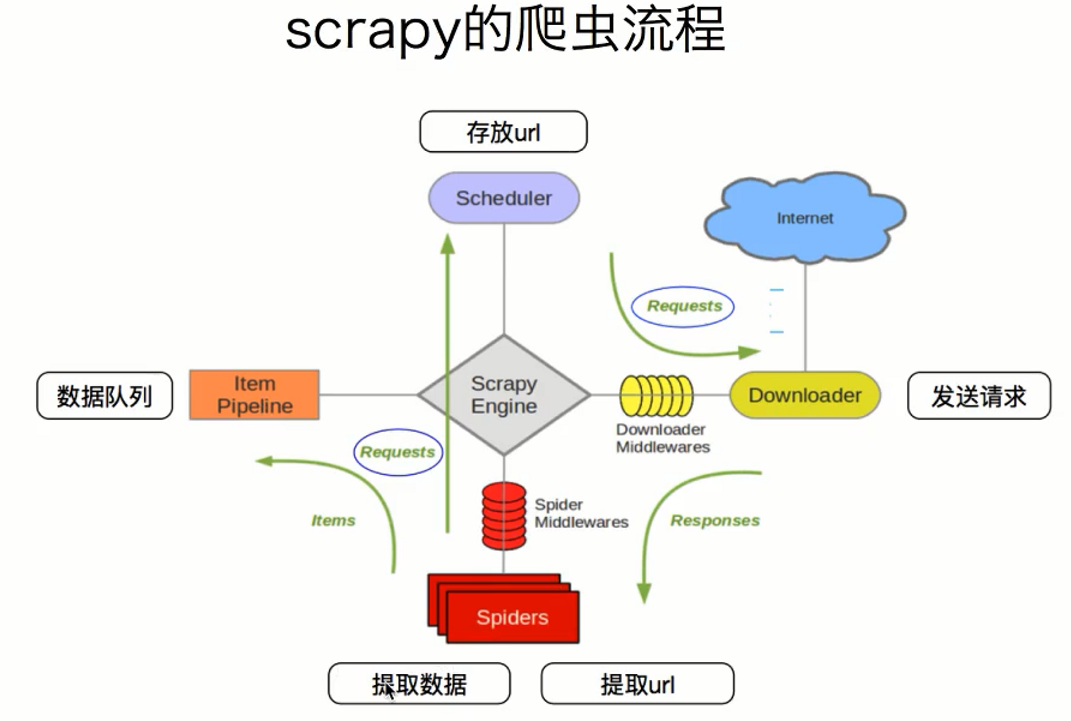
scrapy架构


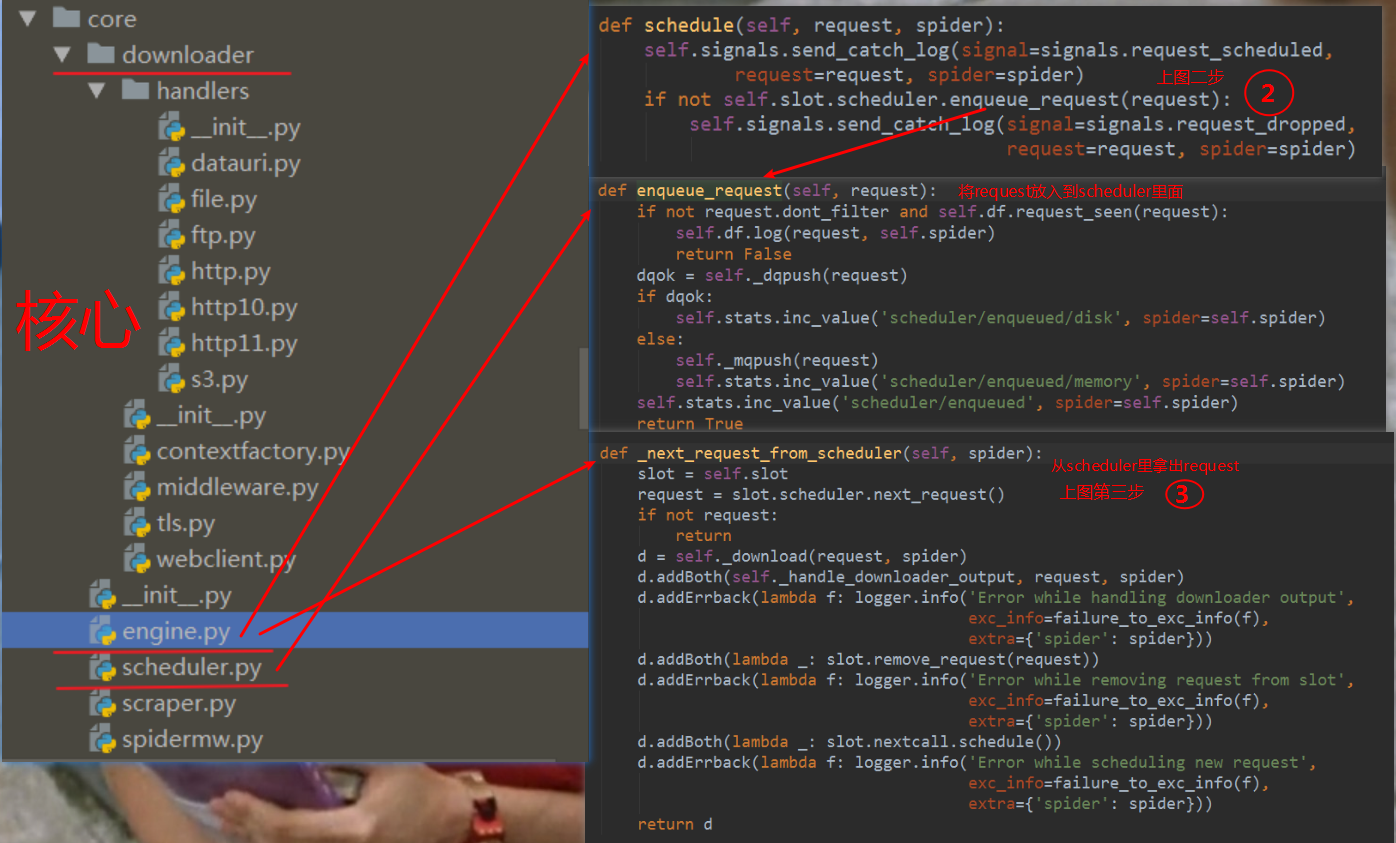
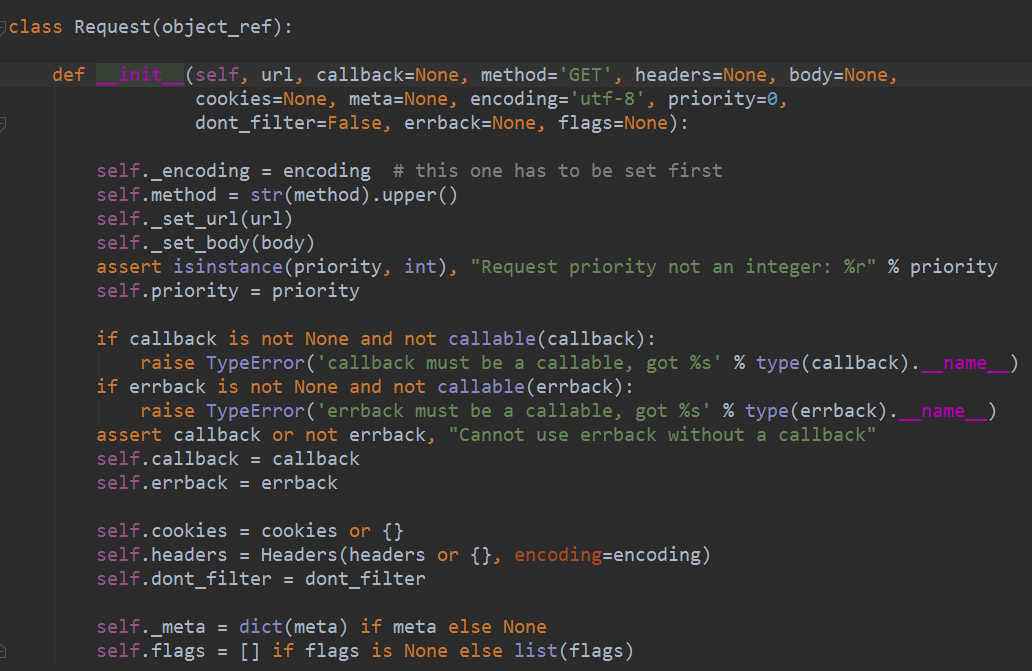
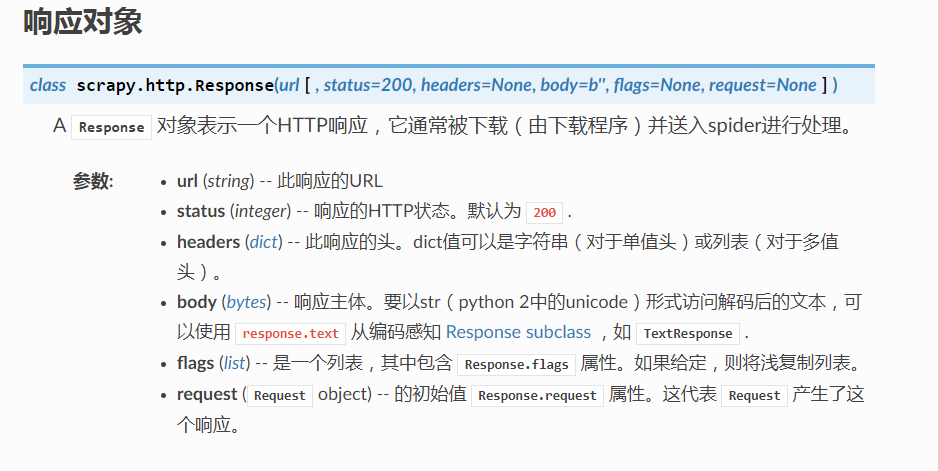
request 与 response

随机更换user-agent
middlewares.py
from fake_useragent import UserAgent
ua = UserAgent()
class RandomUserAgentMiddLware(object):
# user-agent 随机切换
def __init__(self,crawler):
super(RandomUserAgentMiddLware,self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE","random")
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault('User-Agent',get_ua())
settings.py
DOWNLOADER_MIDDLEWARES = {
'PictureSpider.middlewares.RandomUserAgentMiddLware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RANDOM_UA_TYPE = "random"
使用ip代理
原理:
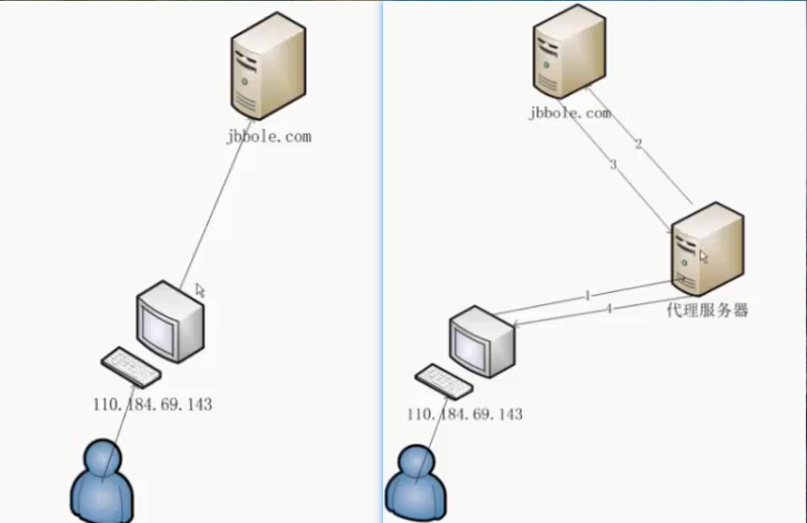
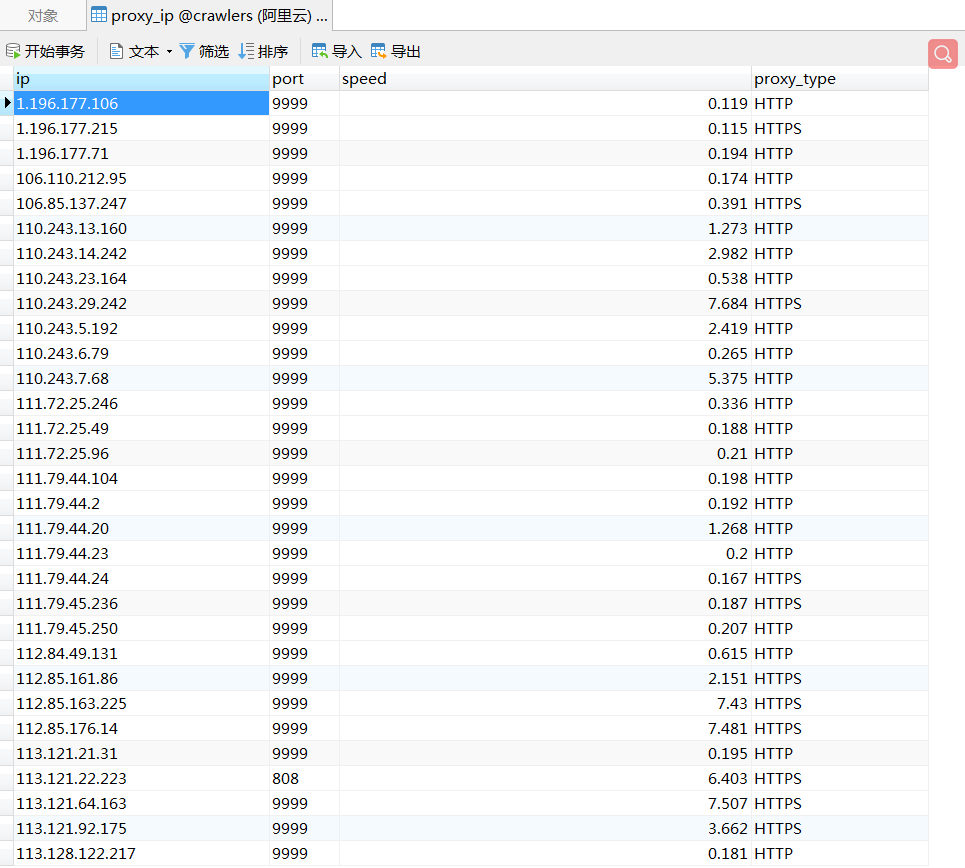
方式一:爬取西刺,组建免费ip代理池:
西刺页面
xic_ip.py
import requests
from scrapy.selector import Selector
import pymysql
conn = pymysql.connect(host="xxxxxxxx", port=3306, user="xxxxxx", password="xxxxxxx", db="xxxxxxx", charset="utf8")
cursor = conn.cursor()
def crawl_ips():
# 爬取西刺的免费ip代理
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"}
for i in range(1568):
re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers)
selector = Selector(text=re.text)
all_trs = selector.css("#ip_list tr")
ip_list = []
for tr in all_trs[1:]:
speed_str = tr.css(".bar::attr(title)").extract()[0]
if speed_str:
speed = float(speed_str.split("秒")[0])
all_texts = tr.css("td::text").extract()
ip = all_texts[0]
port = all_texts[1]
proxy_type = all_texts[5]
ip_list.append((ip, port, proxy_type, speed))
for ip_info in ip_list:
cursor.execute(
"insert proxy_ip(ip, port, speed, proxy_type) VALUES('{0}', '{1}',{2},'{3}')".format(
ip_info[0], ip_info[1], ip_info[3], ip_info[2]
)
)
conn.commit()
class GetIP(object):
def delete_ip(self, ip):
# 从数据库中删除无效的ip
delete_sql = """
delete from proxy_ip where ip='{0}'
""".format(ip)
cursor.execute(delete_sql)
conn.commit()
return True
def judge_ip(self, ip, port):
# 判断ip是否可用
http_url = "http://www.baidu.com"
proxy_url = "http://{0}:{1}".format(ip, port)
try:
proxy_dict = {
"http": proxy_url,
}
response = requests.get(http_url, proxies=proxy_dict)
except Exception as e:
print("invalid ip and port")
self.delete_ip(ip)
return False
else:
code = response.status_code
if code >= 200 and code < 300:
print("effective ip")
return True
else:
print("invalid ip and port")
self.delete_ip(ip)
return False
def get_random_ip(self):
# 从数据库中随机获取一个可用的ip
random_sql = """
SELECT ip, port FROM proxy_ip
ORDER BY RAND()
LIMIT 1
"""
result = cursor.execute(random_sql)
for ip_info in cursor.fetchall():
ip = ip_info[0]
port = ip_info[1]
judge_re = self.judge_ip(ip, port)
if judge_re:
return "http://{0}:{1}".format(ip, port)
else:
return self.get_random_ip()
缺点:不稳定,速度较慢
中间件设置,使用从数据库随机获得的ip:
from tools.xic_ip import GetIP
class RandomProxyMiddleware(object):
#动态设置ip代理
def process_request(self, request, spider):
get_ip = GetIP()
request.meta["proxy"] = get_ip.get_random_ip()
可以利用scrapy-proxies加以改造:

缺点:它从文件中读取,不如数据库方便
方式二:使用scrapy-crawla(收费,需注册账号):
方式三:利用YC
方式四:限制爬虫的访问速度,保护好自己的源ip
验证码识别
云打码的使用
其他手段
对于不需要登录就能爬取的网页,禁用cookies
COOKIES_ENABLED = False
配置scrapy自带的扩展限制爬虫速度:

不同的项目配置不同的settings:
custom_settings = {
"COOKIES_ENABLED": True
}
